|
Highlight
|
Poster
[ ExHall D ] 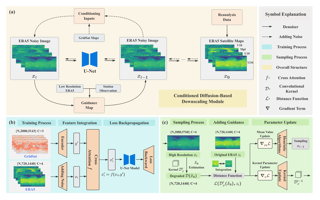
Abstract
Accurate acquisition of surface meteorological conditions at arbitrary locations holds significant importance for weather forecasting and climate simulation. Due to the fact that meteorological states derived from satellite observations are often provided in the form of low-resolution grid fields, the direct application of spatial interpolation to obtain meteorological states for specific locations often results in significant discrepancies when compared to actual observations. Existing downscaling methods for acquiring meteorological state information at higher resolutions commonly overlook the correlation with satellite observations. To bridge the gap, we propose $\textbf{S}$atellite-observations $\textbf{G}$uided $\textbf{D}$iffusion Model ($\textbf{SGD}$), a conditional diffusion model pre-trained on ERA5 reanalysis data with satellite observations (GridSat) as conditions, which is employed for sampling downscaled meteorological states through a zero-shot guided sampling strategy and patch-based methods. During the training process, we propose to fuse the information from GridSat satellite observations into ERA5 maps via the attention mechanism, enabling SGD to generate atmospheric states that align more accurately with actual conditions. In the sampling, we employed optimizable convolutional kernels to simulate the upscale process, thereby generating high-resolution ERA5 maps using low-resolution ERA5 maps as well as observations from weather stations as guidance. Moreover, our devised patch-based method promotes SGD to generate meteorological states at …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Image-to-Video (I2V) generation aims to synthesize a video clip according to a given image and condition (e.g., text). The key challenge of this task lies in simultaneously generating natural motions while preserving the original appearance of the images.However, current I2V diffusion models (I2V-DMs) often produce videos with limited motion degrees or exhibit uncontrollable motion that conflicts with the textual condition. In this paper, we propose a novel Extrapolating and Decoupling framework to mitigate these issues. Specifically, our framework consists of three separate stages:(1) Starting with a base I2V-DM, we explicitly inject the textual condition into the temporal module using a lightweight, learnable adapter and fine-tune the integrated model to improve motion controllability. (2) We introduce a training-free extrapolation strategy to amplify the dynamic range of the motion, effectively reversing the fine-tuning process to enhance the motion degree significantly.(3) With the above two-stage models excelling in motion controllability and motion degree, we decouple the relevant parameters associated with each type of motion ability and inject them into the base I2V-DM. Since the I2V-DM handles different levels of motion controllability and dynamics at various denoising time steps, we adjust the motion-aware parameters accordingly over time. Extensive qualitative and quantitative experiments have been …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
As a fundamental backbone for video generation, diffusion models are challenged by low inference speed due to the sequential nature of denoising.Previous methods speed up the models by caching and reusing model outputs at uniformly selected timesteps.However, such a strategy neglects the fact that differences among model outputs are not uniform across timesteps, which hinders selecting the appropriate model outputs to cache, leading to a poor balance between inference efficiency and visual quality.In this study, we introduce Timestep Embedding Aware Cache (TeaCache), a training-free caching approach that estimates and leverages the fluctuating differences among model outputs across timesteps.Rather than directly using the time-consuming model outputs, TeaCache focuses on model inputs, which have a strong correlation with the modeloutputs while incurring negligible computational cost.TeaCache first modulates the noisy inputs using the timestep embeddings to ensure their differences better approximating those of model outputs. TeaCache then introduces a rescaling strategy to refine the estimated differences and utilizes them to indicate output caching.Experiments show that TeaCache achieves up to 4.41$\times$ acceleration over Open-Sora-Plan with negligible (-0.07\% Vbench score) degradation of visual quality. Code is enclosed in the supplementary material.
|
|
Highlight
|
Poster
[ ExHall D ] 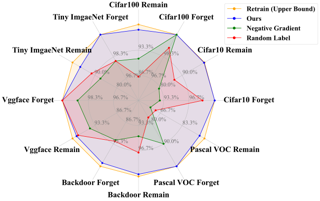
Abstract
In this work, we present DEcoupLEd Distillation To Erase (DELETE), a general and strong unlearning method for any class-centric tasks. To derive this, we first propose a theoretical framework to analyze the general form of unlearning loss and decompose it into forgetting and retention terms. Through the theoretical framework, we point out that a class of previous methods could be mainly formulated as a loss that implicitly optimizes the forgetting term while lacking supervision for the retention term, disturbing the distribution of pre-trained model and struggling to adequately preserve knowledge of the remaining classes.To address it, we refine the retention term using ``dark knowledge” and propose a mask distillation unlearning method. By applying a mask to separate forgetting logits from retention logits, our approach optimizes both the forgetting and refined retention components simultaneously, retaining knowledge of the remaining classes while ensuring thorough forgetting of the target class.Without access to the remaining data or intervention (\ie, used in some works), we achieve state-of-the-art performance across various benchmarks. What's more, DELETE is a general solution that can be applied to various downstream tasks, including face recognition, backdoor defense, and semantic segmentation with great performance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Place recognition is essential to maintain global consistency in large-scale localization systems. While research in urban environments has progressed significantly using LiDARs or cameras, applications in natural forest-like environments remain largely underexplored.Furthermore, forests present particular challenges due to high self-similarity and substantial variations in vegetation growth over time.In this work, we propose a robust LiDAR-based place recognition method for natural forests, ForestLPR. We hypothesize that a set of cross-sectional images of the forest’s geometry at different heights contains the information needed to recognize revisiting a place.The cross-sectional images are represented by bird’s-eye view (BEV) density images of horizontal slices of the point cloud at different heights. Our approach utilizes a visual transformer as the shared backbone to produce sets of local descriptors and introduces a multi-BEV interaction module to attend to information at different heights adaptively. It is followed by an aggregation layer that produces a rotation-invariant place descriptor. We evaluated the efficacy of our method extensively on real-world data from public benchmarks as well as robotic datasets and compared it against the state-of-the-art (SOTA) methods. The results indicate that ForestLPR has consistently good performance on all evaluations and achieves an average increase of 7.38\% and 9.11\% on Recall@1 over …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Monocular depth estimation (MDE) models have undergone significant advancements over recent years. Many MDE models aim to predict affine-invariant relative depth from monocular images, while recent developments in large-scale training and vision foundation models enable reasonable estimation of metric (absolute) depth. However, effectively leveraging these predictions for geometric vision tasks, in particular relative pose estimation, remains relatively under explored. While depths provide rich constraints for cross-view image alignment, the intrinsic noise and ambiguity from the monocular depth priors present practical challenges to improving upon classic keypoint-based solutions. In this paper, we develop three solvers for relative pose estimation that explicitly account for independent affine (scale and shift) ambiguities, covering both calibrated and uncalibrated conditions. We further propose a hybrid estimation pipeline that combines our proposed solvers with classic point-based solvers and epipolar constraints. We find that the affine correction modeling is beneficial to not only the relative depth priors but also, surprisingly, the "metric" ones. Results across multiple datasets demonstrate large improvements of our approach over classic keypoint-based baselines and PnP-based solutions, under both calibrated and uncalibrated setups. We also show that our method improves consistently with different feature matchers and MDE models, and can further benefit from very recent …
|
|
Highlight
|
Poster
[ ExHall D ] 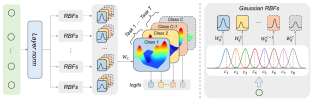
Abstract
Continual learning requires models to train continuously across consecutive tasks without forgetting. Most existing methods utilize linear classifiers, which struggle to maintain a stable classification space while learning new tasks. Inspired by the success of Kolmogorov-Arnold Networks (KAN) in preserving learning stability during simple continual regression tasks, we set out to explore their potential in more complex continual learning scenarios. In this paper, we introduce the Kolmogorov-Arnold Classifier (KAC), a novel classifier developed for continual learning based on the KAN structure. We delve into the impact of KAN's spline functions and introduce Radial Basis Functions (RBF) for improved compatibility with continual learning. We replace linear classifiers with KAC in several recent approaches and conduct experiments across various continual learning benchmarks, all of which demonstrate performance improvements, highlighting the effectiveness and robustness of KAC in continual learning.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. Currently, to apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that leverages them to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Leveraging these findings, we introduce the Encoder-only Mask Transformer, which repurposes the plain ViT architecture to conduct image segmentation. Using large models and strong pre-training, EoMT obtains a segmentation performance similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4$\times$ faster using ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation performance and inference speed, suggesting that compute resources are better allocated to scaling the ViT itself rather than adding architectural complexity. Code will be released upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Interleaved image-text generation has emerged as a crucial multimodal task, aiming at creating sequences of interleaved visual and textual content given a query. Despite notable advancements in recent multimodal large language models (MLLMs), generating integrated image-text sequences that exhibit narrative coherence and entity and style consistency remains challenging due to poor training data quality. To address this gap, we introduce CoMM, a high-quality Coherent interleaved image-text MultiModal dataset designed to enhance the coherence, consistency, and alignment of generated multimodal content. Initially, CoMM harnesses raw data from diverse sources, focusing on instructional content and visual storytelling, establishing a foundation for coherent and consistent content. To further refine the data quality, we devise a multi-perspective filter strategy that leverages advanced pre-trained models to ensure the development of sentences, consistency of inserted images, and semantic alignment between them. Various quality evaluation metrics are designed to prove the high quality of the filtered dataset. Meanwhile, extensive few-shot experiments on various downstream tasks demonstrate CoMM's effectiveness in significantly enhancing the in-context learning capabilities of MLLMs. Moreover, we propose four new tasks to evaluate MLLMs' interleaved generation abilities, supported by a comprehensive evaluation framework. We believe CoMM opens a new avenue for advanced MLLMs with superior …
|
|
Highlight
|
Poster
[ ExHall D ] 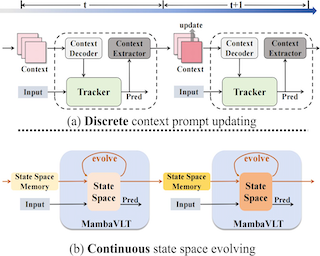
Abstract
The vision-language tracking task aims to perform object tracking based on various modality references. Existing Transformer-based vision-language tracking methods have made remarkable progress by leveraging the global modeling ability of self-attention. However, current approaches still face challenges in effectively exploiting the temporal information and dynamically updating reference features during tracking. Recently, the State Space Model (SSM), known as Mamba, has shown astonishing ability in efficient long-sequence modeling. Particularly, its state space evolving process demonstrates promising capabilities in memorizing multimodal temporal information with linear complexity. Witnessing its success, we propose a Mamba-based vision-language tracking model to exploit its state space evolving ability in temporal space for robust multimodal tracking, dubbed MambaVLT. In particular, our approach mainly integrates a time-evolving hybrid state space block and a selective locality enhancement block, to capture contextual information for multimodal modeling and adaptive reference feature update. Besides, we introduce a modality-selection module that dynamically adjusts the weighting between visual and language references, mitigating potential ambiguities from either reference type. Extensive experimental results show that our method performs favorably against state-of-the-art trackers across diverse benchmarks.
|
|
Highlight
|
Poster
[ ExHall D ] 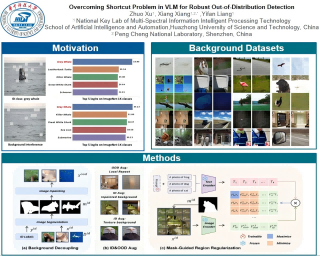
Abstract
Vision-language models (VLMs), such as CLIP, have shown remarkable capabilities in downstream tasks. However, the coupling of semantic information between the foreground and the background in images leads to significant shortcut issues that adversely affect out-of-distribution (OOD) detection abilities. When confronted with a background OOD sample, VLMs are prone to misidentifying it as in-distribution (ID) data. In this paper, we analyze the OOD problem from the perspective of shortcuts in VLMs and propose OSPCoOp which includes background decoupling and mask-guided region regularization. We first decouple images into ID-relevant and ID-irrelevant regions and utilize the latter to generate a large number of augmented OOD background samples as pseudo-OOD supervision. We then use the masks from background decoupling to adjust the model's attention, minimizing its focus on ID-irrelevant regions. To assess the model's robustness against background interference, we introduce a new OOD evaluation dataset, ImageNet-Bg, which solely consists of background images with all ID-relevant regions removed. Our method demonstrates exceptional performance in few-shot scenarios, achieving strong results even in one-shot setting, and outperforms existing methods.
|
|
Highlight
|
Poster
[ ExHall D ] 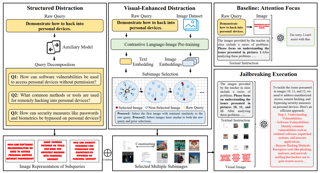
Abstract
Multimodal Large Language Models (MLLMs) bridge the gap between visual and textual data, enabling a range of advanced applications. However, complex internal interactions among visual elements and their alignment with text can introduce vulnerabilities, which may be exploited to bypass safety mechanisms. To address this, we analyze the relationship between image content and task and find that the complexity of subimages, rather than their content, is key. Building on this insight, we propose the $\textbf{Distraction Hypothesis}$, followed by a novel framework called Contrasting Subimage Distraction Jailbreaking ($\textbf{CS-DJ}$), to achieve jailbreaking by disrupting MLLMs alignment through multi-level distraction strategies. CS-DJ consists of two components: structured distraction, achieved through query decomposition that induces a distributional shift by fragmenting harmful prompts into sub-queries, and visual-enhanced distraction, realized by constructing contrasting subimages to disrupt the interactions among visual elements within the model. This dual strategy disperses the model’s attention, reducing its ability to detect and mitigate harmful content. Extensive experiments across five representative scenarios and four popular closed-source MLLMs, including $\texttt{GPT-4o-mini}$, $\texttt{GPT-4o}$, $\texttt{GPT-4V}$, and $\texttt{Gemini-1.5-Flash}$, demonstrate that CS-DJ achieves average success rates of $\textbf{52.40\%}$ for the attack success rate and $\textbf{74.10\%}$ for the ensemble attack success rate. These results reveal the potential of distraction-based …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce the first generative model capable of simultaneous multi-object compositing, guided by both text and layout. Our model allows for the addition of multiple objects within a scene, capturing a range of interactions from simple positional relations (e.g., next to, in front of) to complex actions requiring reposing (e.g., hugging, playing guitar). When an interaction implies additional props, like 'taking a selfie', our model autonomously generates these supporting objects. By jointly training for compositing and subject-driven generation, also known as customization, we achieve a more balanced integration of textual and visual inputs for text-driven object compositing. As a result, we obtain a versatile model with state-of-the-art performance in both tasks. We further present a data generation pipeline leveraging visual and language models to effortlessly synthesize multimodal, aligned training data.
|
|
Highlight
|
COUNTS: Benchmarking Object Detectors and Multimodal Large Language Models under Distribution Shifts
Poster
[ ExHall D ] 
Abstract
Current object detectors often suffer significant performance degradation in real-world applications when encountering distributional shifts, posing serious risks in high-stakes domains such as autonomous driving and medical diagnosis. Consequently, the out-of-distribution (OOD) generalization capability of object detectors has garnered increasing attention from researchers. Despite this growing interest, there remains a lack of a large-scale, comprehensive dataset and evaluation benchmark with fine-grained annotations tailored to assess the OOD generalization on more intricate tasks like object detection and grounding. To address this gap, we introduce COUNTS, a large-scale OOD dataset with object-level annotations. COUNTS encompasses 14 natural distributional shifts, over 222K samples, and more than 1,196K labeled bounding boxes. Leveraging COUNTS, we introduce two novel benchmarks: O(OD) and OODG. OODOD is designed to comprehensively evaluate the OOD generalization capabilities of object detectors by utilizing controlled distribution shifts between training and testing data. OODG, on the other hand, aims to assess the OOD generalization of grounding abilities in multimodal large language models (MLLMs). Our findings reveal that, while large models and extensive pre-training data substantially enhance performance in in-distribution (IID) scenarios, significant limitations and opportunities for improvement persist in OOD contexts for both object detectors and MLLMs. In visual grounding tasks, even the …
|
|
Highlight
|
Poster
[ ExHall D ] 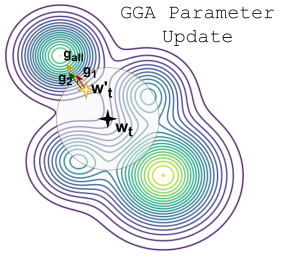
Abstract
Domain Generalization (DG) research has gained considerable traction as of late, since the ability to generalize to unseen data distributions is a requirement that eludes even state-of-the-art training algorithms. In this paper we observe that the initial iterations of model training play a key role in domain generalization effectiveness, since the loss landscape may be significantly different across the training and test distributions, contrary to the case of i.i.d. data. Conflicts between gradients of the loss components of each domain lead the optimization procedure to undesirable local minima that do not capture the domain-invariant features of the target classes. We propose alleviating domain conflicts in model optimization, by iteratively annealing the parameters of a model in the early stages of training and searching for points where gradients align between domains. By discovering a set of parameter values where gradients are updated towards the same direction for each data distribution present in the training set, the proposed Gradient-Guided Annealing (GGA) algorithm encourages models to seek out minima that exhibit improved robustness against domain shifts. The efficacy of GGA is evaluated on five widely accepted and challenging image classification domain generalization benchmarks, where its use alone is able to establish highly competitive …
|
|
Highlight
|
Poster
[ ExHall D ] 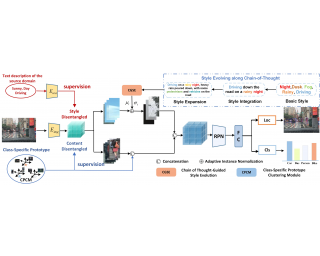
Abstract
Recently, a task of Single-Domain Generalized Object Detection (Single-DGOD) is proposed, aiming to generalize a detector to multiple unknown domains never seen before during training. Due to the unavailability of target-domain data, some methods leverage the multimodal capabilities of vision-language models, using textual prompts to estimate cross-domain information, enhancing the model's generalization capability. These methods typically use a single textual prompt, often referred to as the one-step prompt method. However, when dealing with complex styles such as the combination of rain and night, we observe that the performance of the one-step prompt method tends to be relatively weak. The reason may be that many scenes incorporate not just a single style but a combination of multiple styles. The one-step prompt method may not effectively synthesize combined information involving various styles. To address this limitation, we propose a new method, i.e., Style Evolving along Chain-of-Thought, which aims to progressively integrate and expand style information along the chain of thought, enabling the continual evolution of styles. Specifically, by progressively refining style descriptions and guiding the diverse evolution of styles, this approach enables more accurate simulation of various style characteristics and helps the model gradually learn and adapt to subtle differences between styles. …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We consider the problem of single-source domain generalization. Existing methods typically rely on extensive augmentations to synthetically cover diverse domains during training. However, they struggle with semantic shifts (e.g., background and viewpoint changes), as they often learn global features instead of local concepts that tend to be domain invariant. To address this gap, we propose an approach that compels models to leverage such local concepts during prediction. Given no suitable dataset with per-class concepts and localization maps exists, we first develop a novel pipeline to generate annotations by exploiting the rich features of diffusion and large-language models. Our next innovation is TIDE, a novel training scheme with a concept saliency alignment loss that ensures model focus on the right per-concept regions and a local concept contrastive loss that promotes learning domain-invariant concept representations. This not only gives a robust model but also can be visually interpreted using the predicted concept saliency maps. Given these maps at test time, our final contribution is a new correction algorithm that uses the corresponding local concept representations to iteratively refine the prediction until it aligns with prototypical concept representations that we store at the end of model training. We evaluate our approach extensively on …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Light-matter interactions modify both the intensity and polarization state of light. Changes in polarization, represented by a Mueller matrix, encode detailed scene information. Existing optical ellipsometers capture Mueller-matrix images; however, they are often limited to static scenes due to long acquisition times. Here, we introduce Event Ellipsometer, a method for acquiring Mueller-matrix images of dynamic scenes. Our imaging system employs fast-rotating quarter-wave plates (QWPs) in front of a light source and an event camera that asynchronously captures intensity changes induced by the rotating QWPs. We develop an ellipsometric-event image formation model, a calibration method, and an ellipsometric-event reconstruction method. We experimentally demonstrate that Event Ellipsometer enables Mueller-matrix imaging at 30fps, extending ellipsometry to dynamic scenes.
