A Comprehensive Study of Decoder-Only LLMs for Text-to-Image Generation
{kind=link}
Abstract
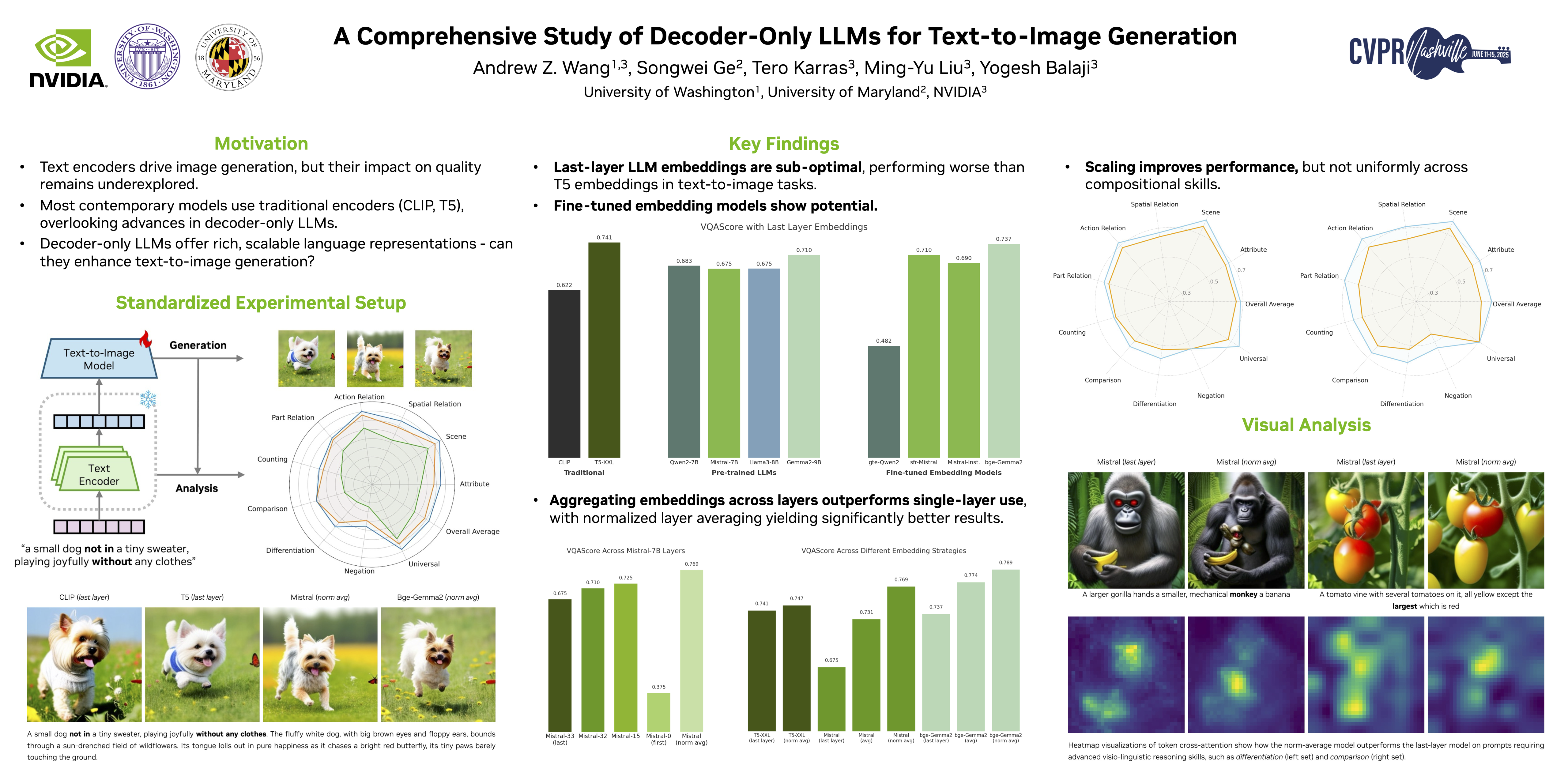
Both text-to-image generation and large language models (LLMs) have made significant advancements. However, many text-to-image models still employ the somewhat outdated T5 and CLIP as their text encoders.In this work, we investigate the effectiveness of using modern decoder-only LLMs as text encoders for text-to-image diffusion models. We build a standardized training and evaluation pipeline that allows us to isolate and evaluate the effect of different text embeddings. We train a total of 22 text-to-image models with 12 different text encoders to analyze the critical aspects of LLMs that could impact text-to-image generation, including the approaches to extract embeddings, different LLMs variants, and model sizes.Our experiments reveal that the de facto way of using last-layer embeddings as conditioning leads to inferior performance.Instead, we explore embeddings from various layers and find that usinglayer-normalized averaging across all layers significantly improves alignment with complex prompts. LLMs with this conditioning outperform the baseline T5 model, showing enhanced performance in advanced visio-linguistic reasoning skills.