PRDP: Proximal Reward Difference Prediction for Large-Scale Reward Finetuning of Diffusion Models
{kind=link}
Abstract
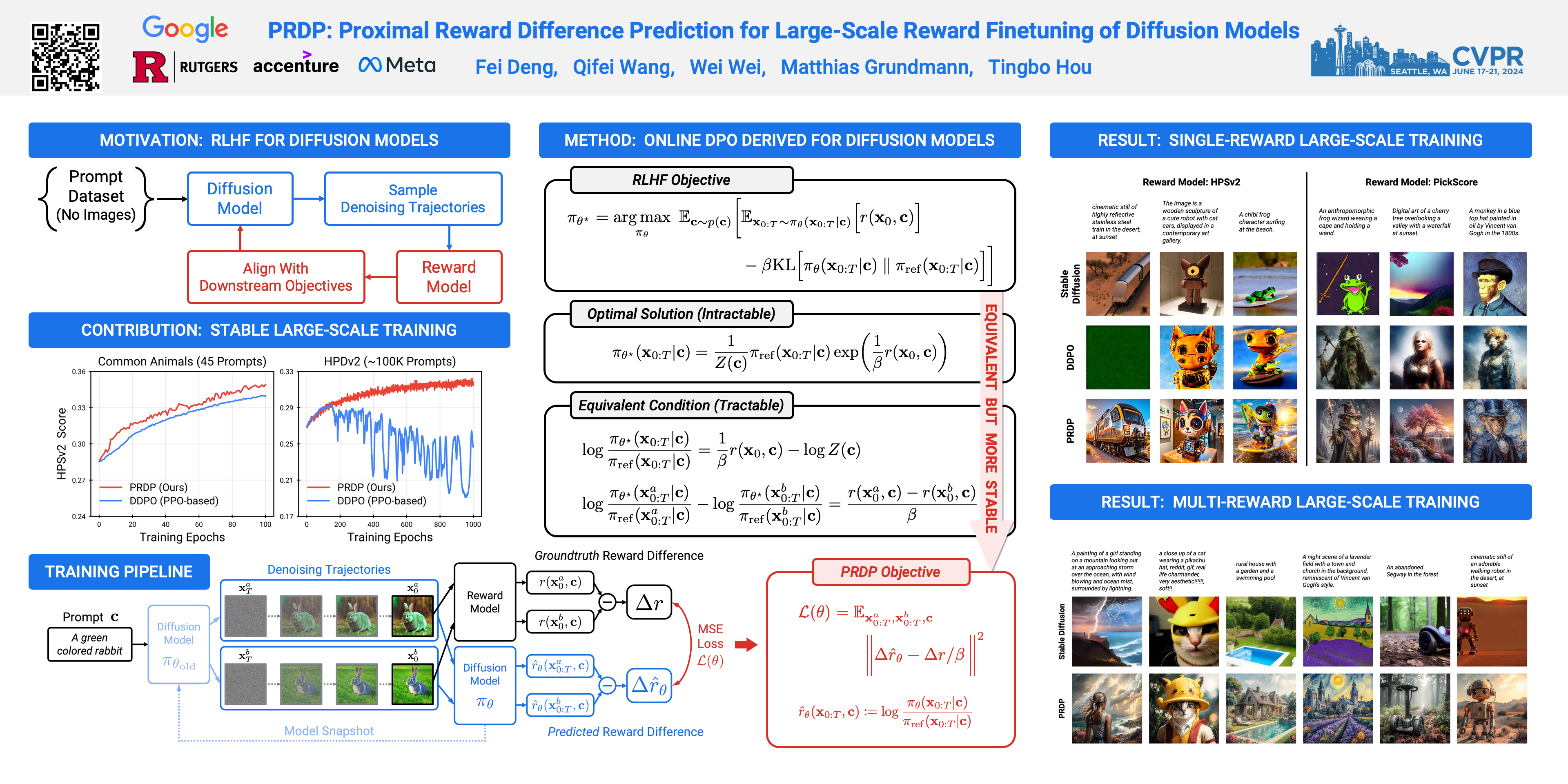
Reward finetuning has emerged as a promising approach to aligning foundation models with downstream objectives. Remarkable success has been achieved in the language domain by using reinforcement learning (RL) to maximize rewards that reflect human preference. However, in the vision domain, existing RL-based reward finetuning methods are limited by their instability in large-scale training, rendering them incapable of generalizing to complex, unseen prompts. In this paper, we propose Proximal Reward Difference Prediction (PRDP), enabling stable black-box reward finetuning for diffusion models for the first time on large-scale prompt datasets with over 100K prompts. Our key innovation is the Reward Difference Prediction (RDP) objective that has the same optimal solution as the RL objective while enjoying better training stability. Specifically, the RDP objective is a supervised regression objective that tasks the diffusion model with predicting the reward difference of generated image pairs from their denoising trajectories. We theoretically prove that the diffusion model that obtains perfect reward difference prediction is exactly the maximizer of the RL objective. We further develop an online algorithm with proximal updates to stably optimize the RDP objective. In experiments, we demonstrate that PRDP can match the reward maximization ability of well-established RL-based methods in small-scale training. Furthermore, through large-scale training on text prompts from the Human Preference Dataset v2 and the Pick-a-Pic v1 dataset, PRDP achieves superior generation quality on a diverse set of complex, unseen prompts whereas RL-based methods completely fail.