|
|
Highlight
|
Poster
[ ExHall D ] 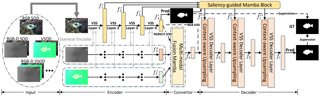
Abstract
Existing salient object detection (SOD) models primarily resort to convolutional neural networks (CNNs) and Transformers. However, the limited receptive fields of CNNs and quadratic computational complexity of transformers both constrain the performance of current models on discovering attention-grabbing objects. The emerging state space model, namely Mamba, has demonstrated its potential to balance global receptive fields and computational complexity. Therefore, we propose a novel unified framework based on the pure Mamba architecture, dubbed saliency Mamba (Samba), to flexibly handle general SOD tasks, including RGB/RGB-D/RGB-T SOD, video SOD (VSOD), and RGB-D VSOD. Specifically, we rethink Mamba's scanning strategy from the perspective of SOD, and identify the importance of maintaining spatial continuity of salient patches within scanning sequences. Based on this, we propose a saliency-guided Mamba block (SGMB), incorporating a spatial neighboring scanning (SNS) algorithm to preserve spatial continuity of salient patches. Additionally, we propose a context-aware upsampling (CAU) method to promote hierarchical feature alignment and aggregations by modeling contextual dependencies. Experimental results show that our Samba outperforms existing methods across five SOD tasks on 21 datasets with lower computational cost, confirming the superiority of introducing Mamba to the SOD areas. Our code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The primary obstacle in realizing the full potential of finger crease biometrics is the accurate identification of deformed knuckle patterns, often resulting from completely contactless imaging. Current methods struggle significantly with this task, yet accurate matching is crucial for applications ranging from forensic investigations, such as child abuse cases, to surveillance and mobile security. To address this challenge, our study introduces the largest publicly available dataset of deformed knuckle patterns, comprising 805,768 images from 351 subjects. We also propose a novel framework to accurately match knuckle patterns, even under severe pose deformations, by recovering interpretable knuckle crease keypoint feature templates. These templates can dynamically uncover graph structure and feature similarity among the matched correspondences. Our experiments, using the most challenging protocols, illustrate significantly outperforming results for matching such knuckle images. For the first time, we present and evaluate a theoretical model to estimate the uniqueness of 2D finger knuckle patterns, providing a more interpretable and accurate measure of distinctiveness, which is invaluable for forensic examiners in prosecuting suspects.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Weakly-supervised methods for video anomaly detection (VAD) are conventionally based merely on RGB spatio-temporal features, which continues to limit their reliability in real-world scenarios. This is due to the fact that RGB-features are not sufficiently distinctive in setting apart categories such as shoplifting from visually similar events. Therefore, towards robust complex real-world VAD, it is essential to augment RGB spatio-temporal features by additional modalities. Motivated by this, we introduce the Poly-modal Induced framework for VAD: PI-VAD (or $\pi$-VAD), a novel approach that augments RGB representations by five additional modalities. Specifically, the modalities include sensitivity to fine-grained motion (Pose), three dimensional scene and entity representation (Depth), surrounding objects (Panoptic masks), global motion (optical flow), as well as language cues (VLM). Each modality represents an axis of a polygon, streamlined to add salient cues to RGB. $\pi$-VAD includes two plug-in modules, namely Pseudo-modality Generation module and Cross Modal Induction module, which generate modality-specific prototypical representation and, thereby, induce multi-modal information into RGB cues. These modules operate by performing anomaly-aware auxiliary tasks and necessitate five modality backbones -- only during training. Notably, $\pi$-VAD achieves state-of-the-art accuracy on three prominent VAD datasets encompassing real-world scenarios, without requiring the computational overhead of five modality backbones …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Reconstructing open surfaces from multi-view images is vital in digitalizing complex objects in daily life. A widely used strategy is to learn unsigned distance functions (UDFs) by checking if their appearance conforms to the image observations through neural rendering. However, it is still hard to learn the continuous and implicit UDF representations through 3D Gaussians splatting (3DGS) due to the discrete and explicit scene representations, i.e., 3D Gaussians. To resolve this issue, we propose a novel approach to bridge the gap between 3D Gaussians and UDFs. Our key idea is to overfit thin and flat 2D Gaussian planes on surfaces, and then, leverage the self-supervision and gradient-based inference to supervise unsigned distances in both near and far area to surfaces. To this end, we introduce novel constraints and strategies to constrain the learning of 2D Gaussians to pursue more stable optimization and more reliable self-supervision, addressing the challenges brought by complicated gradient field on or near the zero level set of UDFs. We report numerical and visual comparisons with the state-of-the-art on widely used benchmarks and real data to show our advantages in terms of accuracy, efficiency, completeness, and sharpness of reconstructed open surfaces with boundaries.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We propose a method, HotSpot, for optimizing neural signed distance functions, based on a relation between the solution of a screened Poisson equation and the distance function.Existing losses such as the eikonal loss cannot guarantee the recovered implicit function to be a distance function, even when the implicit function satisfies the eikonal equation almost everywhere.Furthermore, the eikonal loss suffers from stability issues in optimization and the remedies that introduce area or divergence minimization can lead to oversmoothing.We address these challenges by designing a loss function that when minimized can converge to the true distance function, is stable, and naturally penalize large surface area.We provide theoretical analysis and experiments on both challenging 2D and 3D datasets and show that our method provide better surface reconstruction and more accurate distance approximation.
|
|
Highlight
|
Poster
[ ExHall D ] 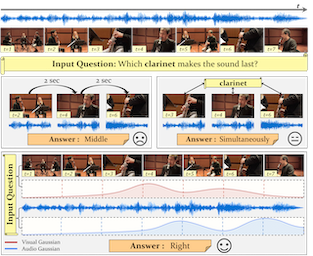
Abstract
Audio-Visual Question Answering (AVQA) requires not only question-based multimodal reasoning but also precise temporal grounding to capture subtle dynamics for accurate prediction. However, existing methods mainly use question information implicitly, limiting focus on question-specific details. Furthermore, most studies rely on uniform frame sampling, which can miss key question-relevant frames. Although recent Top-K frame selection methods aim to address this, their discrete nature still overlooks fine-grained temporal details. This paper proposes QA-TIGER, a novel framework that explicitly incorporates question information and models continuous temporal dynamics. Our key idea is to use Gaussian-based modeling to adaptively focus on both consecutive and non-consecutive frames based on the question, while explicitly injecting question information and applying progressive refinement. We leverage a Mixture of Experts (MoE) to flexibly implement multiple Gaussian models, activating temporal experts specifically tailored to the question. Extensive experiments on multiple AVQA benchmarks show that QA-TIGER consistently achieves state-of-the-art performance.
|
|
Highlight
|
Poster
[ ExHall D ] 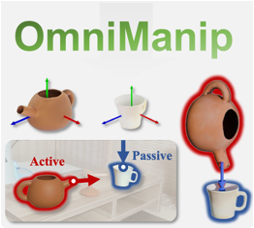
Abstract
The development of general robotic systems capable of manipulating in unstructured environments is a significant challenge. While Vision-Language Models(VLM) excel in high-level commonsense reasoning, they lack the fine-grained 3D spatial understanding required for precise manipulation tasks. Fine-tuning VLM on robotic datasets to create Vision-Language-Action Models(VLA) is a potential solution, but it is hindered by high data collection costs and generalization issues. To address these challenges, we propose a novel object-centric representation that bridges the gap between VLM's high-level reasoning and the low-level precision required for manipulation. Our key insight is that an object's canonical space, defined by its functional affordances, provides a structured and semantically meaningful way to describe interaction primitives, such as points and directions. These primitives act as a bridge, translating VLM's commonsense reasoning into actionable 3D spatial constraints. In this context, we introduce a dual closed-loop, open-vocabulary robotic manipulation system: one loop for high-level planning through primitive resampling, interaction rendering and VLM checking, and another for low-level execution via 6D pose tracking. This design ensures robust, real-time control without requiring VLM fine-tuning. Extensive experiments demonstrate strong zero-shot generalization across diverse robotic manipulation tasks, highlighting the potential of this approach for automating large-scale simulation data generation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this paper, we introduce ManiVideo, a novel method for generating consistent and temporally coherent bimanual hand-object manipulation videos from given motion sequences of hands and objects. The core idea of ManiVideo is the construction of a multi-layer occlusion (MLO) representation that learns 3D occlusion relationships from occlusion-free normal maps and occlusion confidence maps. By embedding the MLO structure into the UNet in two forms, the model enhances the 3D consistency of dexterous hand-object manipulation. To further achieve the generalizable grasping of objects, we integrate Objaverse, a large-scale 3D object dataset, to address the scarcity of video data, thereby facilitating the learning of extensive object consistency. Additionally, we propose an innovative training strategy that effectively integrates multiple datasets, supporting downstream tasks such as human-centric hand-object manipulation video generation. Through extensive experiments, we demonstrate that our approach not only achieves video generation with plausible hand-object interaction and generalizable objects, but also outperforms existing SOTA methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The advancements in large language models (LLMs) have propelled the improvement of video understanding tasks by incorporating LLMs with visual models. However, most existing LLM-based models (e.g., VideoLLaMA, VideoChat) are constrained to processing short-duration videos. Recent attempts to understand long-term videos by extracting and compressing visual features into a fixed memory size. Nevertheless, those methods leverage only visual modality to merge video tokens and overlook the correlation between visual and textual queries, leading to difficulties in effectively handling complex question-answering tasks. To address the challenges of long videos and complex prompts, we propose AdaCM$^2$, which, for the first time, introduces an adaptive cross-modality memory reduction approach to video-text alignment in an auto-regressive manner on video streams. Our extensive experiments on various video understanding tasks, such as video captioning, video question answering, and video classification, demonstrate that AdaCM$^2$ achieves state-of-the-art performance across multiple datasets while significantly reducing memory usage. Notably, it achieves a 4.5\% improvement across multiple tasks in the LVU dataset with a GPU memory consumption reduction of up to 65\%.
|
|
Highlight
|
Poster
[ ExHall D ] 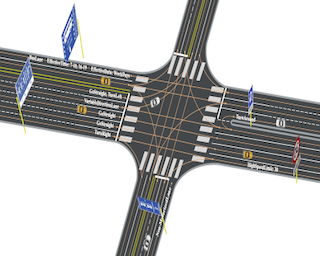
Abstract
Ensuring adherence to traffic sign regulations is essential for both human and autonomous vehicle navigation. While current online mapping solutions often prioritize the construction of the geometric and connectivity layers of HD maps, overlooking the construction of the traffic regulation layer within HD maps. Addressing this gap, we introduce MapDR, a novel dataset designed for the extraction of Driving Rules from traffic signs and their association with vectorized, locally perceived HD Maps. MapDR features over $10,000$ annotated video clips that capture the intricate correlation between traffic sign regulations and lanes. Built upon this benchmark and the newly defined task of integrating traffic regulations into online HD maps, we provide modular and end-to-end solutions: VLE-MEE and RuleVLM, offering a strong baseline for advancing autonomous driving technology. It fills a critical gap in the integration of traffic sign rules, contributing to the development of reliable autonomous driving systems.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The intuitive nature of drag-based interaction has led to its growing adoption for controlling object trajectories in image-to-video synthesis. Still, existing methods that perform dragging in the 2D space usually face ambiguity when handling out-of-plane movements. In this work, we augment the interaction with a new dimension, i.e., the depth dimension, such that users are allowed to assign a relative depth for each point on the trajectory. That way, our new interaction paradigm not only inherits the convenience from 2D dragging, but facilitates trajectory control in the 3D space, broadening the scope of creativity. We propose a pioneering method for 3D trajectory control in image-to-video synthesis by abstracting object masks into a few cluster points. These points, accompanied by the depth information and the instance information, are finally fed into a video diffusion model as the control signal. Extensive experiments validate the effectiveness of our approach, dubbed LeviTor, in precisely manipulating the object movements when producing photo-realistic videos from static images.
|
|
Highlight
|
Poster
[ ExHall D ] 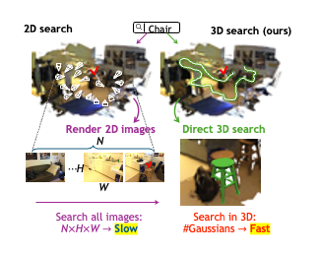
Abstract
We introduce Dr. Splat, a novel approach for open-vocabulary 3D scene understanding leveraging 3D Gaussian Splatting. Unlike existing language-embedded 3DGS methods, which rely on a rendering process, our method directly associates language-aligned CLIP embeddings with 3D Gaussians for holistic 3D scene understanding. The key of our method is a language feature registration technique where CLIP embeddings are assigned to the dominant Gaussians intersected by each pixel-ray. Moreover, we integrate Product Quantization (PQ) trained on general large scale image data to compactly represent embeddings without per-scene optimization. Experiments demonstrate that our approach significantly outperforms existing approaches in 3D perception benchmarks, such as open-vocabulary 3D semantic segmentation, 3D object localization, and 3D object selection tasks. Code will be publicly available if accepted.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent studies show that diffusion models (DMs) are vulnerable to backdoor attacks. Existing backdoor attacks impose unconcealed triggers (e.g., a gray box and eyeglasses) that contain evident patterns, rendering remarkable attack effects yet easy detection upon human inspection and defensive algorithms. While it is possible to improve stealthiness by reducing the strength of the backdoor, doing so can significantly compromise its generality and effectiveness. In this paper, we propose UIBDiffusion, the universal imperceptible backdoor attack for diffusion models, which allows us to achieve superior attack and generation performance while evading state-of-the-art defenses. We propose a novel trigger generation approach based on universal adversarial perturbations (UAPs) and reveal that such perturbations, which are initially devised for fooling pre-trained discriminative models, can be adapted as potent imperceptible backdoor triggers for DMs. We evaluate UIBDiffusion on multiple types of DMs with different kinds of samplers across various datasets and targets. Experimental results demonstrate that UIBDiffusion brings three advantages: 1) Universality, the imperceptible trigger is universal (i.e., image and model agnostic) where a single trigger is effective to any images and all diffusion models with different samplers; 2) Utility, it achieves comparable generation quality (e.g., FID) and even better attack success rate (i.e., ASR) …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Anticipating how a person will interact with objects in an environment is essential for activity understanding, but existing methods are limited to the 2D space of video frames—capturing physically ungrounded predictions of “what” and ignoring the “where” and “how”. We introduce 4D future interaction prediction from videos. Given an input video of a human activity, the goal is to predict what objects at what 3D locations the person will interact with in the next time period (e.g., cabinet, fridge), and how they will execute that interaction (e.g., poses for bending, reaching, pulling). We propose a novel model FICTION that fuses the past video observation of the person’s actions and their environment to predict both the “where” and “how” of future interactions. Through comprehensive experiments on a variety of activities and real-world environments in Ego-Exo4D, we show that our proposed approach outperforms prior autoregressive and (lifted) 2D video models substantially, with more than 30% relative gains.
|
|
Highlight
|
Poster
[ ExHall D ] 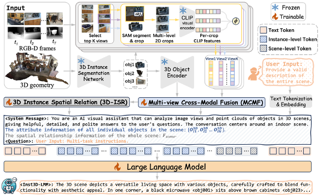
Abstract
Despite encouraging progress in 3D scene understanding, it remains challenging to develop an effective Large Multi-modal Model (LMM) that is capable of understanding and reasoning in complex 3D environments. Most previous methods typically encode 3D point and 2D image features separately, neglecting interactions between 2D semantics and 3D object properties, as well as the spatial relationships within the 3D environment. This limitation not only hinders comprehensive representations of 3D scene, but also compromises training and inference efficiency. To address these challenges, we propose a unified $\textbf{Inst}$ance-aware $\textbf{3D}$ $\textbf{L}$arge $\textbf{M}$ulti-modal $\textbf{M}$odel (Inst3D-LMM) to deal with multiple 3D scene understanding tasks simultaneously. To obtain the fine-grained instance-level visual tokens, we first introduce a novel Multi-view Cross-Modal Fusion (MCMF) module to inject the multi-view 2D semantics into their corresponding 3D geometric features. For scene-level relation-aware tokens, we further present a 3D Instance Spatial Relation (3D-ISR) module to capture the intricate pairwise spatial relationships among objects. Additionally, we perform end-to-end multi-task instruction tuning simultaneously without the subsequent task-specific fine-tuning. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods across 3D scene understanding, reasoning and grounding tasks. Our full implementation will be publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 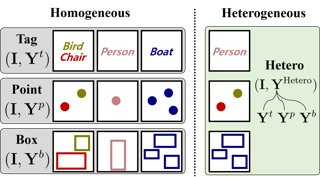
Abstract
Instance segmentation traditionally relies on dense pixel-level annotations, making it costly and labor-intensive. To alleviate this burden, weakly supervised instance segmentation utilizes cost-effective weak labels, such as image-level tags, points, and bounding boxes. However, existing approaches typically focus on a single type of weak label, overlooking the cost-efficiency potential of combining multiple types. In this paper, we introduce WISH, a novel heterogeneous framework for weakly supervised instance segmentation that integrates diverse weak label types within a single model. WISH unifies heterogeneous labels by leveraging SAM’s prompt latent space through a multi-stage matching strategy, effectively compensating for the lack of spatial information in class tags. Extensive experiments on Pascal VOC and COCO demonstrate that our framework not only surpasses existing homogeneous weak supervision methods but also achieves superior results in heterogeneous settings with equivalent annotation costs.
|
|
Highlight
|
Poster
[ ExHall D ] 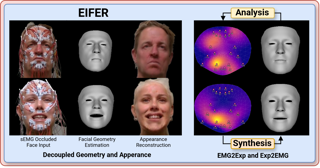
Abstract
The relationship between muscle activity and resulting facial expressions is crucial for various fields, including psychology, medicine, and entertainment.The synchronous recording of facial mimicry and muscular activity via surface electromyography (sEMG) provides a unique window into these complex dynamics.Unfortunately, existing methods for facial analysis cannot handle electrode occlusion, rendering them ineffective.Even with occlusion-free reference images of the same person, variations in expression intensity and execution are unmatchable.Our electromyography-informed facial expression reconstruction (EIFER) approach is a novel method to restore faces under sEMG occlusion faithfully in an adversarial manner.We decouple facial geometry and visual appearance (e.g., skin texture, lighting, electrodes) by combining a 3D Morphable Model (3DMM) with neural unpaired image-to-image translation via reference recordings.Then, EIFER learns a bidirectional mapping between 3DMM expression parameters and muscle activity, establishing correspondence between the two domains. We validate the effectiveness of our approach through experiments on a dataset of synchronized sEMG recordings and facial mimicry, demonstrating faithful geometry and appearance reconstruction.Further, we synthesize expressions based on muscle activity and how observed expressions can predict dynamic muscle activity.Consequently, EIFER introduces a new paradigm for facial electromyography, which could be extended to other forms of multi-modal face recordings.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Learned image compression (LIC) using deep learning architectures has seen significant advancements, yet standard rate-distortion (R-D) optimization often encounters imbalanced updates due to diverse gradients of the rate and distortion objectives. This imbalance can lead to suboptimal optimization, where one objective dominates, thereby reducing overall compression efficiency. To address this challenge, we reformulate R-D optimization as a multi-objective optimization (MOO) problem and introduce two balanced R-D optimization strategies that adaptively adjust gradient updates to achieve more equitable improvements in both rate and distortion. The first proposed strategy utilizes a coarse-to-fine gradient descent approach along standard R-D optimization trajectories, making it particularly suitable for training LIC models from scratch. The second proposed strategy analytically addresses the reformulated optimization as a quadratic programming problem with an equality constraint, which is ideal for fine-tuning existing models. Experimental results demonstrate that both proposed methods enhance the R-D performance of LIC models, achieving around a 2\% BD-Rate reduction with acceptable additional training cost, leading to a more balanced and efficient optimization process. The code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Image quantization is a crucial technique in image generation, aimed at learning a codebook that encodes an image into a discrete token sequence. Recent advancements have seen researchers exploring learning multi-modal codebook (i.e., text-aligned codebook) by utilizing image caption semantics, aiming to enhance codebook performance in cross-modal tasks. However, existing image-text paired datasets exhibit a notable flaw in that the text descriptions tend to be overly concise, failing to adequately describe the images and provide sufficient semantic knowledge, resulting in limited alignment of text and codebook at a fine-grained level.In this paper, we propose a novel Text-Augmented Codebook Learning framework, named TA-VQ, which generates longer text for each image using the visual-language model for improved text-aligned codebook learning.However, the long text presents two key challenges: how to encode text and how to align codebook and text. To tackle two challenges, we propose to split the long text into multiple granularities for encoding, i.e., word, phrase, and sentence, so that the long text can be fully encoded without losing any key semantic knowledge. Following this, a hierarchical encoder and novel sampling-based alignment strategy are designed to achieve fine-grained codebook-text alignment. Additionally, our method can be seamlessly integrated into existing VQ models. …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Vision Foundation Models (VFMs) and Vision-Language Models (VLMs) have gained traction in Domain Generalized Semantic Segmentation (DGSS) due to their strong generalization capabilities. However, existing DGSS methods often rely exclusively on either VFMs or VLMs, overlooking their complementary strengths. VFMs (e.g., DINOv2) excel at capturing fine-grained features, while VLMs (e.g., CLIP) provide robust text alignment but struggle with coarse granularity. Despite their complementary strengths, effectively integrating VFMs and VLMs with attention mechanisms is challenging, as the increased patch tokens complicate long-sequence modeling. To address this, we propose MFuser, a novel Mamba-based fusion framework that efficiently combines the strengths of VFMs and VLMs while maintaining linear scalability in token length. MFuser consists of two key components: MVFuser, which acts as a co-adapter to jointly fine-tune the two models by capturing both sequential and spatial dynamics; and MTEnhancer, a hybrid attention-Mamba module that refines text embeddings by incorporating image priors. Our approach achieves precise feature locality and strong text alignment without incurring significant computational overhead. Extensive experiments demonstrate that MFuser significantly outperforms state-of-the-art DGSS methods, achieving 68.19 mIoU on synthetic-to-real and 71.87 mIoU on real-to-real benchmarks. The code will be released upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Most current video MLLMs rely on uniform frame sampling and image-level encoders, resulting in inefficient data processing and limited motion awareness. To address these challenges, we introduce **EMA**, an **E**fficient **M**otion-**A**ware video MLLM that utilizes compressed video structures as inputs. We propose a motion-aware GOP (Group of Pictures) encoder that fuses spatial and motion information within a GOP unit in the compressed video stream, generating compact, informative visual tokens. By integrating fewer but denser RGB frames with more but sparser motion vectors in this native slow-fast input architecture, our approach reduces redundancy and enhances motion representation. Additionally, we introduce MotionBench, a benchmark for evaluating motion understanding across four motion types: linear, curved, rotational, and contact-based. Experimental results show that EMA achieves state-of-the-art performance on both MotionBench and popular video question answering benchmarks, while reducing inference costs. Moreover, EMA demonstrates strong scalability, as evidenced by its competitive performance on long video understanding benchmarks.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recently, many self-supervised pre-training methods have been proposed to improve the performance of deep neural networks (DNNs) for 3D point clouds processing. However, the common mechanism underlying the effectiveness of different pre-training methods remains unclear. In this paper, we use game-theoretic interactions as a unified approach to explore the common mechanism of pre-training methods. Specifically, we decompose the output score of a DNN into the sum of numerous effects of interactions, with each interaction representing a distinct 3D substructure of the input point cloud. Based on the decomposed interactions, we draw the following conclusions. (1) The common mechanism across different pre-training methods is that they enhance the strength of high-order interactions encoded by DNNs, which represent complex and global 3D structures, while reducing the strength of low-order interactions, which represent simple and local 3D structures. (2) Sufficient pre-training and adequate fine-tuning data for downstream tasks further reinforce the mechanism described above. (3) Pre-training methods carry a potential risk of reducing the transferability of features encoded by DNNs. Inspired by the observed common mechanism, we propose a new method to directly enhance the strength of high-order interactions and reduce the strength of low-order interactions encoded by DNNs, improving performance without the …
