Prompt-Driven Referring Image Segmentation with Instance Contrasting
{kind=link}
Abstract
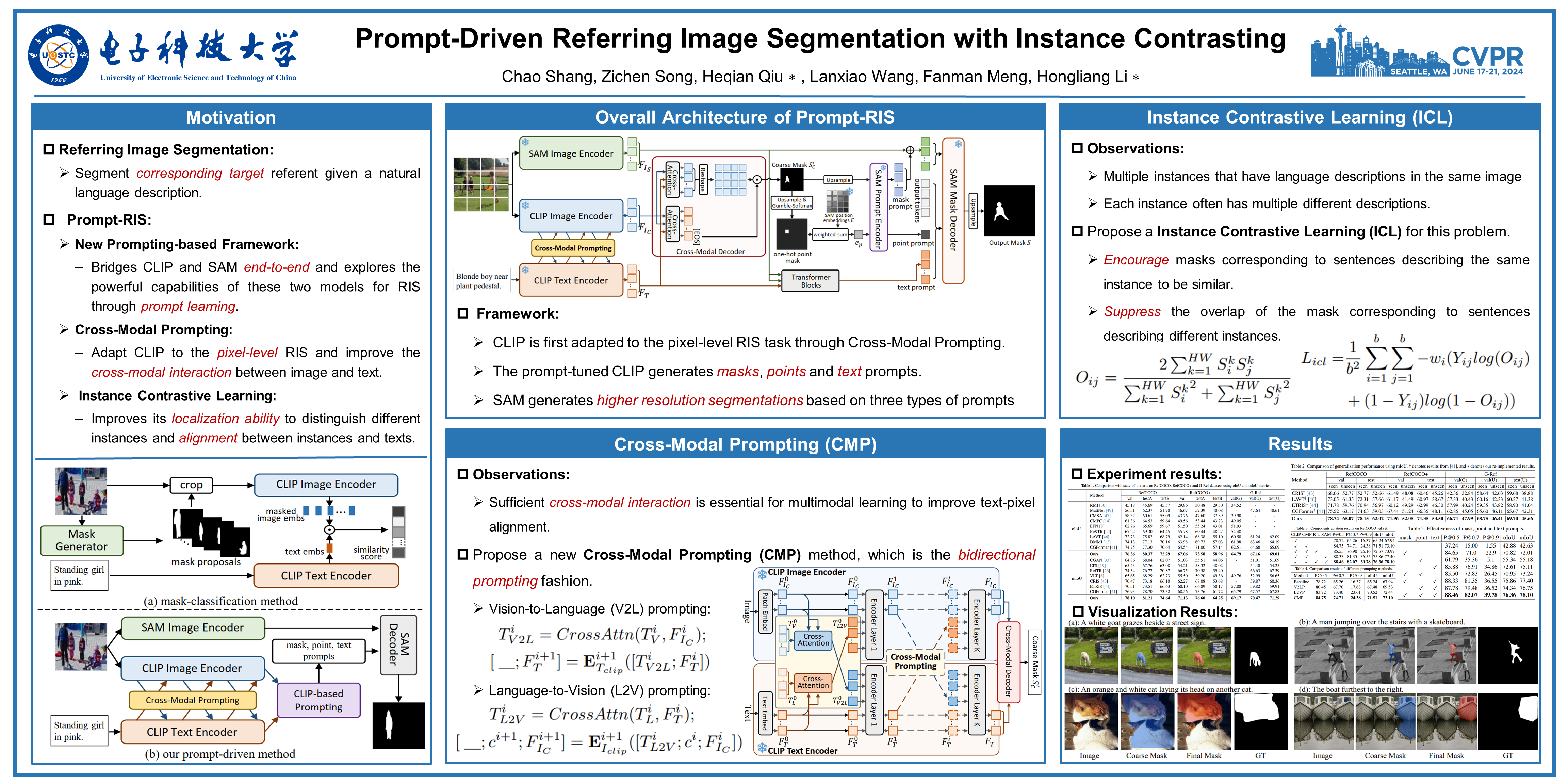
Referring image segmentation (RIS) aims to segment the target referent described by natural language. Recently, large-scale pre-trained models, e.g., CLIP and SAM, have been successfully applied in many downstream tasks, but they are not well adapted to RIS task due to inter-task differences. In this paper, we propose a new prompt-driven framework named Prompt-RIS, which bridges CLIP and SAM end-to-end and transfers their rich knowledge and powerful capabilities to RIS task through prompt learning. To adapt CLIP to pixel-level task, we first propose a Cross-Modal Prompting method, which acquires more comprehensive vision-language interaction and fine-grained text-to-pixel alignment by performing bidirectional prompting. Then, the prompt-tuned CLIP generates masks, points, and text prompts for SAM to generate more accurate mask predictions. Moreover, we further propose Instance Contrastive Learning to improve the model's discriminability to different instances and robustness to diverse languages describing the same instance. Extensive experiments demonstrate that the performance of our method outperforms the state-of-the-art methods consistently in both general and open-vocabulary settings.