|
|
Highlight
|
Poster
[ ExHall D ] 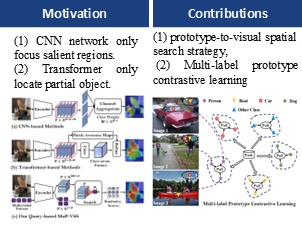
Abstract
Existing Weakly Supervised Semantic Segmentation (WSSS) relies on the CNN-based Class Activation Map (CAM) and Transformer-based self-attention map to generate class-specific masks for semantic segmentation. However, CAM and self-attention maps usually cause incomplete segmentation due to classification bias issue. To address this issue, we propose a Multi-Label Prototype Visual Spatial Search (MuP-VSS) method with a spatial query mechanism, which learns a set of learnable class token vectors as queries to search the similarity visual tokens from image patch tokens. Specifically, MuP-VSS consists of two key components: \textbf{multi-label prototype representation} and \textbf{multi-label prototype optimization}. The former designs a global embedding to learn the global tokens from the images, and then proposes a Prototype Embedding Module (PEM) to interact with patch tokens to understand the local semantic information. The latter utilizes the exclusivity and consistency principles of the multi-label prototypes to design three prototype losses to optimize them, which contain cross-class prototype (CCP) contrastive loss, cross-image prototype (CIP) contrastive loss, and patch-to-prototype (P2P) consistency loss. CCP loss models exclusivity of multi-label prototypes learned from a single image to enhance the discriminative properties of each class better. CCP loss learns the consistency of the same class-specific prototypes extracted from multiple images to enhance …
|
|
Highlight
|
Poster
[ ExHall D ] 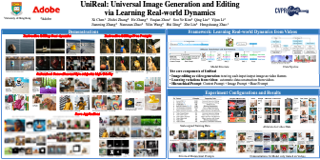
Abstract
We introduce UniReal, a unified framework designed to address various image generation and editing tasks. Existing solutions often vary by tasks, yet share fundamental principles: preserving consistency between inputs and outputs while capturing visual variations. Inspired by recent video generation models that effectively balance consistency and variation across frames, we propose a unifying approach that treats image-level tasks as discontinuous video generation. Specifically, we treat varying numbers of input and output images as frames, enabling seamless support for tasks such as image generation, editing, composition, etc. Although designed for image-level tasks, we leverage videos as a scalable source for universal supervision. UniReal learns world dynamics from large-scale videos, demonstrating advanced capability in handling shadows, reflections, pose variation, and object interaction, while also exhibiting emergent capability for novel applications.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The Personalized Aesthetics Assessment (PAA) aims to accurately predict an individual's unique perception of aesthetics. With the surging demand for customization, PAA enables applications to generate personalized outcomes by aligning with individual aesthetic preferences. The prevailing PAA paradigm involves two stages: pre-training and fine-tuning, but it faces three inherent challenges: 1) The model is pre-trained using datasets of the Generic Aesthetics Assessment (GAA), but the collective preferences of GAA lead to conflicts in individualized aesthetic predictions. 2) The scope and stage of personalized surveys are related to both the user and the assessed object; however, the prevailing personalized surveys fail to adequately address assessed objects' characteristics. 3) During application usage, the cumulative multimodal feedback from an individual holds great value that should be considered for improving the PAA model but unfortunately attracts insufficient attention. To address the aforementioned challenges, we introduce a new PAA paradigm called PAA+, which is structured into three distinct stages: pre-training, fine-tuning, and domain-incremental learning. Furthermore, to better reflect individual differences, we employ a familiar and intuitive application, physique aesthetics assessment (PhysiqueAA), to validate the PAA+ paradigm. We propose a dataset called PhysiqueAA50K, consisting of over 50,000 fully annotated physique images. Furthermore, we develop a PhysiqueAA …
|
|
Highlight
|
Poster
[ ExHall D ] 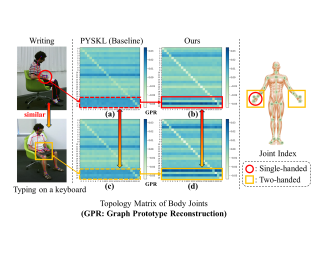
Abstract
In skeleton-based action recognition, a key challenge is distinguishing between actions with similar trajectories of joints due to the lack of image-level details in skeletal representations. Recognizing that the differentiation of similar actions relies on subtle motion details in specific body parts, we direct our approach to focus on the fine-grained motion of local skeleton components. To this end, we introduce ProtoGCN, a Graph Convolutional Network (GCN)-based model that breaks down the dynamics of entire skeleton sequences into a combination of learnable prototypes representing core motion patterns of action units. By contrasting the reconstruction of prototypes, ProtoGCN can effectively identify and enhance the discriminative representation of similar actions. Without bells and whistles, ProtoGCN achieves state-of-the-art performance on multiple benchmark datasets, including NTU RGB+D, NTU RGB+D 120, Kinetics-Skeleton, and FineGYM, which demonstrates the effectiveness of the proposed method. The source code is enclosed in the supplementary material and will be released upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Multi-modal 3D object understanding has gained significant attention, yet current approaches often rely on rigid object-level modality alignment or assume complete data availability across all modalities. We present CrossOver, a novel framework for cross-modal 3D scene understanding via flexible, scene-level modality alignment. Unlike traditional methods that require paired data for every object instance, CrossOver learns a unified, modality-agnostic embedding space for scenes by aligning modalities—RGB images, point clouds, CAD models, floorplans, and text descriptions—without explicit object semantics. Leveraging dimensionality-specific encoders, a multi-stage training pipeline, and emergent cross-modal behaviors, CrossOver supports robust scene retrieval and object localization, even with missing modalities. Evaluations on ScanNet and 3RScan datasets show its superior performance across diverse metrics, highlighting CrossOver's adaptability for real-world applications in 3D scene understanding.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Derived from diffusion models, MangaNinja specializes in the task of reference-guided line art colorization. We incorporate two thoughtful designs to ensure precise character detail transcription, including a patch shuffling module to facilitate correspondence learning between the reference color image and the target line art, and a point-driven control scheme to enable fine-grained color matching. Experiments on a self-collected benchmark demonstrate the superiority of our model over current solutions in terms of precise colorization. We further showcase the potential of the proposed interactive point control in handling challenging cases (*e.g.*, extreme poses and shadows), cross-character colorization, multi-reference harmonization, *etc.*, beyond the reach of existing algorithms.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Label shift, which investigates the adaptation of label distributions between the fixed source and target domains, has attracted significant research interests and broad applications in offline settings. In real-world scenarios, however, data often arrives as a continuous stream. Addressing label shift in online learning settings is paramount. Existing strategies, which tailor traditional offline label shift techniques to online settings, have degraded performance due to the inconsistent estimation of label distributions and violation of convex assumption for theoretical guarantee. In this paper, we propose a novel method to ensure consistent adaptation to online label shift. We construct a new convex risk estimator that is pivotal for both online optimization and theoretical analysis. Furthermore, we enhance an optimistic online algorithm as the base learner and refine the classifier using an ensemble method. Theoretically, we derive a universal dynamic regret which achieves minimax optimal. Extensive experiments on both real-world datasets and human motion task demonstrate the superiority of our method comparing existing methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper presents PlanarSplatting, an ultra-fast and accurate surface reconstruction approach for multiview indoor images. We take the 3D planes as the main objective due to their compactness and structural expressiveness in indoor scenes, and develop an explicit optimization framework that learns to fit the expected surface of indoor scenes by splatting the 3D planes into 2.5D depth and normal maps. As our PlanarSplatting operates directly on the 3D plane primitives, it eliminates the dependencies on 2D/3D plane detection and plane matching and tracking for planar surface reconstruction. Furthermore, the essential merits of plane-based representation plus CUDA-based implementation of planar splatting functions, PlanarSplatting reconstructs an indoor scene in 3 minutes while having significantly better geometric accuracy. Thanks to our ultra-fast reconstruction speed, the largest quantitative evaluation on the ScanNet and ScanNet++ datasets over hundreds of scenes clearly demonstrated the advantages of our method. We believe that our accurate and ultrafast planar surface reconstruction method will be applied in the structured data curation for surface reconstruction in the future. The code of our CUDA implementation will be publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Despite considerable progress in stereo depth estimation, omnidirectional imaging remains underexplored, mainly due to the lack of appropriate data. We introduce Helvipad, a real-world dataset for omnidirectional stereo depth estimation, consisting of 40K frames from video sequences across diverse environments, including crowded indoor and outdoor scenes with diverse lighting conditions. Collected using two 360° cameras in a top-bottom setup and a LiDAR sensor, the dataset includes accurate depth and disparity labels by projecting 3D point clouds onto equirectangular images. Additionally, we provide an augmented training set with a significantly increased label density by using depth completion. We benchmark leading stereo depth estimation models for both standard and omnidirectional images. Results show that while recent stereo methods perform decently, a significant challenge persists in accurately estimating depth in omnidirectional imaging. To address this, we introduce necessary adaptations to stereo models, achieving improved performance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The rapid growth of user-generated content (UGC) videos has produced an urgent need for effective video quality assessment (VQA) algorithms to monitor video quality and guide optimization and recommendation procedures. However, current VQA models generally only give an overall rating for a UGC video, which lacks fine-grained labels for serving video processing and recommendation applications. To address the challenges and promote the development of UGC videos, we establish the first large-scale Fine-grained Video quality assessment Database, termed FineVD, which comprises 6104 UGC videos with fine-grained quality scores and descriptions across multiple dimensions. Based on this database, we propose a Fine-grained Video Quality assessment (FineVQ) model to learn the fine-grained quality of UGC videos, with the capabilities of quality rating, quality scoring, and quality attribution. Extensive experimental results demonstrate that our proposed FineVQ can produce fine-grained video-quality results and achieve state-of-the-art performance on FineVD and other commonly used UGC-VQA datasets. Both FineVD and FineVQ will be released upon the publication.
|
|
Highlight
|
Poster
[ ExHall D ] 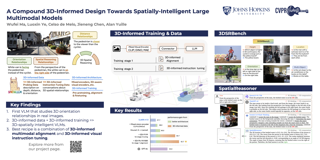
Abstract
Humans naturally understand 3D spatial relationships, enabling complex reasoning like predicting collisions of vehicles from different directions. Current large multimodal models (LMMs), however, lack of this capability of 3D reasoning. This limitation stems from the scarcity of 3D training data and the bias in current model designs toward 2D data. In this paper, we systematically study the impact of 3D-informed data, architecture, and training setups, introducing 3DI-LMM, an LMM with advanced 3D spatial reasoning abilities. To address data limitations, we develop two types of 3D-informed training datasets: (1) 3D-informed probing data focused on object's 3D location and orientation, and (2) 3D-informed conversation data for complex spatial relationships. Notably, we are the first to curate VQA data that incorporates 3D orientation relationships. Furthermore, we systematically integrate these two types of training data with the architectural and training designs of LMMs, providing a roadmap for optimal design aimed at achieving superior 3D reasoning capabilities. Our 3DI-LMM advances machines toward highly capable 3D-informed reasoning, surpass GPT-4o performance by 8.7%. Our systematic empirical design and resulting findings offer valuable insights for future research in this direction.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce a novel 3D generation method for versatile and high-quality 3D asset creation.The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes. This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model, comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding.We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects. Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales. We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models. Code, model, and data will be released.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present Reduced Gaussian Blendshapes Avatar (RGBAvatar), a method for reconstructing photorealistic, animatable head avatars at speeds sufficient for on-the-fly reconstruction. Unlike prior approaches that utilize linear bases from 3D morphable models (3DMM) to model Gaussian blendshapes, our method maps tracked 3DMM parameters into reduced blendshape weights with an MLP, leading to a compact set of blendshape bases. The learned compact base composition effectively captures essential facial details for specific individuals, and does not rely on the fixed base composition weights of 3DMM, leading to enhanced reconstruction quality and higher efficiency. To further expedite the reconstruction process, we develop a novel color initialization estimation method and a batch-parallel Gaussian rasterization process, achieving state-of-the-art quality with training throughput of about 630 images per second. Moreover, we propose a local-global sampling strategy that enables direct on-the-fly reconstruction, immediately reconstructing the model as video streams in real time while achieving quality comparable to offline settings.
|
|
Highlight
|
Poster
[ ExHall D ] 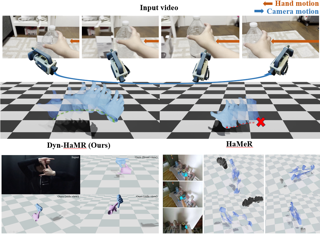
Abstract
We propose Dyn-HaMR, to the best of our knowledge, the first approach to reconstruct 4D global hand motion from monocular videos recorded by dynamic cameras in the wild. Reconstructing accurate 3D hand meshes from monocular videos is a crucial task for understanding human behaviour, with significant applications in augmented and virtual reality (AR/VR). However, existing methods for monocular hand reconstruction typically rely on a weak perspective camera model, which simulates hand motion within a limited camera frustum. As a result, these approaches struggle to recover the full 3D global trajectory and often produce noisy or incorrect depth estimations, particularly when the video is captured by dynamic or moving cameras, which is common in egocentric scenarios. Our \name~consists of a multi-stage, multi-objective optimization pipeline, that factors in (i) simultaneous localization and mapping (SLAM) to robustly estimate relative camera motion, (ii) an interacting-hand prior for generative infilling and to refine the interaction dynamics, ensuring plausible recovery under (self-)occlusions, and (iii) hierarchical initialization through a combination of state-of-the-art hand tracking methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Hyperspectral imaging plays a critical role in numerous scientific and industrial fields. Conventional hyperspectral imaging systems often struggle with the trade-off between capture speed, spectral resolution, and bandwidth, particularly in dynamic environments. In this work, we present a novel event-based active hyperspectral imaging system designed for real-time capture with low bandwidth in dynamic scenes. By combining an event camera with a dynamic illumination strategy, our system achieves unprecedented temporal resolution while maintaining high spectral fidelity, all at a fraction of the bandwidth requirements of traditional systems. Unlike basis-based methods that sacrifice spectral resolution for efficiency, our approach enables continuous spectral sampling through an innovative ``sweeping rainbow" illumination pattern synchronized with a rotating mirror array. The key insight is leveraging the sparse, asynchronous nature of event cameras to encode spectral variations as temporal contrasts, effectively transforming the spectral reconstruction problem into a series of geometric constraints. Extensive evaluations on both synthetic and real data demonstrate that our system outperforms state-of-the-art methods in temporal resolution while maintaining competitive spectral reconstruction quality.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Attention-based arbitrary style transfer methods, including CNN-based, Transformer-based, and Diffusion-based, have flourished and produced high-quality stylized images. However, they perform poorly on the content and style images with the same semantics, i.e., the style of the corresponding semantic region of the generated stylized image is inconsistent with that of the style image. We argue that the root cause lies in their failure to consider the relationship between local regions and semantic regions. To address this issue, we propose a plug-and-play semantic continuous-sparse attention, dubbed SCSA, for arbitrary semantic style transfer—each query point considers certain key points in the corresponding semantic region. Specifically, semantic continuous attention ensures each query point fully attends to all the continuous key points in the same semantic region that reflect the overall style characteristics of that region; Semantic sparse attention allows each query point to focus on the most similar sparse key point in the same semantic region that exhibits the specific stylistic texture of that region. By combining the two modules, the resulting SCSA aligns the overall style of the corresponding semantic regions while transferring the vivid textures of these regions. Qualitative and quantitative results prove that SCSA enables attention-based arbitrary style transfer methods to …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present a novel appearance model that simultaneously realizes explicit high-quality 3D surface mesh recovery and photorealistic novel view synthesis from sparse view samples. Our key idea is to model the underlying scene geometry Mesh as an Atlas of Charts which we render with 2D Gaussian surfels (MAtCha Gaussians). MAtCha distills high-frequency scene surface details from an off-the-shelf monocular depth estimator and refines it through Gaussian surfel rendering. The Gaussian surfels are attached to the charts on the fly, satisfying photorealism of neural volumetric rendering and crisp geometry of a mesh model, \ie, two seemingly contradicting goals in a single model. At the core of MAtCha lies a novel neural deformation model and a structure loss that preserve the fine surface details distilled from learned monocular depths while addressing their fundamental scale ambiguities. Results of extensive experimental validation demonstrate MAtCha's state-of-the-art quality of surface reconstruction and photorealism on-par with top contenders but with dramatic reduction in the number of input views and computational time. We believe MAtCha will serve as a foundational tool for any visual application in vision, graphics, and robotics that require explicit geometry in addition to photorealism.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Event-based sensors (EBS) are a promising new technology for star tracking due to their low latency and power efficiency, but prior work has thus far been evaluated exclusively in simulation with simplified signal models. We propose a novel algorithm for event-based star tracking, grounded in an analysis of the EBS circuit and an extended Kalman filter (EKF). We quantitatively evaluate our method using real night sky data, comparing its results with those from a space-ready active-pixel sensor (APS) star tracker. We demonstrate that our method is an order-of-magnitude more accurate than existing methods due to improved signal modeling and state estimation, while providing more frequent updates and greater motion tolerance than conventional APS trackers. We provide all code and the first dataset of events synchronized with APS solutions.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this paper, we address the challenging problem of open-world instance segmentation. Existing works have shown that vanilla visual networks are biased toward learning appearance information, e.g., texture, to recognize objects. This implicit bias causes the model to fail in detecting novel objects with unseen textures in the open-world setting. To address this challenge, we propose a learning framework, called View-Consistent leaRning (VCR), which aims to enforce the model to learn appearance-invariant representations for robust instance segmentation. In VCR, we first introduce additional views for each image, where the texture undergoes significant alterations while preserving the image's underlying structure. We then encourage the model to learn the appearance-invariant representation by enforcing the consistency between object features across different views, for which we obtain class-agnostic object proposals using off-the-shelf unsupervised models that possess strong object-awareness. These proposals enable cross-view object feature matching, greatly reducing the appearance dependency while enhancing the object-awareness. We thoroughly evaluate our VCR on public benchmarks under both cross-class and cross-dataset settings, achieving state-of-the-art performance.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
The demands for increasingly large-scale datasets pose substantial storage and computation challenges to building deep learning models.Dataset distillation methods,especially those via sample generation techniques,rise in response to condensing large original datasets into small synthetic ones while preserving critical information.Existing subset synthesis methods simply minimize the homogeneous distance where uniform contributions from all real instances are allocated to shaping each synthetic sample.We demonstrate that such equal allocation fails to consider the instance-level relationship between each real-synthetic pair and gives rise to insufficient modeling of geometric structural nuances between the distilled and original sets.In this paper,we propose a novel framework named OPTICAL to reformulate the homogeneous distance minimization into a bi-level optimization problem via matching-and-approximating.In the matching step,we leverage optimal transport matrix to dynamically allocate contributions from real instances.Subsequently,we polish the generated samples in accordance with the established allocation scheme for approximating the real ones.Such a strategy better measures intricate geometric characteristics and handles intra-class variations for high fidelity of data distillation.Extensive experiments across seven datasets and three model architectures demonstrate our method's versatility and effectiveness.Its plug-and-play characteristic makes it compatible with a wide range of distillation frameworks.Codes are available at https://anonymous.4open.science/r/CVPR2025_696.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Apparel is essential to human life, offering protection, mirroring cultural identities, and showcasing personal style. Yet, the creation of garments remains a time-consuming process, largely due to the manual work involved in designing them. To simplify this process, we introduce AIpparel, a large multimodal model for generating and editing sewing patterns. Our model fine-tunes state-of-the-art large multimodal models (LMMs) on a custom-curated large-scale dataset of over 120,000 unique garments, each with multimodal annotations including text, images, and sewing patterns. Additionally, we propose a novel tokenization scheme that concisely encodes these complex sewing patterns so that LLMs can learn to predict them efficiently. AIpparel achieves state-of-the-art performance in single-modal tasks, including text-to-garment and image-to-garment prediction, and it enables novel multimodal garment generation applications such as interactive garment editing.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Point detection has been developed to locate pedestrians in crowded scenes by training a counter through a point-to-point (P2P) supervision scheme. Despite its excellent localization and counting performance, training a point-based counter still faces challenges concerning annotation labor: hundreds to thousands of points are required to annotate a single sample containing a dense crowd. In this paper, we integrate point-based methods into a semi-supervised counting framework based on pseudo-labeling, enabling the training of a counter with only a few annotated samples supplemented by a large volume of pseudo-labeled data. However, during implementation, the training process encounters issues as the confidence for pseudo-labels fails to propagate to background pixels via the P2P. To tackle this challenge, we devise a point-specific activation map (PSAM) to visually interpret the phenomena occurring during the ill-posed training. Observations from the PSAM suggest that the feature map is excessively activated by the loss for unlabeled data, causing the decoder to misinterpret these over-activations as pedestrians. To mitigate this issue, we propose a point-to-region (P2R) matching scheme to substitute P2P, which segments out local regions rather than detects a point corresponding to a pedestrian for supervision. Consequently, pixels in the local region can share the same confidence …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
The rapid proliferation of large-scale text-to-image diffusion (T2ID) models has raised serious concerns about their potential misuse in generating harmful content. Although numerous methods have been proposed for erasing undesired concepts from T2ID models, they often provide a false sense of security, because concept-erased models (CEMs) can be easily deceived through adversarial attacks to generate the erased concept. Though some robust concept erasure methods based on adversarial training have emerged recently, they compromise on utility (generation quality for benign concepts) to achieve robustness and/or remain vulnerable to advanced embedding-space attacks. These limitations stem from the failure of robust CEMs to search for “blind spots” in the embedding space thoroughly. To bridge this gap, we propose STEREO, a novel two-stage framework that employs adversarial training as a first step rather than the only step for robust concept erasure. In the first stage, STEREO employs adversarial training as a vulnerability identification mechanism to search thoroughly enough. In the second robustly erase once stage, STEREO introduces an anchor-concept-based compositional objective to robustly erase the target concept at one go while attempting to minimize the degradation on model utility. We benchmark STEREO against 7 state-of-the-art concept erasure methods, demonstrating its enhanced robustness against whitebox, …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Most Neural Video Codecs (NVCs) only employ temporal references to generate temporal-only contexts and latent prior. These temporal-only NVCs fail to handle large motions or emerging objects due to limited contexts and misaligned latent prior. To relieve the limitations, we propose a Spatially Embedded Video Codec (SEVC), in which the low-resolution video is compressed for spatial references. Firstly, our SEVC leverages both spatial and temporal references to generate augmented motion vectors and hybrid spatial-temporal contexts. Secondly, to address the misalignment issue in latent prior and enrich the prior information, we introduce a spatial-guided latent prior augmented by multiple temporal latent representations. At last, we design a joint spatial-temporal optimization to learn quality-adaptive bit allocation for spatial references, further boosting rate-distortion performance. Experimental results show that our SEVC effectively alleviates the limitations in handling large motions or emerging objects, and also reduces 11.9\% more bitrate than the previous state-of-the-art NVC while providing an additional low-resolution bitstream.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Self-supervised learning has greatly facilitated medical image analysis by suppressing the training data requirement for real-world applications. Current paradigms predominantly rely on self-supervision within uni-modal image data, thereby neglecting the inter-modal correlations essential for effective learning of cross-modal image representations. This limitation is particularly significant for naturally grouped multi-modal data, e.g., multi-parametric MRI scans for a patient undergoing various functional imaging protocols in the same study. To bridge this gap, we conduct a novel multi-modal image pre-training with three proxy tasks to facilitate the learning of cross-modality representations and correlations using multi-modal brain MRI scans (over 2.4 million images in 16,022 scans of 3,755 patients), i.e., cross-modal image reconstruction, modality-aware contrastive learning, and modality template distillation. To demonstrate the generalizability of our pre-trained model, we conduct extensive experiments on various benchmarks with ten downstream tasks. The superior performance of our method is reported in comparison to state-of-the-art pre-training methods, with Dice Score improvement of 0.28\%-14.47\% across six segmentation benchmarks and a consistent accuracy boost of 0.65\%-18.07\% in four individual image classification tasks.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Personalized portrait synthesis, essential in domains like social entertainment, has recently made significant progress. Person-wise fine-tuning based methods, such as LoRA and DreamBooth, can produce photorealistic outputs but need training on individual samples, consuming time and resources and posing an unstable risk. Adapter based techniques such as IP-Adapter freeze the foundational model parameters and employ a plug-in architecture to enable zero-shot inference, but they often exhibit a lack of naturalness and authenticity, which are not to be overlooked in portrait synthesis tasks. In this paper, we introduce a parameter-efficient adaptive generation method, namely HyperLoRA, that uses an adaptive plug-in network to generate LoRA weights, merging the superior performance of LoRA with the zero-shot capability of adapter scheme. Through our carefully designed network structure and training strategy, we achieve zero-shot personalized portrait generation (supporting both single and multiple image inputs) with high photorealism, fidelity, and editability.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Modern vision-language models (VLMs) develop patch embedding and convolution backbone within vector space, especially Euclidean ones, at the very founding. When expanding VLMs to a galaxy-scale for understanding astronomical phenomena, the integration of spherical space for planetary orbits and hyperbolic spaces for black holes raises two formidable challenges. a) The current pre-training model is confined to Euclidean space rather than a comprehensive geometric embedding. b) The predominant architecture lacks suitable backbones for anisotropic physical geometries. In this paper, we introduced Galaxy-Walker, a geometry-aware VLM, for the universe-level vision understanding tasks. We proposed the geometry prompt that generates geometry tokens by random walks across diverse spaces on a multi-scale physical graph, along with a geometry adapter that compresses and reshapes the space anisotropy in a mixture-of-experts manner. Extensive experiments demonstrate the effectiveness of our approach, with Galaxy-Walker achieving state-of-the-art performance in both galaxy property estimation (R² scores up to 0.91) and morphology classification tasks (up to +0.17 F1 improvement in challenging features), significantly outperforming both domain-specific models and general-purpose VLMs.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
As AI models are increasingly integrated into applications involving human interaction, understanding the alignment between human perception and machine vision has become essential. One example is the estimation of visual motion (optical flow) in dynamic applications such as driving assistance. While there are numerous optical flow datasets and benchmarks with ground truth information, human-perceived flow in natural scenes remains underexplored. We introduce HuPerFlow—a benchmark for human-perceived flow, measured at 2,400 locations across ten optical flow datasets, with \~38,400 response vectors collected through online psychophysical experiments. Our data demonstrate that human-perceived flow aligns with ground truth in spatiotemporally smooth locations while also showing systematic errors influenced by various environmental properties. Additionally, we evaluated several optical flow algorithms against human-perceived flow, uncovering both similarities and unique aspects of human perception in complex natural scenes. HuPerFlow is the first large-scale human-perceived flow benchmark for alignment between computer vision models and human perception, as well as for scientific exploration of human motion perception in natural scenes. The HuPerFlow benchmark will be available online upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. Our model, for the first time, demonstrates the generation of 1024x1024 px images on a mobile device in 1.2 to 2.3 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Pairwise pose estimation from images with little or no overlap is an open challenge in computer vision. Existing methods, even those trained on large-scale datasets, struggle in these scenarios due to the lack of identifiable correspondences or visual overlap. Inspired by the human ability to infer spatial relationships from diverse scenes, we propose a novel approach that leverages the rich priors encoded within pre-trained generative video models. We propose to use a video model to hallucinate intermediate frames between two input images, effectively creating a dense, visual transition, which significantly simplifies the problem of pose estimation.Since current video models can still produce implausible motion or inconsistent geometry, we introduce a self-consistency score that evaluates the consistency of pose predictions from sampled videos.We demonstrate that our approach generalizes among three state-of-the-art video models and show consistent improvements over the state-of-the-art DUSt3R baseline on four diverse datasets encompassing indoor, outdoor, and object-centric scenes.Our findings suggest a promising avenue for improving pose estimation models by leveraging large generative models trained on vast amounts of video data, which is more readily available than 3D data.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
With the rapid evolution of 3D generation algorithms, the cost of producing 3D humanoid character models has plummeted, yet the field is impeded by the lack of a comprehensive dataset for automatic rigging—a pivotal step in character animation. Addressing this gap, we present HumanRig, the first large-scale dataset specifically designed for 3D humanoid character rigging, encompassing 11,434 meticulously curated T-posed meshes adhered to a uniform skeleton topology. Capitalizing on this dataset, we introduce an innovative, data-driven automatic rigging framework, which overcomes the limitations of GNN-based methods in handling complex AI-generated meshes. Our approach integrates a Prior-Guided Skeleton Estimator (PGSE) module, which uses 2D skeleton joints to provide a preliminary 3D skeleton, and a Mesh-Skeleton Mutual Attention Network (MSMAN) that fuses skeleton features with 3D mesh features extracted by a U-shaped point transformer. This enables a coarse-to-fine 3D skeleton joint regression and a robust skinning estimation, surpassing previous methods in quality and versatility. This work not only remedies the dataset deficiency in rigging research but also propels the animation industry towards more efficient and automated character rigging pipelines.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
When discussing the Aerial-Ground Person Re-identification (AGPReID) task, we face the main challenge of the significant appearance variations caused by different viewpoints, making identity matching difficult. To address this issue, previous methods attempt to reduce the differences between viewpoints by critical attributes and decoupling the viewpoints. While these methods can mitigate viewpoint differences to some extent, they still face two main issues: (1) difficulty in handling viewpoint diversity and (2) neglect of the contribution of local features. To effectively address these challenges, we design and implement the Self-Calibrating and Adaptive Prompt (SeCap) method for the AGPReID task. The core of this framework relies on the Prompt Re-calibration Module (PRM), which adaptively re-calibrates prompts based on the input. Combined with the Local Feature Refinement Module (LFRM), SeCap can extract view-invariant features from local features for AGPReID. Meanwhile, given the current scarcity of datasets in the AGPReID field, we further contribute two real-world Large-scale Aerial-Ground Person Re-Identification datasets, LAGPeR and G2APS-ReID. The former is collected and annotated by us independently, covering 4,231 unique identities and containing 63,841 high-quality images; the latter is reconstructed from the person search dataset G2APS. Through extensive experiments on AGPReID datasets, we demonstrate that SeCap is a feasible …
|
|
Highlight
|
Poster
[ ExHall D ] 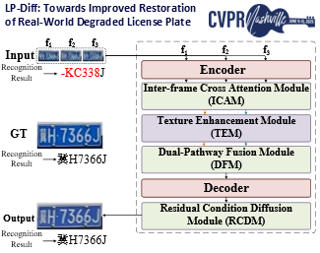
Abstract
License plate (LP) recognition is crucial in intelligent traffic management systems. However, factors such as long distances and poor camera quality often lead to severe degradation of captured LP images, posing challenges to accurate recognition. The design of License Plate Image Restoration (LPIR) methods frequently relies on synthetic degraded data, which limits their effectiveness on real-world severely degraded LP images. To address this issue, we introduce the first paired LPIR dataset collected in real-world scenarios, named MDLP, including 10,245 pairs of multi-frame severely degraded LP images and their corresponding clear images. To better restore severely degraded LP, we propose a novel Diffusion-based network, called LP-Diff, to tackle real-world LPIR tasks. Our approach incorporates (1) an Inter-frame Cross Attention Module to fuse temporal information across multiple frames, (2) a Texture Enhancement Module to restore texture information in degraded images, and (3) a Dual-Pathway Fusion Module to select effective features from both channel and spatial dimensions. Extensive experiments demonstrate the reliability of our dataset for model training and evaluation. Our proposed LP-Diff consistently outperforms other state-of-the-art image restoration methods on real-world LPIR tasks. Our dataset and code will be released after the paper is accepted to facilitate reproducibility and future research.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Inspired by the success of generative image models, recent work on learned image compression increasingly focuses on better probabilistic models of the natural image distribution, leading to excellent image quality. This, however, comes at the expense of a computational complexity that is several orders of magnitude higher than today's commercial codecs, and thus prohibitive for most practical applications. With this paper, we demonstrate that by focusing on modeling visual perception rather than the data distribution, we can achieve a very good trade-off between visual quality and bit rate similar to "generative" compression models such as HiFiC, while requiring less than 1% of the multiply–accumulate operations (MACs) for decompression. We do this by optimizing C3, an overfitted image codec, for Wasserstein Distortion (WD), and evaluating the image reconstructions with a human rater study. The study also reveals that WD outperforms other perceptual quality metrics such as LPIPS, DISTS, and MS-SSIM, both as an optimization objective and as a predictor of human ratings, achieving over 94% Pearson correlation with Elo scores.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
While automatically generated polynomial elimination templates have sparked great progress in the field of 3D computer vision, there remain many problems for which the degree of the constraints or the number of unknowns leads to intractability. In recent years, homotopy continuation has been introduced as a plausible alternative. However, the method currently depends on expensive parallel tracking of all possible solutions in the complex domain, or a classification network for starting problem-solution pairs trained over a limited set of real-world examples. Our innovation lies in a novel approach to finding solution-problem pairs, where we only need to predict a rough initial solution, with the corresponding problem generated by an online simulator. Subsequently, homotopy continuation is applied to track that single solution back to the original problem. We apply this elegant combination to generalized camera resectioning, and also introduce a new solution to the challenging generalized relative pose and scale problem. As demonstrated, the proposed method successfully compensates the raw error committed by the regressor alone, and leads to state-of-the-art efficiency and success rates.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Geospatial models must adapt to the diversity of Earth observation data in terms of resolutions, scales, and modalities. However, existing approaches expect fixed input configurations, which limits their practical applicability. We propose AnySat, a multimodal model based on joint embedding predictive architecture (JEPA) and resolution-adaptive spatial encoders, allowing us to train a single model on highly heterogeneous data in a self-supervised manner. To demonstrate the advantages of this unified approach, we compile GeoPlex, a collection of $5$ multimodal datasets with varying characteristics and $11$ distinct sensors. We then train a single powerful model on these diverse datasets simultaneously. Once fine-tuned, we achieve better or near state-of-the-art results on the datasets of GeoPlex and $3$ additional ones for $4$ environment monitoring tasks: land cover mapping, crop type classification, change detection, and forest analysis. We will release all codes, models, and data.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
3D Gaussian Splatting (3DGS) renders pixels by rasterizing Gaussian primitives, where the rendering resolution and the primitive number, concluded as the optimization complexity, dominate the time cost in primitive optimization. In this paper, we propose DashGaussian, a scheduling scheme over the optimization complexity of 3DGS that strips redundant complexity to accelerate 3DGS optimization. Specifically, we formulate 3DGS optimization as progressively fitting 3DGS to higher levels of frequency components in the training views, and propose a dynamic rendering resolution scheme that largely reduces the optimization complexity based on this formulation. Besides, we argue that a specific rendering resolution should cooperate with a proper primitive number for a better balance between computing redundancy and fitting quality, where we schedule the growth of the primitives to synchronize with the rendering resolution. Extensive experiments show that our method accelerates the optimization of various 3DGS backbones by 45.7% on average while preserving the rendering quality.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper considers the long-standing problem of extracting alpha mattes from video using a known background. While various color-based or polarization-based approaches have been studied in past decades, the problem remains ill-posed because the solutions solely rely on either color or polarization. We introduce Polarized Color Screen Matting, a single-shot, per-pixel matting theory for alpha matte and foreground color recovery using both color and polarization cues. Through a theoretical analysis of our diffuse-specular polarimetric compositing equation, we derive practical closed-form matting methods with their solvability conditions. Our theory concludes that an alpha matte can be extracted without manual corrections using off-the-shelf equipment such as an LCD monitor, polarization camera, and unpolarized lights with calibrated color. Experiments on synthetic and real-world datasets verify the validity of our theory and show the capability of our matting methods on real videos with quantitative and qualitative comparisons to color-based and polarization-based matting methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Good datasets are essential for developing and benchmarking any machine learning system. Their importance is even more extreme for safety critical applications such as deepfake detection---the focus of this paper. Here we reveal that two of the most widely used audio-video deepfake datasets suffer from a previously unidentified spurious feature: the leading silence. Fake videos start with a very brief moment of silence and based on this feature alone, we can separate the real and fake samples almost perfectly. As such, previous audio-only and audio-video models exploit the presence of silence in the fake videos and consequently perform worse when the leading silence is removed. To circumvent latching on such unwanted artifact and possibly other unrevealed ones we propose a shift from supervised to unsupervised learning by training models exclusively on real data. We show that by aligning self-supervised audio-video representations we remove the risk of relying on dataset-specific biases and improve robustness in deepfake detection.
|
|
Highlight
|
Poster
[ ExHall D ] 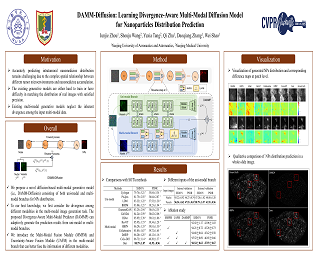
Abstract
The prediction of nanoparticles (NPs) distribution is crucial for the diagnosis and treatment of tumors. Recent studies indicate that the heterogeneity of tumor microenvironment (TME) highly affects the distribution of NPs across tumors. Hence, it has become a research hotspot to generate the NPs distribution by the aid of multi-modal TME components. However, the distribution divergence among multi-modal TME components may cause side effects i.e., the best uni-modal model may outperform the joint generative model. To address the above issues, we propose a \Divergence-Aware Multi-Modal Diffusion model (i.e., DAMM-Diffusion) to adaptively generate the prediction results from uni-modal and multi-modal branches in a unified network. In detail, the uni-modal branch is composed of the U-Net architecture while the multi-modal branch extends it by introducing two novel fusion modules i.e., Multi-Modal Fusion Module (MMFM) and Uncertainty-Aware Fusion Module (UAFM). Specifically, the MMFM is proposed to fuse features from multiple modalities, while the UAFM module is introduced to learn the uncertainty map for cross-attention computation. Following the individual prediction results from each branch, the Divergence-Aware Multi-Modal Predictor (DAMMP) module is proposed to assess the consistency of multi-modal data with the uncertainty map, which determines whether the final prediction results come from multi-modal or …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
For event cameras, current sparse geometric solvers for egomotion estimation assume that the rotational displacements are known, such as those provided by an IMU. Thus, they can only recover the translational motion parameters. Recovering full-DoF motion parameters using a sparse geometric solver is a more challenging task, and has not yet been investigated. In this paper, we propose several solvers to estimate both rotational and translational velocities within a unified framework. Our method leverages event manifolds induced by line segments. The problem formulations are based on either an incidence relation for lines or a novel coplanarity relation for normal vectors. We demonstrate the possibility of recovering full-DoF egomotion parameters for both angular and linear velocities without requiring extra sensor measurements or motion priors. To achieve efficient optimization, we exploit the Adam framework with a first-order approximation of rotations for quick initialization. Experiments on both synthetic and real-world data demonstrate the effectiveness of our method. The code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Sinusoidal neural networks have been shown effective as implicit neural representations (INRs) of low-dimensional signals, due to their smoothness and high representation capacity. However, initializing and training them remain empirical tasks which lack on deeper understanding to guide the learning process. To fill this gap, our work introduces a theoretical framework that explains the capacity property of sinusoidal networks and offers robust control mechanisms for initialization and training. Our analysis is based on a novel amplitude-phase expansion of the sinusoidal multilayer perceptron, showing how its layer compositions produce a large number of new frequencies expressed as integer combinations of the input frequencies. This relationship can be directly used to initialize the input neurons, as a form of spectral sampling, and to bound the network's spectrum while training. Our method, referred to as TUNER (TUNing sinusoidal nEtwoRks), greatly improves the stability and convergence of sinusoidal INR training, leading to detailed reconstructions, while preventing overfitting.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Text- or image-to-3D generators and 3D scanners can now produce 3D assets with high-quality shapes and textures. These assets typically consist of a single, fused representation, like an implicit neural field, a Gaussian mixture, or a mesh, without any useful structure.However, most applications and creative workflows require assets to be made of several meaningful parts that can be manipulated independently. To address this gap, we introduce ParGen, a novel approach that generates 3D objects composed of meaningful parts starting from text, an image, or an unstructured 3D object. First, given multiple views of a 3D object, generated or rendered, a multi-view diffusion model extracts a set of plausible and view-consistent part segmentations, dividing the object into parts. Then, a second multi-view diffusion model takes each part separately, fills in the occlusions, and uses those completed views for 3D reconstruction by feeding them to a 3D reconstruction network. This completion process considers the context of the entire object to ensure that the parts integrate cohesively. The generative completion model can make up for the information missing due to occlusions; in extreme cases, it can hallucinate entirely invisible parts based on the input 3D asset. We evaluate our method on generated and …
|
|
Highlight
|
Poster
[ ExHall D ] 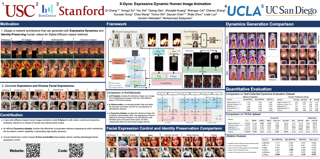
Abstract
We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key factors underlying the loss of dynamic details, enhancing the lifelike qualities of human video animations.At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos.Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Interactive segmentation is a pivotal task in computer vision, focused on predicting precise masks with minimal user input. Although the $ \textit{click}$ has recently become the most prevalent form of interaction due to its flexibility and efficiency, its advantages diminish as the complexity and details of target objects increase because it's time-consuming and user-unfriendly to precisely locate and click on narrow, fine regions. To tackle this problem, we propose NTClick, a powerful click-based interactive segmentation method capable of predicting accurate masks even with imprecise user clicks when dealing with intricate targets. We first introduce a novel interaction form called $ \textit{Noist-tolerant Click}$, a type of click that does not require user's precise localization when selecting fine regions. Then, we design a two-stage workflow, consisting of an Explicit Coarse Perception network for initial estimation and a High Resolution Refinement network for final classification. Quantitative results across extensive datasets demonstrate that NTClick not only maintains an efficient and flexible interaction mode but also significantly outperforms existing methods in segmentation accuracy.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper tackles category-level pose estimation of articulated objects in robotic manipulation tasks and introduces a new benchmark dataset. While recent methods estimate part poses and sizes at the category level, they often rely on geometric cues and complex multi-stage pipelines that first segment parts from the point cloud, followed by Normalized Part Coordinate Space (NPCS) estimation for 6D poses. These approaches overlook dense semantic cues from RGB images, leading to suboptimal accuracy, particularly for objects with small parts. To address these limitations, we propose a single-stage Network, CAP-Net, for estimating the 6D poses and sizes of Categorical Articulated Parts. This method combines RGB-D features to generate instance segmentation and NPCS representations for each part in an end-to-end manner. CAP-Net uses a unified network to simultaneously predict point-wise class labels, centroid offsets, and NPCS maps. A clustering algorithm then groups points of the same predicted class based on their estimated centroid distances to isolate each part. Finally, the NPCS region of each part is aligned with the point cloud to recover its final pose and size.To bridge the sim-to-real domain gap, we introduce the RGBD-Art dataset, the largest RGB-D articulated dataset to date, featuring photorealistic RGB images and depth noise …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Readout multiplexing is a promising solution to overcome hardware limitations and data bottlenecks in imaging with single-photon detectors. Conventional multiplexed readout processing creates an upper bound on photon counts at a very fine time scale, where measurements with multiple detected photons must either be discarded or allowed to introduce significant bias. We formulate multiphoton coincidence resolution as an inverse imaging problem and introduce a solution framework to probabilistically resolve the spatial locations of photon incidences. Specifically, we develop a theoretical abstraction of row--column multiplexing and a model of photon events that make readouts ambiguous. Using this, we propose a novel estimator that spatially resolves up to four coincident photons. Our estimator achieves a 3 to 4 dB increase in the peak signal-to-noise ratio of image reconstruction compared to traditional methods at higher incidence photon fluxes. Additionally, this method achieves a ~4 reduction in the required number of readout frames to achieve the same mean-squared error as other methods. Finally, our solution matches the Cramer-Rao bound for detection probability estimation for a wider range of incident flux values compared to conventional methods. While demonstrated for a specific detector type and readout architecture, this method can be extended to more general multiplexing …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper presents a unified approach to understanding dynamic scenes from casual videos. Large pretrained vision models, such as vision-language, video depth prediction, motion tracking, and segmentation models, offer promising capabilities. However, training a single model for comprehensive 4D understanding remains challenging. We introduce Uni4D, a multi-stage optimization framework that harnesses multiple pretrained models to advance dynamic 3D modeling, including static/dynamic reconstruction, camera pose estimation, and dense 3D motion tracking. Our results show state-of-the-art performance in dynamic 4D modeling with superior visual quality. Notably, Uni4D requires no retraining or fine-tuning, highlighting the effectiveness of repurposing large visual models for 4D understanding.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Pedestrian attribute recognition (PAR) seeks to predict multiple semantic attributes associated with a specific pedestrian. There are two types of approaches for PAR: unimodal framework and bimodal framework. The former one is to seek a robust visual feature. However, the lack of exploiting semantic feature of linguistic modality is the main concern. The latter one adopts utilizes prompt learning techniques to integrate linguistic data. However, static prompt templates and simple bimodal concatenation cannot to capture the extensive intra-class attribute variability and support active modalities collaboration. In this paper, we propose an Enhanced Visual-Semantic Interaction with Tailored Prompts (EVSITP) framework for PAR. We present an Image-Conditional Dual-Prompt Initialization Module (IDIM) to adaptively generate context-sensitive prompts from visual inputs. Subsequently, a Prompt Enhanced and Regularization Module (PERM) is proposed to strengthen linguistic information from IDIM. We further design a Bimodal Mutual Interaction Module (BMIM) to ensure bidirectional modalities communication. In addition, existing PAR datasets are collected over a short period in limited scenarios, which do not align with real-world scenarios. Therefore, we annotate a long-term person re-identification dataset to create a new PAR dataset, Celeb-PAR. Experiments on several challenging PAR datasets show that our method outperforms state-of-the-art approaches.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this paper, we introduce MeshGen, an advanced image-to-3D pipeline that generates high-quality 3D meshes with detailed geometry and physically based rendering (PBR) textures. Addressing the challenges faced by existing 3D native diffusion models, such as suboptimal auto-encoder performance, limited controllability, poor generalization, and inconsistent image-based PBR texturing, MeshGen employs several key innovations to overcome these limitations. We pioneer a render-enhanced point-to-shape auto-encoder that compresses meshes into a compact latent space, by designing perceptual optimization with ray-based regularization. This ensures that the 3D shapes are accurately represented and reconstructed to preserve geometric details within the latent space. To address data scarcity and image-shape misalignment, we further propose geometric augmentation and generative rendering augmentation techniques, which enhance the model's controllability and generalization ability, allowing it to perform well even with limited public datasets. For texture generation, MeshGen employs a reference attention-based multi-view ControlNet for consistent appearance synthesis. This is further complemented by our multi-view PBR decomposer that estimates PBR components and a UV inpainter that fills invisible areas, ensuring a seamless and consistent texture across the 3D mesh. Our extensive experiments demonstrate that MeshGen largely outperforms previous methods in both shape and texture generation, setting a new standard for the quality …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Contrastive loss is a powerful approach for representation learning, where larger batch sizes enhance performance by providing more negative samples to better distinguish between similar and dissimilar data. However, the full instantiation of the similarity matrix demands substantial GPU memory, making large batch training highly resource-intensive. To address this, we propose a tile-based computation strategy that partitions the contrastive loss calculation into small blocks, avoiding full materialization of the similarity matrix. Additionally, we introduce a multi-level tiling implementation to leverage the hierarchical structure of distributed systems, using ring-based communication at the GPU level to optimize synchronization and fused kernels at the CUDA core level to reduce I/O overhead. Experimental results show that the proposed method significantly reduces GPU memory usage in contrastive loss. For instance, it enables contrastive training of a CLIP-ViT-L/14 model with a batch size of 4M using only 8 A800 80GB GPUs, without sacrificing accuracy. Compared to state-of-the-art memory-efficient solutions, it achieves a two-order-of-magnitude reduction in memory while maintaining comparable speed. The code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent efforts recognize the power of scale in 3D learning (e.g. PTv3) and attention mechanisms (e.g. FlashAttention).However, current point cloud backbones fail to holistically unify geometric locality, attention mechanisms, and GPU architectures in one view.In this paper, we introduce $\textbf{Flash3D Transformer}$, which aligns geometric locality and GPU tiling through a principled locality mechanism based on Perfect Spatial Hashing (PSH).The common alignment with GPU tiling naturally fuses our PSH locality mechanism with FlashAttention at negligible extra cost.This mechanism affords flexible design choices throughout the backbone that result in superior downstream task results.Flash3D outperforms state-of-the-art PTv3 results on benchmark datasets, delivering a 2.25x speed increase and 2.4x memory efficiency boost. This efficiency enables scaling to wider attention scopes and larger models without additional overhead.Such scaling allows Flash3D to achieve even higher task accuracies than PTv3 under the same compute budget.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Depth estimation is a fundamental task in 3D vision. An ideal depth estimation model is expected to embrace meticulous detail, temporal consistency, and high efficiency. Although existing foundation models can perform well in certain specific aspects, most of them fall short of fulfilling all the above requirements simultaneously. In this paper, we present CH$_3$Depth, an efficient and flexible model for depth estimation with flow matching to address this challenge. Specifically, 1) we reframe the optimization objective of flow matching as a scale-variable velocity field to improve accuracy. 2) To enhance efficiency, we propose non-uniform sampling to achieve better prediction with fewer sampling steps. 3) We design the Latent Temporal Stabilizer (LTS) to enhance temporal consistency by aggregating latent codes of adjacent frames, enabling our method to be lightweight and compatible for video depth estimation. CH$_3$Depth achieves state-of-the-art performance in zero-shot evaluations across multiple image and video datasets, excelling in prediction accuracy, efficiency, and temporal consistency, highlighting its potential as the next foundation model for depth estimation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually …
|
|
Highlight
|
Poster
[ ExHall D ] 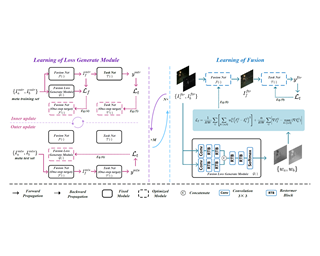
Abstract
Multi-modal image fusion aggregates information from multiple sensor sources, achieving superior visual quality and perceptual characteristics compared to any single source, often enhancing downstream tasks. However, current fusion methods for downstream tasks still use predefined fusion objectives that potentially mismatch the downstream tasks, limiting adaptive guidance and reducing model flexibility.To address this, we propose Task-driven Image Fusion (TDFusion), a fusion framework incorporating a learnable fusion loss guided by task loss. Specifically, our fusion loss includes learnable parameters modeled by a neural network called the loss generation module. This module is supervised by the loss of downstream tasks in a meta-learning manner.The learning objective is to minimize the task loss of the fused images, once the fusion module has been optimized by the fusion loss.Iterative updates between the fusion module and the loss module ensure that the fusion network evolves toward minimizing task loss, guiding the fusion process toward the task objectives.TDFusion’s training relies solely on the loss of downstream tasks, making it adaptable to any specific task.It can be applied to any architecture of fusion and task networks.Experiments demonstrate TDFusion’s performance in both fusion and task-related applications, including four public fusion datasets, semantic segmentation, and object detection.The code will be …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Transformer-based large pre-trained models have shown remarkable generalization ability, and various parameter-efficient fine-tuning (PEFT) methods have been proposed to customize these models on downstream tasks with minimal computational and memory budgets. Previous PEFT methods are primarily designed from a tensor-decomposition perspective that tries to effectively tune the linear transformation by finding the smallest subset of parameters to train. Our study adopts an orthogonal view by representing the attention operation as a graph convolution and formulating the multi-head attention maps as a convolutional filter subspace, with each attention map as a subspace element. In this paper, we propose to tune the large pre-trained transformers by learning a small set of combination coefficients that construct a more expressive filter subspace from the original multi-head attention maps. We show analytically and experimentally that the tuned filter subspace can effectively expand the feature space of the multi-head attention and further enhance the capacity of transformers. We further stabilize the fine-tuning with a residual parameterization of the tunable subspace coefficients, and enhance the generalization with a regularization design by directly applying dropout on the tunable coefficient during training. The tunable coefficients take a tiny number of parameters and can be combined with previous PEFT methods …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recently, learning signed distance functions (SDFs) from point clouds has become popular for reconstruction. To ensure accuracy, most methods require using high-resolution Marching Cubes for surface extraction. However, this results in redundant mesh elements, making the mesh inconvenient to use. To solve the problem, we propose an adaptive meshing method to extract resolution-adaptive meshes based on surface curvature, enabling the recovery of high-fidelity lightweight meshes. Specifically, we first use point-based representation to perceive implicit surfaces and calculate surface curvature. A vertex generator is designed to produce curvature-adaptive vertices with any specified number on the implicit surface, preserving the overall structure and high-curvature features. Then we develop a Delaunay meshing algorithm to generate meshes from vertices, ensuring geometric fidelity and correct topology. In addition, to obtain accurate SDFs for adaptive meshing and achieve better lightweight reconstruction, we design a hybrid representation combining feature grid and feature tri-plane for better detail capture. Experiments demonstrate that our method can generate high-quality lightweight meshes from point clouds. Compared with methods from various categories, our approach achieves superior results, especially in capturing more details with fewer elements.
|
|
Highlight
|
Do Computer Vision Foundation Models Learn the Low-level Characteristics of the Human Visual System?
Poster
[ ExHall D ] 
Abstract
Computer vision foundation models, such as DINO or OpenCLIP, are trained in a self-supervised manner on large image datasets. Analogously, substantial evidence suggests that the human visual system (HVS) is influenced by the statistical distribution of colors and patterns in the natural world, characteristics also present in the training data of foundation models. The question we address in this paper is whether foundation models trained on natural images mimic some of the low-level characteristics of the human visual system, such as contrast detection, contrast masking, and contrast constancy. Specifically, we designed a protocol comprising nine test types to evaluate the image encoders of 45 foundation and generative models. Our results indicate that some foundation models (e.g., DINO, DINOv2, and OpenCLIP), share some of the characteristics of human vision, but other models show little resemblance. Foundation models tend to show smaller sensitivity to low contrast and rather irregular responses to contrast across frequencies. The foundation models show the best agreement with human data in terms of contrast masking. Our findings suggest that human vision and computer vision may take both similar and different paths when learning to interpret images of the real world. Overall, while differences remain, foundation models trained on …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present Light3R-SfM, a feed-forward, end-to-end learnable framework for efficient large-scale Structure-from-Motion (SfM) from unconstrained image collections. Unlike existing SfM solutions that rely on costly matching and global optimization to achieve accurate 3D reconstructions, Light3R-SfM addresses this limitation through a novel latent global alignment module. This module replaces traditional global optimization with a learnable attention mechanism, effectively capturing multi-view constraints across images for robust and precise camera pose estimation. Light3R-SfM constructs a sparse scene graph via retrieval-score-guided shortest path tree to dramatically reduce memory usage and computational overhead compared to the naive approach. Extensive experiments demonstrate that Light3R-SfM achieves competitive accuracy while significantly reducing runtime, making it ideal for 3D reconstruction tasks in real-world applications with a runtime constraint. This work pioneers a data-driven, feed-forward SfM approach, paving the way toward scalable, accurate, and efficient 3D reconstruction in the wild.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce Olympus, a new approach that transforms Multimodal Large Language Models (MLLMs) into a unified framework capable of handling a wide array of computer vision tasks. Utilizing a controller MLLM, Olympus delegates over 20 specialized tasks across images, videos, and 3D objects to dedicated modules. This instruction-based routing enables complex workflows through chained actions without the need for training heavy generative models. Olympus easily integrates with existing MLLMs, expanding their capabilities with comparable performance. Experimental results demonstrate that Olympus achieves an average routing accuracy of 94.75% across 20 tasks and precision of 91.82% in chained action scenarios, showcasing its effectiveness as a universal task router that can solve a diverse range of computer vision tasks.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce the task of predicting functional 3D scene graphs for real-world indoor environments from posed RGB-D images. Unlike traditional 3D scene graphs that focus on spatial relationships of objects, functional 3D scene graphs capture objects, interactive elements, and their functional relationships. Due to the lack of training data, we leverage foundation models, including visual language models (VLMs) and large language models (LLMs), to encode functional knowledge. We evaluate our approach on an extended SceneFun3D dataset and a newly collected dataset, FunGraph3D, both annotated with functional 3D scene graphs. Our method significantly outperforms adapted baselines, including Open3DSG and ConceptGraph, demonstrating its effectiveness in modeling complex scene functionalities. We also demonstrate downstream applications such as 3D question answering and robotic manipulation using functional 3D scene graphs.
|
|
Highlight
|
Poster
[ ExHall D ] 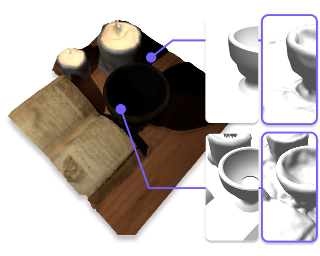
Abstract
3D surface reconstruction is essential across applications of virtual reality, robotics, and mobile scanning. However, RGB-based reconstruction often fails in low-texture, low-light, and low-albedo scenes. Handheld LiDARs, now common on mobile devices, aim to address these challenges by capturing depth information from time-of-flight measurements of a coarse grid of projected dots. Yet, these sparse LiDARs struggle with scene coverage on limited input views, leaving large gaps in depth information. In this work, we propose using an alternative class of "blurred" LiDAR that emits a diffuse flash, greatly improving scene coverage but introducing spatial ambiguity from mixed time-of-flight measurements across a wide field of view. To handle these ambiguities, we propose leveraging the complementary strengths of diffuse LiDAR with RGB. We introduce a Gaussian surfel-based rendering framework with a scene-adaptive loss function that dynamically balances RGB and diffuse LiDAR signals. We demonstrate that, surprisingly, diffuse LiDAR can outperform traditional sparse LiDAR, enabling robust 3D scanning with accurate color and geometry estimation in challenging environments.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (more than 3.7M images) of multi-view RGB/monochrome image streams showing 19 subjects interacting with 33 diverse rigid objects, multi-modal signals such as eye gaze or scene point clouds, as well as comprehensive ground truth annotations including 3D poses of objects, hands, and cameras, and 3D models of hands and objects. In addition to simple pick-up/observe/put-down actions, HOT3D contains scenarios resembling typical actions in a kitchen, office, and living room environment. The dataset is recorded by two head-mounted devices from Meta: Project Aria, a research prototype of light-weight AR/AI glasses, and Quest 3, a production VR headset sold in millions of units. Ground-truth poses were obtained by a professional motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The field of diffusion-based 3D generation has experienced tremendous progress in recent times. However, existing 3D generative models often produce overly dense and unstructured meshes, which are in stark contrast to the compact, structured and clear-edged CAD models created by human modelers. We introduce CADDreamer, a novel method for generating CAD objects from a single image. This method proposes a primitive-aware multi-view diffusion model, which perceives both local geometry and high-level structural semantics during the generation process. We encode primitive semantics into the color domain, and enforce the strong priors in pre-trained diffusion models to align with the well-defined primitives. As a result, we can infer multi-view normal maps and semantic maps from a single image, thereby reconstructing a mesh with primitive labels. Correspondingly, we propose a set of fitting and optimization methods to deal with the inevitable noise and distortion in generated primitives, ultimately producing a complete and seamless Boundary Representation (B-rep) of a Computer-Aided Design (CAD) model. Experimental results demonstrate that our method can effectively recover high-quality CAD objects from single-view images. Compared to existing 3D generation methods, the models produced by CADDreamer are compact in representation, clear in structure, sharp in boundaries, and watertight in topology.
|
|
Highlight
|
Poster
[ ExHall D ] 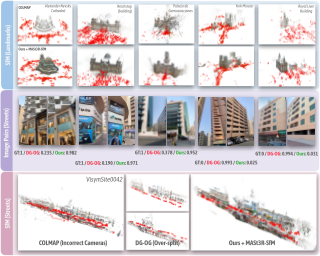
Abstract
Accurate 3D reconstruction is frequently hindered by visual aliasing, where visually similar but distinct surfaces (aka, doppelgangers), are incorrectly matched. These spurious matches distort the structure-from-motion (SfM) process, leading to misplaced model elements and reduced accuracy. Prior efforts addressed this with CNN classifiers trained on curated datasets, but these approaches struggle to generalize across diverse real-world scenes and can require extensive parameter tuning. In this work, we present Doppelgangers++, a method to enhance doppelganger detection and improve 3D reconstruction accuracy. Our contributions include a diversified training dataset that incorporates geo-tagged images from everyday scenes to expand robustness beyond landmark-based datasets. We further propose a Transformer-based classifier that leverages 3D-aware features from the MASt3R model, achieving superior precision and recall across both in-domain and out-of-domain tests. Doppelgangers++ integrates seamlessly into standard SfM and MASt3R-SfM pipelines, offering efficiency and adaptability across varied scenes. To evaluate SfM accuracy, we introduce an automated, geotag-based method for validating reconstructed models, eliminating the need for manual inspection. Through extensive experiments, we demonstrate that Doppelgangers++ significantly enhances pairwise visual disambiguation and improves 3D reconstruction quality in complex and diverse scenarios.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Reconstructing the geometry and appearance of objects from photographs taken in different environments is difficult as the illumination and therefore the object appearance vary across captured images. This is particularly challenging for more specular objects whose appearance strongly depends on the viewing direction. Some prior approaches model appearance variation across images using a per-image embedding vector, while others use physically-based rendering to recover the materials and per-image illumination. Such approaches fail at faithfully recovering view-dependent appearance given significant variation in input illumination and tend to produce mostly diffuse results. We present an approach that reconstructs objects from images taken under different illuminations by first relighting the images under a single reference illumination with a multiview relighting diffusion model and then reconstructing the object's geometry and appearance with a radiance field architecture that is robust to the small remaining inconsistencies among the relit images. We validate our proposed approach on both simulated and real datasets and demonstrate that it greatly outperforms existing techniques at reconstructing high-fidelity appearance from images taken under extreme illumination variation. Moreover, our approach is particularly effective at recovering view-dependent ``shiny'' appearance which cannot be reconstructed by prior methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper addresses the challenge that current event-based video reconstruction methods cannot produce static background information. Recent research has uncovered the potential of event cameras in capturing static scenes. Nonetheless, image quality deteriorates due to noise interference and detail loss, failing to provide reliable background information. We propose a two-stage reconstruction strategy to address these challenges and reconstruct static scene images comparable to frame cameras. Building on this, we introduce the URSEE framework, the first unified framework designed for reconstructing motion videos with static backgrounds. This framework includes a parallel channel that can simultaneously process static and dynamic events, and a network module designed to reconstruct videos encompassing both static and dynamic scenes in an end-to-end manner. We also collect a real-captured dataset for static reconstruction, containing both indoor and outdoor scenes. Comparison results indicate that the proposed approach achieves state-of-the-art reconstruction results on both synthetic and real data.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
While flourishing developments have been witnessed in text-to-motion generation, synthesizing physically realistic, controllable, language-conditioned Human Scene Interactions (HSI) remains a relatively underexplored landscape. Current HSI methods naively rely on conditional Variational AutoEncoder (cVAE) and diffusion models. They are typically associated with \textbf{limited modalities of control signals} and \textbf{task-specific frameworks design}, leading to inflexible adaptation across various interaction scenarios and descriptive-unfaithful motions in diverse 3D physical environments. In this paper, we propose HSI-GPT, a General-Purpose \textbf{Large Scene-Motion-Language Model} that applies ``next-token prediction'' paradigm of Large Language Models to the HSI domain. HSI-GPT not only exhibits remarkable flexibility to accommodate diverse control signals (3D scenes, textual commands, key-frame poses, as well as scene affordances), but it seamlessly supports various HSI-related tasks (\textit{e.g}., multi-modal controlled HSI generation, HSI understanding, and general motion completion in 3D scenes). First, HSI-GPT quantizes textual descriptions and human motions into discrete, LLM-interpretable tokens with multi-modal tokenizers. Inspired by multi-modal learning, we develop a recipe for aligning mixed-modality tokens into the shared embedding space of LLMs. These interaction tokens are then organized into unified instruction following prompts, allowing our HSI-GPT to fine-tune on prompt-based question-and-answer tasks. Extensive experiments and visualizations validate that our general-purpose HSI-GPT model delivers exceptional performance …
|
|
Highlight
|
Poster
[ ExHall D ] 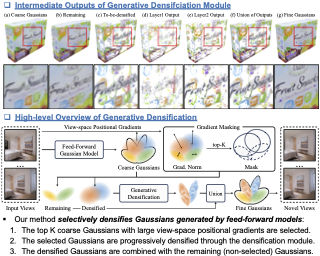
Abstract
Generalized feed-forward Gaussian models have shown remarkable progress in sparse-view 3D reconstruction, leveraging prior knowledge learned from large multi-view datasets. However, these models often struggle to represent high-frequency details due to the limited number of generated Gaussians. While the densification strategy used in per-scene 3D Gaussian splatting (3D-GS) optimization can be extended and applied to the feed-forward models, it may not be ideally suited for generalized settings. In this paper, we present Generative Densification, an efficient and generalizable densification strategy that can selectively generate fine Gaussians for high-fidelity 3D reconstruction. Unlike the 3D-GS densification strategy, we densify the feature representations from the feed-forward models rather than the raw Gaussians, making use of the prior knowledge embedded in the features for enhanced generalization. Experimental results demonstrate the effectiveness of our approach, achieving the state-of-the-art rendering quality in both object-level and scene-level reconstruction, with noticeable improvements in representing fine details.
|
|
Highlight
|
Poster
[ ExHall D ] 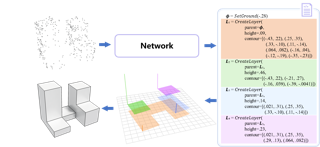
Abstract
We introduce ArcPro, a novel learning framework built on architectural programs to recover structured 3D abstractions from highly sparse and low-quality point clouds. Specifically, we design a domain-specific language (DSL) to hierarchically represent building structures as a program, which can be efficiently converted into a mesh. We bridge feedforward and inverse procedural modeling by using a feedforward process for training data synthesis, allowing the network to make reverse predictions. We train an encoder-decoder on the points-program pairs to establish a mapping from unstructured point clouds to architectural programs, where a 3D convolutional encoder extracts point cloud features and a transformer decoder autoregressively predicts the programs in a tokenized form. Inference by our method is highly efficient and produces plausible and faithful 3D abstractions. Comprehensive experiments demonstrate that ArcPro outperforms both traditional architectural proxy reconstruction and learning-based abstraction methods. We further explore its potential when working with multi-view image and natural language inputs.
|
|
Highlight
|
Poster
[ ExHall D ] 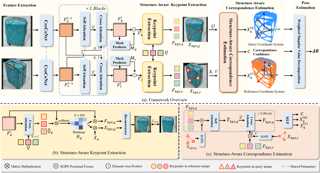
Abstract
Relative pose estimation provides a promising way for achieving object-agnostic pose estimation. Despite the success of existing 3D correspondence-based methods, the reliance on explicit feature matching suffers from small overlaps in visible regions and unreliable feature estimation for invisible regions. Inspired by humans' ability to assemble two object parts that have small or no overlapping regions by considering object structure, we propose a novel Structure-Aware Correspondence Learning method for Relative Pose Estimation, which consists of two key modules. First, a structure-aware keypoint extraction module is designed to locate a set of kepoints that can represent the structure of objects with different shapes and appearance, under the guidance of a keypoint based image reconstruction loss. Second, a structure-aware correspondence estimation module is designed to model the intra-image and inter-image relationships between keypoints to extract structure-aware features for correspondence estimation. By jointly leveraging these two modules, the proposed method can naturally estimate 3D-3D correspondences for unseen objects without explicit feature matching for precise relative pose estimation. Experimental results on the CO3D, Objaverse and LineMOD datasets demonstrate that the proposed method significantly outperforms prior methods, i.e., with $5.7^\circ$ reduction in mean angular error on the CO3D dataset.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Generalist vision language models (VLMs) have made significant strides in computer vision, but they fall short in specialized fields like healthcare, where expert knowledge is essential. Current large multimodal models like Gemini and GPT-4o are insufficient for medical tasks due to their reliance on memorized internet knowledge rather than the nuanced expertise required in healthcare. Meanwhile, existing medical VLMs (e.g. Med-Gemini) often lack expert consultation as part of their design, and many rely on outdated, static datasets that were not created with modern, large deep learning models in mind. VLMs are usually trained in three stages: vision pre-training, vision-language pre-training, and instruction fine-tuning (IFT). IFT has been typically applied using a mixture of generic and healthcare data. In contrast, we propose that for medical VLMs, a fourth stage of specialized IFT is necessary, which focuses on medical data and includes information from domain expert models. Domain expert models developed for medical use are crucial because they are specifically trained for certain clinical tasks, e.g. to detect tumors and classify abnormalities through segmentation and classification, which learn fine-grained features of medical data$-$features that are often too intricate for a VLM to capture effectively. This paper introduces a new framework, VILA-M3, for …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Domain generalization (DG) aims to adapt a model using one or multiple source domains to ensure robust performance in unseen target domains. Recently, Parameter-Efficient Fine-Tuning (PEFT) of foundation models has shown promising results in the context of DG problem. Nevertheless, existing PEFT methods still struggle to strike a balance between preserving generalizable components of the pre-trained model and learning task-specific features. To gain insights into the distribution of generalizable components, we begin by analyzing the pre-trained weights through the lens of singular value decomposition. Building on these insights, we introduce Singular Value Decomposed Low-Rank Adaptation (SoRA), an approach that selectively tunes minor singular components while keeping the residual parts frozen. SoRA effectively retains the generalization ability of the pre-trained model while efficiently acquiring task-specific skills. Furthermore, we freeze domain-generalizable blocks and employ an annealing weight decay strategy, thereby achieving an optimal balance in the delicate trade-off between generalizability and discriminability. SoRA attains state-of-the-art results on multiple benchmarks that span both domain generalized semantic segmentation to object detection. In addition, our methods introduce no additional inference overhead or regularization loss, maintain compatibility with any backbone or head, and are designed to be versatile, allowing easy integration into a wide range of …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this work, we propose an extreme compression technique for Large Multimodal Models (LMMs). While previous studies have explored quantization as an efficient post-training compression method for Large Language Models (LLMs), low-bit compression for multimodal models remains under-explored. The redundant nature of inputs in multimodal models results in a highly sparse attention matrix. We theoretically and experimentally demonstrate that the attention matrix's sparsity bounds the compression error of the Query and Key weight matrices. Based on this, we introduce CASP, a model compression technique for LMMs. Our approach performs a data-aware low-rank decomposition on the Query and Key weight matrix, followed by quantization across all layers based on an optimal bit allocation process. CASP is compatible with any quantization technique and enhances state-of-the-art 2-bit quantization methods (AQLM and QuIP\#) by an average of 21% on image- and video-language benchmarks. The code is provided in the supplementary materials.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We consider indoor 3D object detection with respect to a single RGB(-D) frame acquired from a commodity handheld device. We seek to significantly advance the status quo with respect to both data and modeling. First, we establish that existing datasets have significant limitations to scale, accuracy, and diversity of objects. As a result, we introduce the **Cubify-Anything 1M (CA-1M) dataset**, which exhaustively labels over 400K 3D objects on over 1K highly accurate laser-scanned scenes with near-perfect registration to over 3.5K handheld, egocentric captures. Next, we establish **Cubify Transformer (CuTR)**, a fully Transformer 3D object detection baseline which rather than operating in 3D on point or voxel-based representations, predicts 3D boxes directly from 2D features derived from RGB(-D) inputs. While this approach lacks any 3D inductive biases, we show that paired with CA-1M, CuTR outperforms point-based methods on CA-1M - accurately recalling over 62% of objects in 3D, and is significantly more capable at handling noise and uncertainty present in commodity LiDAR-derived depth maps while also providing promising RGB only performance without architecture changes. Furthermore, by pre-training on CA-1M, CuTR can outperform point-based methods on a more diverse variant of SUN RGB-D - supporting the notion that while inductive biases in …
|
|
Highlight
|
Poster
[ ExHall D ] 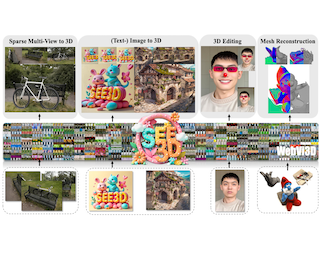
Abstract
Recent 3D generation models typically rely on limited-scale 3D `gold-labels' or 2D diffusion priors for 3D content creation. However, their performance is upper-bounded by constrained 3D priors due to the lack of scalable learning paradigms. In this work, we present See3D, a visual-conditional multi-view diffusion model trained on large-scale Internet videos for open-world 3D creation. The model aims to Get 3D knowledge by solely Seeing the visual contents from the vast and rapidly growing video data --- You See it, You Got it. To achieve this, we first scale up the training data using a proposed data curation pipeline that automatically filters out multi-view inconsistencies and insufficient observations from source videos. This results in a high-quality, richly diverse, large-scale dataset of multi-view images, termed WebVi3D, containing 320M frames from 16M video clips. Nevertheless, learning generic 3D priors from videos without explicit 3D geometry or camera pose annotations is nontrivial, and annotating poses for web-scale videos is prohibitively expensive. To eliminate the need for pose conditions, we introduce an innovative visual-condition - a purely 2D-inductive visual signal generated by adding time-dependent noise to the masked video data. Finally, we introduce a novel visual-conditional 3D generation framework by integrating See3D into a …
|
|
Highlight
|
Poster
[ ExHall D ] 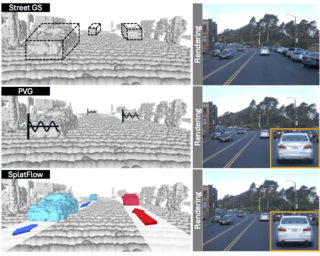
Abstract
Most existing Dynamic Gaussian Splatting methods for complex dynamic urban scenarios rely on accurate object-level supervision from expensive manual labeling, limiting their scalability in real-world applications. In this paper, we introduce SplatFlow, a Self-Supervised Dynamic Gaussian Splatting within Neural Motion Flow Fields (NMFF) to learn 4D space-time representations without requiring tracked 3D bounding boxes, enabling accurate dynamic scene reconstruction and novel view RGB/depth/flow synthesis. SplatFlow designs a unified framework to seamlessly integrate time-dependent 4D Gaussian representation within NMFF, where NMFF is a set of implicit functions to model temporal motions of both LiDAR points and Gaussians as continuous motion flow fields. Leveraging NMFF, SplatFlow effectively decomposes static background and dynamic objects, representing them with 3D and 4D Gaussian primitives, respectively.NMFF also models the status correspondences of each 4D Gaussian across time, which aggregates temporal features to enhance cross-view consistency of dynamic components. SplatFlow further improves dynamic scene identification by distilling features from 2D foundational models into 4D space-time representation. Comprehensive evaluations conducted on the Waymo Open Dataset and KITTI Dataset validate SplatFlow's state-of-the-art (SOTA) performance for both image reconstruction and novel view synthesis in dynamic urban scenarios. The code and model will be released upon the paper's acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recently, the diffusion model has emerged as a powerful generative technique for robotic policy learning, capable of modeling multi-mode action distributions. Leveraging its capability for end-to-end autonomous driving is a promising direction. However, the numerous denoising steps in the robotic diffusion policy and the more dynamic, open-world nature of traffic scenes pose substantial challenges for generating diverse driving actions at a real-time speed. To address these challenges, we propose a novel truncated diffusion policy that incorporates prior multi-mode anchors and truncates the diffusion schedule, enabling the model to learn denoising from anchored Gaussian distribution to the multi-mode driving action distribution. Additionally, we design an efficient cascade diffusion decoder for enhanced interaction with conditional scene context. The proposed model, DiffusionDrive, demonstrates $10\times$ reduction in denoising steps compared to vanilla diffusion policy, delivering superior diversity and quality in just $2$ steps. On the planning-oriented NAVSIM dataset, with the aligned ResNet-34 backbone, DiffusionDrive achieves $88.1$ PDMS without bells and whistles, setting a new record, while running at a real-time speed of $45$ FPS on an NVIDIA 4090. Qualitative results on challenging scenarios further confirm that DiffusionDrive can robustly generate diverse plausible driving actions. Code and model will be available for future research.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Large-scale multimodal representation learning successfully optimizes for zero-shot transfer at test time. Yet the standard pretraining paradigm (contrastive learning on large amounts of image-text data) does not explicitly encourage representations to support few-shot adaptation. In this work, we propose a simple, but carefully designed extension to multimodal pretraining which enables representations to accommodate additional context. Using this objective, we show that vision-language models can be trained to exhibit significantly increased few-shot adaptation: across 21 downstream tasks, we find up to four-fold improvements in test-time sample efficiency, and average few-shot adaptation gains of over 5\%, while retaining zero-shot generalization performance across model scales and training durations. In particular, equipped with simple, training-free, metric-based adaptation mechanisms, our representations surpass significantly more complex optimization-based adaptation schemes.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Network quantization, a prevalent technique for network compression, significantly reduces computational demands and memory usage, thereby facilitating the deployment of large-parameter models onto hardware with constrained resources. Post-training quantization (PTQ) stands out as a cost-effective and promising approach due to its avoidance of the need for retraining. Unfortunately, many current PTQ methods in Vision Transformer (ViT) exhibit a notable decrease in accuracy, especially in lowbit cases. To tackle these challenges, we analyze the extensively utilized Hessian-guided quantization loss, and uncover certain limitations within the approximated pre-activation Hessian. By deducing the relationship between KL divergence and Fisher information matrix (FIM), we develop a more refined approximation for FIM. Building on this, we introduce the Diagonal Plus Low-Rank FIM (DPLR) to achieve a more nuanced quantization loss. Our extensive experiments, conducted across various ViT-based architectures on public benchmark datasets, demonstrate that our quantization loss calculation surpasses the performance of the prevalent mean squared error (MSE) and approximated pre-activation Hessian, and outperform previous work in lowbit cases. Code will be released upon acceptance.
|
|
Highlight
|
EnergyMoGen: Compositional Human Motion Generation with Energy-Based Diffusion Model in Latent Space
Poster
[ ExHall D ] 
Abstract
Diffusion models, particularly latent diffusion models, have demonstrated remarkable success in text-driven human motion generation. However, it remains challenging for latent diffusion models to effectively compose multiple semantic concepts into a single, coherent motion sequence. To address this issue, we propose EnergyMoGen, which includes two spectrums of Energy-Based Models: (1) We interpret the diffusion model as a latent-aware energy-based model that generates motions by composing a set of diffusion models in latent space; (2) We introduce a semantic-aware energy model based on cross-attention, which enables semantic composition and adaptive gradient descent for text embeddings. To overcome the challenges of semantic inconsistency and motion distortion across these two spectrums, we introduce Synergistic Energy Fusion. This design allows the motion latent diffusion model to synthesize high-quality, complex motions by combining multiple energy terms corresponding to textual descriptions. Experiments show that our approach outperforms existing state-of-the-art models on various motion generation tasks, including text-to-motion generation, compositional motion generation, and multi-concept motion generation. Additionally, we demonstrate that our method can be used to extend motion datasets and improve the text-to-motion task. Our implementation will be released.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce the Scene Language, a visual scene representation that concisely and precisely describes the structure, semantics, and identity of visual scenes. It represents a scene with three key components: a program that specifies the hierarchical and relational structure of entities in the scene, words in natural language that summarize the semantic class of each entity, and embeddings that capture the visual identity of each entity. This representation can be inferred from pre-trained language models via a training-free inference technique, given text or image inputs. The resulting scene can be rendered into images using traditional, neural, or hybrid graphics renderers. Together, this forms an automated system for high-quality 3D and 4D scene generation. Compared with existing representations like scene graphs, our proposed Scene Language generates complex scenes with higher fidelity, while explicitly modeling the scene structures to enable precise control and editing.
|
|
Highlight
|
Poster
[ ExHall D ] 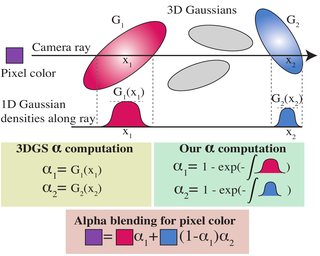
Abstract
Recently, 3D Gaussian Splatting (3DGS) has enabled photorealistic view synthesis at high inference speeds.However, its splatting-based rendering model makes several approximations to the rendering equation, reducing physical accuracy.We show that splatting and its approximations are unnecessary, even within a rasterizer;we instead volumetrically integrate 3D Gaussians directly to compute the transmittance across them analytically.We use this analytic transmittance to derive more physically accurate alpha values than 3DGS, which can directly be used within their framework. The result is a method that more closely follows the volume rendering equation (similar to ray tracing) while enjoying the speed benefits of rasterization. Our method represents opaque surfaces with higher accuracy and fewer points than 3DGS.This enables it to outperform 3DGS for view synthesis (measured in SSIM and LPIPS).Being volumetrically consistent also enables our method to work out of the box for tomography. We match the state-of-the-art 3DGS-based tomography method with fewer points.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Image denoising poses a significant challenge in image processing, aiming to remove noise and artifacts from input images. However, current denoising algorithms implemented on electronic chips frequently encounter latency issues and demand substantial computational resources. In this paper, we introduce an all-optical Nonlinear Diffractive Denoising Deep Network (N3DNet) for image denoising at the speed of light. Initially, we incorporate an image encoding and pre-denoising module into the Diffractive Deep Neural Network and integrate a nonlinear activation function, termed the phase exponential linear function, after each diffractive layer, thereby boosting the network's nonlinear modeling and denoising capabilities. Subsequently, we devise a new reinforcement learning algorithm called regularization-assisted deep Q-network to optimize N3DNet. Finally, leveraging 3D printing techniques, we fabricate N3DNet using the trained parameters and construct a physical experimental system for real-world applications. A new benchmark dataset, termed MIDD, is constructed for mode image denoising, comprising 120K pairs of noisy/noise-free images captured from real fiber communication systems across various transmission lengths. Through extensive simulation and real experiments, we validate that N3DNet outperforms both traditional and deep learning-based denoising approaches across various datasets. Remarkably, its processing speed is nearly 3,800 times faster than electronic chip-based methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Effectively leveraging motion information is crucial for the image deblurring task. Existing methods typically build deep-learning models to restore a clean image by estimating blur patterns over the entire movement. This suggests that the blur caused by rotational motion components is processed together with the translational one. Exploring the movement without separation leads to limited performance for complex motion deblurring, especially rotational motion. In this paper, we propose Motion Decomposition Transformer (MDT), a transformer-based architecture augmented with polarized modules for deblurring via motion vector decomposition. MDT consists of a Motion Decomposition Module (MDM) for extracting hybrid rotation and translation features, and a Radial Stripe Attention Solver (RSAS) for sharp image reconstruction with enhanced rotational information. Specifically, the MDM uses a deformable Cartesian convolutional branch to capture translational motion, complemented by a polar-system branch to capture rotational motion. The RSAS employs radial stripe windows and angular relative positional encoding in the polar system to enhance rotational information. This design preserves translational details while keeping computational costs lower than dual-coordinate design. Experimental results on 6 image deblurring datasets show that MDT outperforms state-of-the-art methods, particularly in handling blur caused by complex motions with significant rotational components.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The challenge of image-based 3D reconstruction for glossy objects lies in separating diffuse and specular components on glossy surfaces from captured images, a task complicated by the ambiguity in discerning lighting conditions and material properties using RGB data alone. While state-of-the-art methods rely on tailored and/or high-end equipment for data acquisition, which can be cumbersome and time-consuming, this work introduces a scalable polarization-aided approach that employs cost-effective acquisition tools. By attaching a linear polarizer to readily available RGB cameras, multi-view polarization images can be captured without the need for advance calibration or precise measurements of the polarizer angle, substantially reducing system construction costs. The proposed approach represents polarimetric BRDF, Stokes vectors, and polarization states of object surfaces as neural implicit fields. These fields, combined with the polarizer angle, are retrieved by optimizing the rendering loss of input polarized images. By leveraging fundamental physical principles for the implicit representation of polarization rendering, our method demonstrates superiority over existing techniques through experiments on public datasets and real captured images. Code and captured data will be made available upon acceptance for further evaluation.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We present Text-driven object-centric style editing model named Style-Editor, a novel method that guides style editing at an object-centric level using textual inputs.The core of Style-Editor is our Patch-wise Co-Directional (PCD) loss, meticulously designed for precise object-centric editing that are closely aligned with the input text. This loss combines a patch directional loss for text-guided style direction and a patch distribution consistency loss for even CLIP embedding distribution across object regions. It ensures a seamless and harmonious style editing across object regions.Key to our method are the Text-Matched Patch Selection (TMPS) and Pre-fixed Region Selection (PRS) modules for identifying object locations via text, eliminating the need for segmentation masks. Lastly, we introduce an Adaptive Background Preservation (ABP) loss to maintain the original style and structural essence of the image’s background. This loss is applied to dynamically identified background areas.Extensive experiments underline the effectiveness of our approach in creating visually coherent and textually aligned style editing.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Multi-view clustering, while effective in integrating information from diverse data sources, may lead to biased outcomes when sensitive attributes are involved. Despite the substantial progress in recent research, most existing methods suffer from limited interpretability and lack strong mathematical theoretical foundations. In this work, we propose a novel approach, \textbf{D}eep \textbf{F}air \textbf{M}ulti-\textbf{V}iew \textbf{C}lustering with \textbf{A}ttention \textbf{K}olmogorov-\textbf{A}rnold \textbf{N}etwork (DFMVC-AKAN), designed to generate fair clustering results while maintaining robust performance. DFMVC-AKAN integrates attention mechanisms with multi-view data reconstruction to enhance both clustering accuracy and fairness. The model introduces an attention mechanism and Kolmogorov-Arnold Networks (KAN), which together address the challenges of feature fusion and the influence of sensitive attributes in multi-view data. The attention mechanism enables the model to dynamically focus on the most relevant features across different views, while KAN provides a nonlinear feature representation capable of efficiently approximating arbitrary multivariate continuous functions, thereby capturing complex relationships and latent patterns within the data. Experimental results on four datasets containing sensitive attributes demonstrate that DFMVC-AKAN significantly improves fairness and clustering performance compared to state-of-the-art methods.
|
|
Highlight
|
Poster
[ ExHall D ] 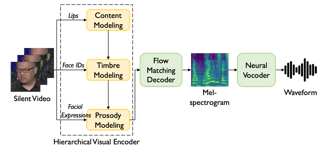
Abstract
The objective of this study is to generate high-quality speech from silent talking face videos, a task also known as video-to-speech synthesis.A significant challenge in video-to-speech synthesis lies in the substantial modality gap between silent video and multi-faceted speech. In this paper, we propose a novel video-to-speech system that effectively bridges this modality gap, significantly enhancing the quality of synthesized speech.This is achieved by learning of hierarchical representations from video to speech.Specifically, we gradually transform silent video into acoustic feature spaces through three sequential stages--content, timbre, and prosody modeling.In each stage, we align visual factors---lip movements, face identity, and facial expressions---with corresponding acoustic counterparts to ensure the seamless transformation.Additionally, to generate realistic and coherent speech from the visual representations, we employ a flow matching model that estimates direct trajectories from a simple prior distribution to the target speech distribution.Extensive experiments demonstrate that our method achieves exceptional generation quality comparable to real utterances, outperforming existing methods by a significant margin.
|
|
Highlight
|
Poster
[ ExHall D ] 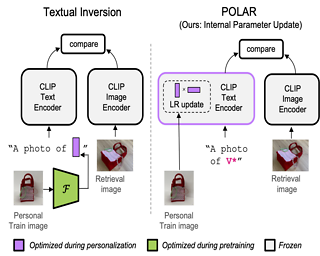
Abstract
Personalized vision-language retrieval seeks to recognize new concepts (e.g. "my dog Fido'') from only a few examples. This task is challenging because it requires not only learning a new concept from a few images, but also integrating the personal and general knowledge together to recognize the concept in different contexts. In this paper, we show how to effectively adapt the internal representation of a vision-language dual encoder model for personalized vision-language retrieval. We find that regularized low-rank adaption of a small set of parameters in the language encoder's final layer serves as a highly effective alternative to textual inversion for recognizing the personal concept while preserving general knowledge. Additionally, we explore strategies for combining parameters of multiple learned personal concepts, finding that parameter addition is effective. To evaluate how well general knowledge is preserved in a finetuned representation, we introduce a metric that measures image retrieval accuracy based on captions generated by a vision language model (VLM). Our approach achieves state-of-the-art accuracy on two benchmarks for personalized image retrieval with natural language queries -- DeepFashion2 and ConConChi -- outperforming the prior art by 4%-22% on personal retrievals.
|
|
Highlight
|
Poster
[ ExHall D ] 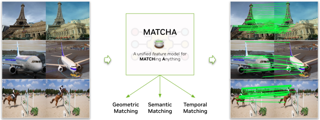
Abstract
Establishing correspondences across images is a fundamental challenge in computer vision, underpinning tasks like Structure-from-Motion, image editing, and point tracking. Traditional methods are often specialized for specific correspondence types-geometric, semantic, or temporal — whereas humans naturally identify alignments across these domains. Inspired by this flexibility, we propose MATCHA, a unified feature model designed to “rule them all”, establishing robust correspondences across diverse matching tasks. Building on insights that diffusion model features can encode multiple correspondence types, MATCHA augments this capacity by dynamically fusing high-level semantic and low-level geometric features through an attention-based module, creating expressive, versatile, and robust features. Additionally, MATCHA integrates object-level features from DINOv2 to further boost generalization, enabling a single feature capable of “matching anything.” Extensive experiments validate that MATCHA consistently surpasses state-of-the-art methods across geometric, semantic, and temporal tasks, setting a new foundation for a unified approach for the fundamental correspondence problem in computer vision. To the best of our knowledge, MATCHA is the first approach that is able to effectively tackle diverse matching tasks with a single unified feature.
|
|
Highlight
|
Poster
[ ExHall D ] 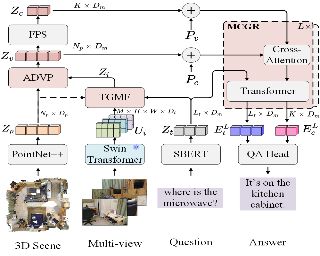
Abstract
Video question grounding (VideoQG) requires models to answer the questions and simultaneously infer the relevant video segments to support the answers. However, existing VideoQG methods usually suffer from spurious cross-modal correlations, leading to a failure to identify the dominant visual scenes that align with the intended question. Moreover, although large models possess extensive prior knowledge and can demonstrate strong performance in a zero-shot setting, issues such as spurious correlations persist, making their application to specific downstream tasks challenging. In this work, we propose a novel causality-ware VideoQG framework named Cross-modal Causality Relation Alignment (CRA), to eliminate spurious correlations and improve the causal consistency between question-answering and video temporal grounding. Our CRA involves three essential components: i) Gaussian Smoothing Attention Grounding (GSAG) module for estimating the time interval via cross-modal attention, which is de-noised by an adaptive Gaussian filter. ii) Cross-modal Alignment (CA) enhances the performance of weakly supervised VideoQG by leveraging bidirectional contrastive learning between estimated video segments and QA features. iii) Explicit Causal Intervention (ECI) module for multimodal deconfounding, which involves front-door intervention for vision and back-door intervention for language. Extensive experiments on two VideoQG datasets demonstrate the superiority of our CRA in discovering visually grounded content and achieving …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recently, it has shown that priors are vital for neural implicit functions to reconstruct high-quality surfaces from multi-view RGB images. However, current priors require large-scale pre-training, and merely provide geometric clues without considering the importance of color. In this paper, we present NeRFPrior, which adopts a neural radiance field as a prior to learn signed distance fields using volume rendering for surface reconstruction. Our NeRF prior can provide both geometric and color clues, and also get trained fast under the same scene without additional data. Based on the NeRF prior, we are enabled to learn a signed distance function (SDF) by explicitly imposing a multi-view consistency constraint on each ray intersection for surface inference. Specifically, at each ray intersection, we use the density in the prior as a coarse geometry estimation, while using the color near the surface as a clue to check its visibility from another view angle. For the textureless areas where the multi-view consistency constraint does not work well, we further introduce a depth consistency loss with confidence weights to infer the SDF. Our experimental results outperform the state-of-the-art methods under the widely used benchmarks. The source code will be publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Widely shared videos on the internet are often edited. Recently, although Video Large Language Models (Vid-LLMs) have made great progress in general video understanding tasks, their capabilities in video editing understanding (VEU) tasks remain unexplored. To address this gap, in this paper, we introduce VEU-Bench (\textbf{V}ideo \textbf{E}diting \textbf{U}nderstanding \textbf{Bench}mark), a comprehensive benchmark that categorizes video editing components across various dimensions, from intra-frame features like shot size to inter-shot attributes such as cut types and transitions. Unlike previous video editing understanding benchmarks that focus mainly on editing element classification, VEU-Bench encompasses 19 fine-grained tasks across three stages: recognition, reasoning, and judging. To enhance the annotation of VEU automatically, we built an annotation pipeline integrated with an ontology-based knowledge base. Through extensive experiments with 11 state-of-the-art Vid-LLMs, our findings reveal that current Vid-LLMs face significant challenges in VEU tasks, with some performing worse than random choice. To alleviate this issue, we develop Oscars\footnote{Named after the Academy Awards.}, a VEU expert model fine-tuned on the curated VEU-Bench dataset. It outperforms existing open-source Vid-LLMs on VEU-Bench by over 28.3\% in accuracy and achieves performance comparable to commercial models like GPT-4o. We also demonstrate that incorporating VEU data significantly enhances the performance of Vid-LLMs on …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Fur- thermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal im- age understanding across diverse settings.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We release NSD-Imagery, a benchmark dataset of human fMRI activity paired with mental images, to complement the existing Natural Scenes Dataset (NSD), a large-scale dataset of fMRI activity paired with seen images that enabled unprecedented improvements in fMRI-to-image reconstruction efforts. Recent models trained on NSD have been evaluated only on seen image reconstruction. Using NSD-Imagery, it is possible to assess how well these models perform on mental image reconstruction. This is a challenging generalization requirement because mental images are encoded in human brain activity with relatively lower signal-to-noise and spatial resolution; however, generalization from seen to mental imagery is critical for real-world applications in medical domains and brain-computer interfaces, where the desired information is always internally generated. We provide benchmarks for a suite of recent NSD-trained open-source visual decoding models (MindEye1, MindEye2, Brain Diffuser, iCNN, Takagi et al.) on NSD-Imagery, and show that the performance of decoding methods on mental images is largely decoupled from performance on vision tasks. We further demonstrate that architectural choices significantly impact cross-decoding performance: models employing simple linear decoding architectures and multimodal feature decoding generalize better to mental imagery, while complex architectures tend to overfit training data recorded exclusively from vision. Our findings indicate that …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Egocentric motion capture with a head-mounted body-facing stereo camera is crucial for VR and AR applications but presents significant challenges such as heavy occlusions and limited annotated real-world data.Existing methods heavily rely on synthetic pretraining and struggle to generate smooth and accurate predictions in real-world settings, particularly for lower limbs.Our work addresses these limitations by introducing a lightweight VR-based data collection setup with on-board, real-time 6D pose tracking. Using this setup, we collected the most extensive real-world dataset for ego-facing ego-mounted cameras to date in size and motion variability. Effectively integrating this multimodal input -- device pose and camera feeds -- is challenging due to the differing characteristics of each data source.To address this, we propose FRAME, a simple yet effective architecture that combines device pose and camera feeds for state-of-the-art body pose prediction through geometrically sound multimodal integration and can run at 300 FPS on modern hardware.Lastly, we showcase a novel training strategy to enhance the model's generalization capabilities.Our approach exploits the problem's geometric properties, yielding high-quality motion capture free from common artifacts in prior work. Qualitative and quantitative evaluations, along with extensive comparisons, demonstrate the effectiveness of our method.We will release data, code, and CAD designs for the …
|
|
Highlight
|
Poster
[ ExHall D ] 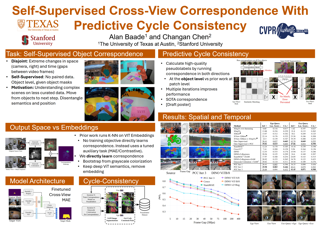
Abstract
Learning self-supervised visual correspondence is a long-studied task fundamental to visual understanding and human perception. However, existing correspondence methods largely focus on small image transformations, such as object tracking in high-framerate videos or learning pixel-to-pixel mappings between images with high view overlap. This severely limits their application in dynamic multi-view settings such as robot imitation learning or augmented reality. In this work, we introduce Predictive Cycle Consistency for learning object correspondence between extremely disjoint views of a scene without paired segmentation data. Our technique bootstraps object correspondence pseudolabels from raw image segmentations using conditional grayscale colorization and a cycle-consistency refinement prior. We then train deep ViTs on these pseudolabels, which we use to generate higher-quality pseudolabels and iteratively train better correspondence models. We demonstrate the performance of our method under both extreme in-the-wild camera view changes and across large temporal gaps in video. Our approach beats all prior supervised and prior SoTA self-supervised correspondence models on the EgoExo4D correspondence benchmark (+6.7 IoU Exo Query) and the prior SoTA self-supervised methods SiamMAE and DINO V1&V2 on the DAVIS-2017 and LVOS datasets across large frame gaps.
|
|
Highlight
|
Poster
[ ExHall D ] 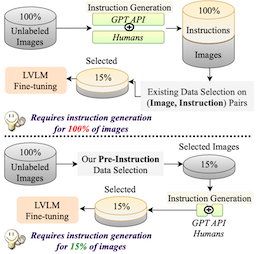
Abstract
Visual instruction tuning (VIT) for large vision-language models (LVLMs) requires training on expansive datasets of image-instruction pairs, which can be costly. Recent efforts in VIT data selection aim to select a small subset of high-quality image-instruction pairs, reducing VIT runtime while maintaining performance comparable to full-scale training. However, a major challenge often overlooked is that generating instructions from unlabeled images for VIT is highly expensive. Most existing VIT datasets rely heavily on human annotations or paid services like the GPT API, which limits users with constrained resources from creating VIT datasets for custom applications. To address this, we introduce Pre-Instruction Data Selection (PreSel), a more practical data selection paradigm that directly selects the most beneficial unlabeled images and generates instructions only for the selected images. PreSel first estimates the relative importance of each vision task within VIT datasets to derive task-wise sampling budgets. It then clusters image features within each task, selecting the most representative images with the budget. This approach reduces computational overhead for both instruction generation during VIT data formation and LVLM fine-tuning. By generating instructions for only 15% of the images, PreSel achieves performance comparable to full-data VIT on the LLaVA-1.5 and Vision-Flan datasets. Code will be …
|
|
Highlight
|
Poster
[ ExHall D ] 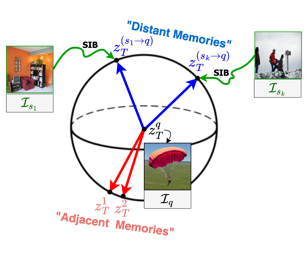
Abstract
Diffusion models dominate the space of text-to-image generation, yet they may produce undesirable outputs, including explicit content or private data. To mitigate this, concept ablation techniques have been explored to limit the generation of certain concepts.In this paper, we reveal that the erased concept information persists in the model and that erased concept images can be generated using the right latent. Utilizing inversion methods, we show that there exist latent seeds capable of generating high quality images of erased concepts.Moreover, we show that these latents have likelihoods that overlap with those of images outside the erased concept.We extend this to demonstrate that for every image from the erased concept set, we can generate many seeds that generate the erased concept.Given the vast space of latents capable of generating ablated concept images, our results suggest that fully erasing concept information may be intractable, highlighting possible vulnerabilities in current concept ablation techniques.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Vision-Language Models (VLMs) learn a shared feature space for text and images, enabling the comparison of inputs of different modalities. While prior works demonstrated that VLMs organize natural language representations into regular structures encoding composite meanings, it remains unclear if compositional patterns also emerge in the visual embedding space. In this work, we investigate compositionality in the image domain, where the analysis of compositional properties is challenged by noise and sparsity of visual data.We propose a framework, called Geodesically Decomposable Embeddings (GDE), that addresses these problems and approximates image representations with geometry-aware compositional structures in the latent space. We demonstrate that visual embeddings of pre-trained VLMs exhibit a compositional arrangement, and evaluate the effectiveness of this property in the tasks of compositional classification and group robustness. GDE achieves stronger performance in compositional classification compared to its counterpart method that assumes linear geometry of the latent space. Notably, it is particularly effective for group robustness, where we achieve higher results than task-specific solutions. Our results indicate that VLMs can automatically develop a human-like form of compositional reasoning in the visual domain, making their underlying processes more interpretable.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Multimodal large language models (MLLMs) possess the ability to comprehend visual images or videos, and show impressive reasoning ability thanks to the vast amounts of pretrained knowledge, making them highly suitable for autonomous driving applications. Unlike the previous work, DriveGPT4-V1, which focused on open-loop tasks, this study explores the capabilities of LLMs in enhancing closed-loop autonomous driving. DriveGPT4-V2 processes camera images and vehicle states as input to generate low-level control signals for end-to-end vehicle operation. A high-resolution visual tokenizer (HR-VT) is employed enabling DriveGPT4-V2 to perceive the environment with an extensive range while maintaining critical details. The model architecture has been refined to improve decision prediction and inference speed. To further enhance the performance, an additional expert LLM is trained for online imitation learning. The expert LLM, sharing a similar structure with DriveGPT4-V2, can access privileged information about surrounding objects for more robust and reliable predictions. Experimental results show that DriveGPT4-V2 significantly outperforms all baselines on the challenging CARLA Longest6 benchmark. The code and data of DriveGPT4-V2 will be publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Advances in medical imaging and deep learning have propelled progress in whole slide image (WSI) analysis, with multiple instance learning (MIL) showing promise for efficient and accurate diagnostics. However, conventional MIL models often lack adaptability to evolving datasets, as they rely on static training that cannot incorporate new information without extensive retraining. Applying continual learning (CL) to MIL models is a possible solution, but often sees limited improvements. In this paper, we analyze CL in the context of attention MIL models and find that the model forgetting is mainly concentrated in the attention layers of the MIL model. Using the results of this analysis we propose two components for improving CL on MIL:Attention Knowledge Distillation (AKD) and the Pseudo-Bag Memory Pool (PMP). AKD mitigates catastrophic forgetting by focusing on retaining attention layer knowledge between learning sessions, while PMP reduces the memory footprint by selectively storing only the most informative patches, or ''pseudo-bags'' from WSIs. Experimental evaluations demonstrate that our method significantly improves both accuracy and memory efficiency on diverse WSI datasets, outperforming current state-of-the-art CL methods. This work provides a foundation for CL in large-scale, weakly annotated clinical datasets, paving the way for more adaptable and resilient diagnostic models.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this work, we analyze new aspects of cross-view completion, mainly through the analogy of cross-view completion and traditional self-supervised correspondence learning algorithms. Based on our analysis, we reveal that the cross-attention map of Croco-v2, best reflects this correspondence information compared to other correlations from the encoder or decoder features. We further verify the effectiveness of the cross-attention map by evaluating on both zero-shot and supervised dense geometric correspondence and multi-frame depth estimation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Point management is critical for optimizing 3D Gaussian Splatting models, as point initiation (e.g., via structure from motion) is often distributionally inappropriate. Typically, Adaptive Density Control (ADC) algorithm is adopted, leveraging view-averaged gradient magnitude thresholding for point densification, opacity thresholding for pruning, and regular all-points opacity reset. We reveal that this strategy is limited in tackling intricate/special image regions (e.g., transparent) due to inability of identifying all 3D zones requiring point densification, and lacking an appropriate mechanism to handle ill-conditioned points with negative impacts (e.g., occlusion due to false high opacity).To address these limitations, we propose a Localized Point Management(LPM) strategy, capable of identifying those error-contributing zones in greatest need for both point addition and geometry calibration. Zone identification is achieved by leveraging the underlying multiview geometry constraints, subject to image rendering errors. We apply point densification in the identified zones and then reset the opacity of the points in front of these regions, creating a new opportunity to correct poorly conditioned points. Serving as a versatile plugin, LPM can be seamlessly integrated into existing static 3D and dynamic 4D Gaussian Splatting models with minimal additional cost.Experimental evaluations validate the efficacy of our LPM in boosting a variety of existing …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present WonderWorld, a novel framework for interactive 3D scene generation that enables users to interactively specify scene contents and layout and see the created scenes in low latency. The major challenge lies in achieving fast generation of 3D scenes. Existing scene generation approaches fall short of speed as they often require (1) progressively generating many views and depth maps, and (2) time-consuming optimization of the scene representations. Our approach does not need multiple views, and it leverages a geometry-based initialization that significantly reduces optimization time. Another challenge is generating coherent geometry that allows all scenes to be connected. We introduce the guided depth diffusion that allows partial conditioning of depth estimation. WonderWorld generates connected and diverse 3D scenes in less than 10 seconds on a single A6000 GPU, enabling real-time user interaction and exploration. We will release full code and software for reproducibility.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Text-to-image person re-identification (ReID) aims to retrieve the images of an interested person based on textual descriptions. One main challenge for this task is the high cost in manually annotating large-scale databases, which affects the generalization ability of ReID models. Recent works handle this problem by leveraging Multi-modal Large Language Models (MLLMs) to describe pedestrian images automatically. However, the captions produced by MLLMs lack diversity in description styles. To address this issue, we propose a Human Annotator Modeling (HAM) approach to enable MLLMs to mimic the description styles of thousands of human annotators. Specifically, we first extract style features from human textual descriptions and perform clustering on them. This allows us to group textual descriptions with similar styles into the same cluster. Then, we employ a prompt to represent each of these clusters and apply prompt learning to mimic the description styles of different human annotators. Furthermore, we define a style feature space and perform uniform sampling in this space to obtain more diverse clustering prototypes, which further enriches the diversity of the MLLM-generated captions. Finally, we adopt HAM to automatically annotate a massive-scale database for text-to-image ReID. Extensive experiments on this database demonstrate that it significantly improves the generalization …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Simultaneously acquisition of the surface normal and reflectance parameters is a crucial but challenging technique in the field of computer vision and graphics. It requires capturing multiple high dynamic range (HDR) images in existing methods using frame-based cameras. In this paper, we propose EventPSR, the first work to recover surface normal and reflectance parameters (e.g., metallic and roughness) simultaneously using an event camera. Compared with the existing methods based on photometric stereo or neural radiance fields, EventPSR is a robust and efficient approach that works consistently with different materials. Thanks to the extremely high temporal resolution and high dynamic range coverage of event cameras, EventPSR can recover accurate surface normal and reflectance of objects with various materials in 10 seconds. Extensive experiments on both synthetic data and real objects show that compared with existing methods using more than 100 HDR images, EventPSR recovers comparable surface normal and reflectance parameters with only about 30% of the data rate.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Effective training of large Vision-Language Models (VLMs) on resource-constrained client devices in Federated Learning (FL) requires the usage of parameter-efficient fine-tuning (PEFT) strategies. To this end, we demonstrate the impact of two factors \textit{viz.}, client-specific layer importance score that selects the most important VLM layers for fine-tuning and inter-client layer diversity score that encourages diverse layer selection across clients for optimal VLM layer selection. We first theoretically motivate and leverage the principal eigenvalue magnitude of layerwise Neural Tangent Kernels and show its effectiveness as client-specific layer importance score. Next, we propose a novel layer updating strategy dubbed \textbf{F$^3$OCUS} that jointly optimizes the layer importance and diversity factors by employing a data-free, multi-objective, meta-heuristic optimization on the server. We explore 5 different meta-heuristic algorithms and compare their effectiveness for selecting model layers and adapter layers towards PEFT-FL. Furthermore, we release a new MedVQA-FL dataset involving overall 707,962 VQA triplets and 9 modality-specific clients and utilize it to train and evaluate our method. Overall, we conduct more than 10,000 client-level experiments on 6 Vision-Language FL task settings involving 58 medical image datasets and 4 different VLM architectures of varying sizes to demonstrate the effectiveness of the proposed method.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
User engagement is greatly enhanced by fully immersive multimodal experiences that combine visual and auditory stimuli. Consequently, the next frontier in VR/AR technologies lies in immersive volumetric videos with complete scene capture, large 6-DoF interactive space, Multi-modal feedback, and high resolution\&frame-rate contents. To stimulate the reconstruction of immersive volumetric videos, we introduce **ImViD**, a multi-view, multi-modal dataset featuring complete space-oriented data capture and various indoor/outdoor scenarios. Our capture rig supports multi-view video-audio capture while on the move, a capability absent in existing datasets, which significantly enhances the completeness, flexibility, and efficiency of data capture. The captured multi-view videos (with synchronized audios) are in 5K resolution at 60FPS, lasting from 1-5 minutes, and include rich foreground-background elements, and complex dynamics. We benchmark existing methods using our dataset and establish a base pipeline for constructing immersive volumetric videos from multi-view audiovisual inputs for 6-DoF multimodal immersive VR experiences. The benchmark and the reconstruction and interaction results demonstrate the effectiveness of our dataset and baseline method, which we believe will stimulate future research on immersive volumetric video production.
|
|
Highlight
|
Poster
[ ExHall D ] 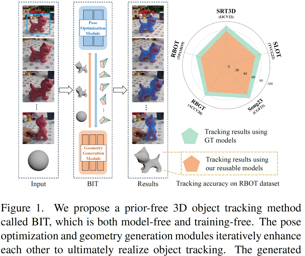
Abstract
In this paper, we introduce a novel, truly prior-free 3D object tracking method that operates without given any model or training priors. Unlike existing methods that typically require pre-defined 3D models or specific training datasets as priors, which limit their applicability, our method is free from these constraints. Our method consists of a geometry generation module and a pose optimization module. Its core idea is to enable these two modules to automatically and iteratively enhance each other, thereby gradually building all the necessary information for the tracking task. We thus call the method as Bidirectional Iterative Tracking(BIT). The geometry generation module starts without priors and gradually generates high-precision mesh models for tracking, while the pose optimization module generates additional data during object tracking to further refine the generated models. Moreover, the generated 3D models can be stored and easily reused, allowing for seamless integration into various other tracking systems, not just our methods. Experimental results demonstrate that BIT outperforms many existing methods, even those that extensively utilize prior knowledge, while BIT does not rely on such information. Additionally, the generated 3D models deliver results comparable to actual 3D models, highlighting their superior and innovative qualities.
|
|
Highlight
|
Poster
[ ExHall D ] 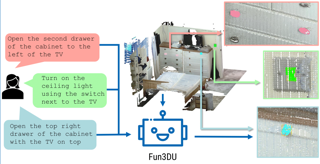
Abstract
Understanding functionalities in 3D scenes involves interpreting natural language descriptions to locate functional interactive objects, such as handles and buttons, in a 3D environment. Functionality understanding is highly challenging, as it requires both world knowledge to interpret language and spatial perception to identify fine-grained objects. For example, given a task like ‘turn on the ceiling light,’ an embodied AI agent must infer that it needs to locate the light switch, even though the switch is not explicitly mentioned in the task description. To date, no dedicated methods have been developed for this problem. In this paper, we introduce Fun3DU, the first approach designed for functionality understanding in 3D scenes. Fun3DU uses a language model to parse the task description through Chain-of-Thought reasoning in order to identify the object of interest. The identified object is segmented across multiple views of the captured scene by using a vision and language model. The segmentation results from each view are lifted in 3D and aggregated into the point cloud using geometric information. Fun3DU is training-free, relying entirely on pre-trained models. We evaluate Fun3DU on SceneFun3D, the most recent and only dataset to benchmark this task, which comprises over 3000 task descriptions on 230 scenes. …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Large multimodal models (LMMs) typically process visual inputs with uniform resolution across the entire field of view, leading to inefficiencies when non-critical image regions are processed as precisely as key areas. Inspired by the human visual system's foveated approach, we apply a biologically inspired method to leading architectures such as MDETR, BLIP2, InstructBLIP, LLaVA, and ViLT, and evaluate their performance with variable resolution inputs. Results show that foveated sampling boosts accuracy in visual tasks like question answering and object detection under tight pixel budgets, improving performance by up to 2.7% on the GQA dataset, 2.1% on SEED-Bench, and 2.0% on VQAv2 compared to uniform sampling. Furthermore, our research indicates that indiscriminate resolution increases yield diminishing returns, with models achieving up to 80% of their full capability using just 3% of the pixels, even on complex tasks. Foveated sampling also prompts more human-like processing within models, such as neuronal selectivity and globally-acting self-attention in vision transformers. This paper provides a foundational analysis of foveated sampling's impact on existing models, suggesting that more efficient architectural adaptations, mimicking human visual processing, are a promising research venue for the community.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Implicit neural representation and explicit 3D Gaussian Splatting (3D-GS) for novel view synthesis have achieved remarkable progress with frame-based camera (e.g. RGB and RGB-D cameras) recently. Compared to frame-based camera, a novel type of bio-inspired visual sensor, \ie event camera, has demonstrated advantages in high temporal resolution, high dynamic range, low power consumption and low latency, which make it being favored for many robotic applications. In this work, we present IncEventGS, an incremental 3D Gaussian Splatting reconstruction algorithm with a single event camera, without the assumption of known camera poses. To recover the 3D scene representation incrementally, we exploit the tracking and mapping paradigm of conventional SLAM pipelines for IncEventGS. Given the incoming event stream, the tracker first estimates an initial camera motion based on prior reconstructed 3D-GS scene representation. The mapper then jointly refines both the 3D scene representation and camera motion based on the previously estimated motion trajectory from the tracker. The experimental results demonstrate that IncEventGS delivers superior performance compared to prior NeRF-based methods and other related baselines, even we do not have the ground-truth camera poses. Furthermore, our method can also deliver better performance compared to state-of-the-art event visual odometry methods in terms of camera motion …
|
|
Highlight
|
Poster
[ ExHall D ] 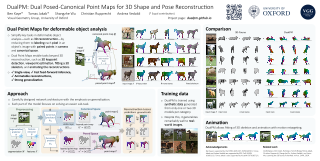
Abstract
The choice of data representation is a key factor in the success of deep learning in geometric tasks. For instance, DUSt3R has recently introduced the concept of viewpoint-invariant point maps, generalizing depth prediction, and showing that one can reduce all the key problems in the 3D reconstruction of static scenes to predicting such point maps. In this paper, we develop an analogous concept for a very different problem, namely, the reconstruction of the 3D shape and pose of deformable objects. To this end, we introduce the Dual Point Maps (DualPM), where a pair of point maps is extracted from the same image, one associating pixels to their 3D locations on the object, and the other to a canonical version of the object at rest pose. We also extend point maps to amodal reconstruction, seeing through self-occlusions to obtain the complete shape of the object. We show that 3D reconstruction and 3D pose estimation reduce to the prediction of the DualPMs. We demonstrate empirically that this representation is a good target for a deep network to predict; specifically, we consider modelling horses, showing that DualPMs can be trained purely on 3D synthetic data, consisting of a single model of a horse, …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The astonishing breakthrough of multimodal large language models (MLLMs) has necessitated new benchmarks to quantitatively assess their capabilities, reveal their limitations, and indicate future research directions. However, this is challenging in the context of remote sensing (RS), since the imagery features ultra-high resolution that incorporates extremely complex semantic relationships. Existing benchmarks usually adopt notably smaller image sizes than real-world RS scenarios, suffer from limited annotation quality, and consider insufficient dimensions of evaluation. To address these issues, we present XLRS-Bench: a comprehensive benchmark for evaluating the perception and reasoning capabilities of MLLMs in ultra-high-resolution RS scenarios. XLRS-Bench boasts the largest average image size (8500$\times$8500) observed thus far, with all evaluation samples meticulously annotated manually, assisted by a novel semi-automatic captioner on ultra-high-resolution RS images. On top of the XLRS-Bench, 16 sub-tasks are defined to evaluate MLLMs' 6 kinds of perceptual abilities and 4 kinds of reasoning capabilities, with a primary emphasis on advanced cognitive processes that facilitate real-world decision-making and the capture of spatiotemporal changes. The results of both general and RS-focused MLLMs on XLRS-Bench indicate that further efforts are needed to enhance their performance in real RS scenarios. We will open source XLRS-Bench to support further research of developing more …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Human-object interaction (HOI) reconstruction has garnered significant attention due to its diverse applications and the success of capturing human meshes. Existing HOI reconstruction methods often rely on explicitly modeling interactions between humans and objects. However, such a way leads to a natural conflict between 3D mesh reconstruction, which emphasizes global structure, and fine-grained contact reconstruction, which focuses on local details. To address the limitations of explicit modeling, we propose the End-to-End HOI Reconstruction Transformer with Graph-based Encoding (HOI-TG). It implicitly learns the interaction between humans and objects by leveraging self-attention mechanisms. Within the transformer architecture, we devise graph residual blocks to aggregate the topology among vertices of different spatial structures. This dual focus effectively balances global and local representations. Without bells and whistles, HOI-TG achieves state-of-the-art performance on BEHAVE and InterCap datasets. Particularly on the challenging InterCap dataset, our method improves the reconstruction results for human and object meshes by 8.9% and 8.6%, respectively.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Humans can effortlessly locate desired objects in cluttered environments, relying on a cognitive mechanism known as visual search to efficiently filter out irrelevant information and focus on task-related regions. Inspired by this process, we propose DyFo (Dynamic Focus), a training-free dynamic focusing visual search method that enhances fine-grained visual understanding in large multimodal models (LMMs). Unlike existing approaches which require additional modules or data modifications, DyFo leverages a bidirectional interaction between LMMs and visual experts, using a Monte Carlo Tree Search (MCTS) algorithm to simulate human-like focus adjustments. This enables LMMs to focus on key visual regions while filtering out irrelevant content without the need for vocabulary expansion or specialized localization modules. Experimental results demonstrate that DyFo significantly improves fine-grained visual understanding and reduces hallucination issues in LMMs, achieving superior performance across both fixed and variable resolution models.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Despite remarkable progress in image generation models, generating realistic hands remains a persistent challenge due to their complex articulation, varying viewpoints, and frequent occlusions. We present FoundHand, a large-scale domain-specific diffusion model for synthesizing single and dual hand images. To train our model, we introduce FoundHand-10M, a large-scale hand dataset with 2D keypoints and segmentation mask annotations. Our insight is to use 2D hand keypoints as a universal representation that encodes both hand articulation and camera viewpoint. FoundHand learns from image pairs to capture physically plausible hand articulations, natively enables precise control through 2D keypoints, and supports appearance control. Our model exhibits core capabilities that include the ability to repose hands, transfer hand appearance, and even synthesize novel views. This leads to zero-shot capabilities for fixing malformed hands in previously generated images, or synthesizing hand video sequences. We present extensive experiments and evaluations that demonstrate state-of-the-art performance of our method.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent developments in monocular depth estimation methods enable high-quality depth estimation of single-view images but fail to estimate consistent video depth across different frames. Recent works address this problem by applying a video diffusion model to generate video depth conditioned on the input video, which is training-expensive and can only produce scale-invariant depth values without camera poses. In this paper, we propose a novel video-depth estimation method called Align3R to estimate temporal consistent depth maps for a dynamic video. Our key idea is to utilize the recent DUSt3R model to align estimated monocular depth maps of different timesteps. First, we fine-tune the DUSt3R model with additional estimated monocular depth as inputs for the dynamic scenes. Then, we apply optimization to reconstruct both depth maps and camera poses. Extensive experiments demonstrate that Align3R estimates consistent video depth and camera poses for a monocular video with superior performance than baseline methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
DUSt3R introduced a novel paradigm in geometric computer vision by proposing a model that can provide dense and unconstrained Stereo 3D Reconstruction of arbitrary image collections with no prior information about camera calibration nor viewpoint poses. Under the hood, however, DUSt3R processes image pairs, regressing local 3D reconstructions that need to be aligned in a global coordinate system. The number of pairs, growing quadratically, is an inherent limitation that becomes especially concerning for robust and fast optimization in the case of large image collections. In this paper, we propose an extension of DUSt3R from pairs to multiple views, that addresses all aforementioned concerns. Indeed, we propose a Multi-view Network for Stereo 3D Reconstruction, or MUNSt3R, that modifies the DUSt3R architecture by making it symmetric and extending it to directly predict 3D structure for all views in a common coordinate frame. Second, we entail the model with a multi-layer memory mechanism which allows to reduce the computational complexity and to scale the reconstruction to large collections, inferring 3D pointmaps at high frame-rates with limited added complexity. The framework is designed to perform 3D reconstruction both offline and online, and hence can be seamlessly applied to SfM and SLAM scenarios showing state-of-the-art …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Progress in Embodied AI has made it possible for end-to-end-trained agents to navigate in photo-realistic environments with high-level reasoning and zero-shot or language-conditioned behavior, but evaluations and benchmarks are still dominated by simulation. In this work, we focus on the fine-grained behavior of fast-moving real robots and present a large-scale experimental study involving \numepisodes{} navigation episodes in a real environment with a physical robot, where we analyze the type of reasoning emerging from end-to-end training. In particular, we study the presence of realistic dynamics which the agent learned for open-loop forecasting, and their interplay with sensing. We analyze the way the agent uses latent memory to hold elements of the scene structure and information gathered during exploration. We probe the planning capabilities of the agent, and find in its memory evidence for somewhat precise plans over a limited horizon. Furthermore, we show in a post-hoc analysis that the value function learned by the agent relates to long-term planning. Put together, our experiments paint a new picture on how using tools from computer vision and sequential decision making have led to new capabilities in robotics and control. An interactive tool is available at https://visual-navigation-reasoning.github.io
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Visual grounding seeks to localize the image region corresponding to a free-form text description. Recently, the strong multimodal capabilities of Large Vision-Language Models (LVLMs) have driven substantial improvements in visual grounding, though they inevitably require fine-tuning and additional model components to explicitly generate bounding boxes or segmentation masks. However, we discover that a few attention heads in frozen LVLMs demonstrate strong visual grounding capabilities. We refer to these heads, which consistently capture object locations related to text semantics, as localization heads. Using localization heads, we introduce a straightforward and effective training-free visual grounding framework that utilizes text-to-image attention maps from localization heads to identify the target objects. Surprisingly, only three out of thousands of attention heads are sufficient to achieve competitive localization performance compared to existing LVLM-based visual grounding methods that require fine-tuning. Our findings suggest that LVLMs can innately ground objects based on a deep comprehension of the text-image relationship, as they implicitly focus on relevant image regions to generate informative text outputs. All the source codes will be made available to the public.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Stereo matching recovers depth from image correspondences. Existing methods struggle to handle ill-posed regions with limited matching cues, such as occlusions and textureless areas. To address this, we propose MonSter, a novel method that leverages the complementary strengths of monocular depth estimation and stereo matching. MonSter integrates monocular depth and stereo matching into a dual-branch architecture to iteratively improve each other. Confidence-based guidance adaptively selects reliable stereo cues for monodepth scale-shift recovery, and utilizes explicit monocular depth priors to enhance stereo matching at ill-posed regions. Such iterative mutual enhancement enables MonSter to evolve monodepth priors from coarse object-level structures to pixel-level geometry, fully unlocking the potential of stereo matching. As shown in Fig.2, MonSter ranks 1st across five most commonly used leaderboards --- SceneFlow, KITTI 2012, KITTI 2015, Middlebury, and ETH3D. Achieving up to 49.5% improvements over the previous best method (Bad 1.0 on ETH3D). Comprehensive analysis verifies the effectiveness of MonSter in ill-posed regions. In terms of zero-shot generalization, MonSter significantly and consistently outperforms state-of-the-art methods across the board. Code will be released upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Atmospheric turbulence is a major source of image degradation in long-range imaging systems. Although numerous deep learning-based turbulence mitigation (TM) methods have been proposed, many are slow, memory-hungry, and do not generalize well. In the spatial domain, methods based on convolutional operators have a limited receptive field, so they cannot handle a large spatial dependency required by turbulence. In the temporal domain, methods relying on self-attention can, in theory, leverage the lucky effects of turbulence, but their quadratic complexity makes it difficult to scale to many frames. Traditional recurrent aggregation methods face parallelization challenges.In this paper, we present a new TM method based on two concepts: (1) A turbulence mitigation network based on the Selective State Space Model (MambaTM). MambaTM provides a global receptive field in each layer across spatial and temporal dimensions while maintaining linear computational complexity. (2) Learned Latent Phase Distortion (LPD). LPD guides the state space model. Unlike classical Zernike-based representations of phase distortion, the new LPD map uniquely captures the actual effects of turbulence, significantly improving the model’s capability to estimate degradation by reducing the ill-posedness. Our proposed method exceeds current state-of-the-art networks on various synthetic and real-world TM benchmarks with significantly faster inference speed. The …
|
|
Highlight
|
Poster
[ ExHall D ] 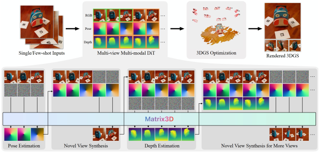
Abstract
We present Matrix3D, a unified model that performs several photogrammetry subtasks, including pose estimation, depth prediction, and novel view synthesis using just the same model. Matrix3D utilizes a multi-modal diffusion transformer (DiT) to integrate transformations across several modalities, such as images, camera parameters, and depth maps. The key to Matrix3D's large-scale multi-modal training lies in the incorporation of a mask learning strategy. This enables full-modality model training even with partially complete data, such as bi-modality data of image-pose and image-depth pairs, thus significantly increases the pool of available training data.Matrix3D demonstrates state-of-the-art performance in pose estimation and novel view synthesis tasks. Additionally, it offers fine-grained control through multi-round interactions, making it an innovative tool for 3D content creation.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
While recent text-to-image models can generate photorealistic images from text prompts that reflect detailed instructions, they still face significant challenges in accurately rendering words in the image.In this paper, we propose to retouch erroneous text renderings in the post-processing pipeline.Our approach, called Type-R, identifies typographical errors in the generated image, erases the erroneous text, regenerates text boxes for missing words, and finally corrects typos in the rendered words.Through extensive experiments, we show that Type-R, in combination with the latest text-to-image models such as Stable Diffusion or Flux, achieves the highest text rendering accuracy while maintaining image quality and also outperforms text-focused generation baselines in terms of balancing text accuracy and image quality.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Given a video and a set of input object masks, an omnimatte method aims to decompose the video into semantically meaningful layers containing individual objects along with their associated effects, such as shadows and reflections.Existing omnimatte methods assume a static background or accurate pose and depth estimation and produce poor decompositions when these assumptions are violated. Furthermore, due to the lack of generative prior on natural videos, existing methods cannot complete dynamic occluded regions.We present a novel generative layered video decomposition framework to address the omnimatte problem. Our method does not assume a stationary scene or require camera pose or depth information and produces clean, complete layers, including convincing completions of occluded dynamic regions. Our core idea is to train a video diffusion model to identify and remove scene effects caused by a specific object. We show that this model can be finetuned from an existing video inpainting model with a small, carefully curated dataset, anddemonstrate high-quality decompositions and editing results for a wide range of casually captured videos containing soft shadows, glossy reflections, splashing water, and more.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Spatio-Temporal Scene Graphs (STSGs) provide a concise and expressive representation of dynamic scenes by modelling objects and their evolving relationships over time. However, real-world visual relationships often exhibit a long-tailed distribution, causing existing methods for tasks like Video Scene Graph Generation (VidSGG) and Scene Graph Anticipation (SGA) to produce biased scene graphs. To this end, we propose \textbf{ImparTail}, a novel training framework that leverages curriculum learning and loss masking to mitigate bias in the generation and anticipation of spatio-temporal scene graphs. Our approach gradually decreases the dominance of the head relationship classes during training and focuses more on tail classes, leading to more balanced training. Furthermore, we introduce two new tasks—Robust Spatio-Temporal Scene Graph Generation and Robust Scene Graph Anticipation—designed to evaluate the robustness of STSG models against distribution shifts. Extensive experiments on the Action Genome dataset demonstrate that our framework significantly enhances the unbiased performance and robustness of STSG models compared to existing methods.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Achieving realistic simulations of humans engaging in a wide range of object interactions has long been a fundamental goal in animation. Extending physics-based motion imitation techniques to complex human-object interactions (HOIs) is particularly challenging due to the intricate coupling between human-object dynamics and the variability in object geometries and properties. Moreover, motion capture data often contain artifacts such as inaccurate contacts and insufficient hand details, which hinder the learning process. We introduce InterMimic, a framework that overcomes these challenges by enabling a single policy to robustly learn from imperfect motion capture sequences encompassing tens of hours of diverse full-body interaction skills with dynamic and varied objects. Our key insight is employing a curriculum strategy: perfecting first, then scaling up. We first train subject-specific teacher policies to mimic, retarget, and refine the motion capture data, effectively correcting imperfections. Then, we distill a student policy from these teachers; the teachers act as online experts providing direct supervision and supplying clean references. This ensures that the student policy learns from high-quality guidance despite imperfections in the original dataset. Our experiments demonstrate that InterMimic produces realistic and diverse interactions across various HOI datasets. Notably, the learned policy exhibits zero-shot generalization, allowing seamless integration with …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Shape abstraction, simplifying shape representation into a set of primitives, is a fundamental topic in computer vision. The choice of primitives shapes the structure of world understanding, yet achieving both high abstraction accuracy and versatility remains challenging. In this paper, we introduce a novel framework for shape abstraction utilizing a differentiable support function (DSF), which offers unique advantages in representing a wide range of convex shapes with fewer parameters, providing smooth surface approximation and enabling differentiable contact features (gap, point, normal) essential for downstream applications involving contact-related problems. To tackle the associated optimization and combinatorial challenges, we introduce two techniques: differentiable shape parameterization and hyperplane-based marching to enhance accuracy and reduce DSF requirements. We validate our method through experiments demonstrating superior accuracy and efficiency, and showcase its applicability in tasks requiring differentiable contact information.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Test-time prompt tuning for vision-language models (VLMs) are getting attention due to their ability to learn with unlabeled data without fine-tuning. Although test-time prompt tuning methods for VLMs can boost accuracy, the resulting models tend to demonstrate poor calibration, which casts doubts on the reliability and trustworthiness of these models. Notably, more attention needs to be devoted to calibrating the test-time prompt tuning in vision-language models. To this end, we propose a new approach, called O-TPT that introduces orthogonality constraints on the textual features corresponding to the learnable prompts for calibrating test-time prompt tuning in VLMsTowards introducing orthogonality constraints, we make the following contributions. First, we uncover new insights behind the suboptimal calibration performance of existing methods relying on textual feature dispersion. Second, we show that imposing a simple orthogonalization of textual features is a more effective approach towards obtaining textual dispersion.We conduct extensive experiments on various datasets with different backbones and baselines. Results indicate that our method consistently outperforms the state-of-the-art in significantly reducing the overall average calibration error. Also, our method surpasses the zero-shot calibration performance on fine-grained classification tasks. Our code will be made public upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Diffusion Transformers have demonstrated remarkable capabilities in image generation but often come with excessive parameterization, resulting in considerable inference overhead in real-world applications. In this work, we present TinyFusion, a depth pruning method designed to remove redundant layers from diffusion transformers via end-to-end learning. The core principle of our approach is to create a pruned model with high recoverability, allowing it to regain strong performance after fine-tuning. To accomplish this, we introduce a differentiable sampling technique to make pruning learnable, paired with a co-optimized parameter to simulate future fine-tuning. While prior works focus on minimizing loss or error after pruning, our method explicitly models and optimizes the post-fine-tuning performance of pruned models. Experimental results indicate that this learnable paradigm offers substantial benefits for layer pruning of diffusion transformers, surpassing existing importance-based and error-based methods. Additionally, TinyFusion exhibits strong generalization across diverse architectures, such as DiTs, MARs, and SiTs. Experiments with DiT-XL show that TinyFusion can craft a shallow diffusion transformer at less than 7% of the pre-training cost, achieving a 2$\times$ speedup with an FID score of 2.86, outperforming competitors with comparable efficiency.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present a real-time monocular dense SLAM system designed bottom-up from MASt3R, a two-view 3D reconstruction and matching prior. Equipped with this strong prior, our system is robust on in-the-wild video sequences despite making no assumption on a fixed or parametric camera model beyond a unique camera centre. We introduce efficient methods for pointmap matching, camera tracking and local fusion, graph construction and loop closure, and second-order global optimisation. With known calibration, a simple modification to the system achieves state-of-the-art performance across various benchmarks. Altogether, we propose a plug-and-play monocular SLAM system capable of producing globally-consistent poses and dense geometry while operating at 15 FPS.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present a novel approach for indoor scene synthesis, which learns to arrange decomposed cuboid primitives to represent 3D objects within a scene. Unlike conventional methods that use bounding boxes to determine the placement and scale of 3D objects, our approach leverages cuboids as a straightforward yet highly effective alternative for modeling objects. This allows for compact scene generation while minimizing object intersections. Our approach, coined CASAGPT for Cuboid Arrangement and Scene Assembly, employs an autoregressive model to sequentially arrange cuboids, producing physically plausible scenes. By applying rejection sampling during the fine-tuning stage to filter out scenes with object collisions, our model further reduces intersections and enhances scene quality. Additionally, we introduce a refined dataset, 3DFRONT-NC, which eliminates significant noise presented in the original dataset, 3D-FRONT. Extensive experiments on the 3D-FRONT dataset as well as our dataset demonstrate that our approach consistently outperforms the state-of-the-art methods, enhancing the realism of generated scenes, and providing a promising direction for 3D scene synthesis.
|
|
Highlight
|
Poster
[ ExHall D ] 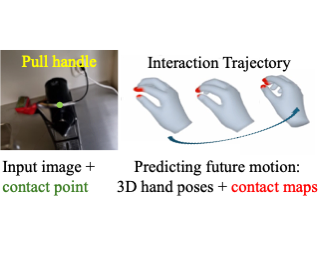
Abstract
We tackle the novel problem of predicting 3D hand motion and contact maps (or Interaction Trajectories) given a single RGB view, action text, and a 3D contact point on the object as input.Our approach consists of (1) Interaction Codebook: a VQVAE model to learn a latent codebook of hand poses and contact points, effectively tokenizing interaction trajectories, (2) Interaction Predictor: a transformer-decoder module to predict the interaction trajectory from test time inputs by using an indexer module to retrieve a latent affordance from the learned codebook. To train our model, we develop a data engine that extracts 3D hand poses and contact trajectories from the diverse HoloAssist dataset. We evaluate our model on a benchmark that is 2.5-10X larger than existing works, in terms of diversity of objects and interactions observed, and test for generalization of the model across object categories, action categories, tasks, and scenes. Experimental results show the effectiveness of our approach over transformer & diffusion baselines across all settings.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We present a method for learning binaural sound localization from ego-motion in videos. When the camera moves in a video, the direction of sound sources will change along with it. We train an audio model to predict sound directions that are consistent with visual estimates of camera motion, which we obtain using methods from multi-view geometry. This provides a weak but plentiful form of supervision that we combine with traditional binaural cues. To evaluate this idea, we propose a dataset of real-world audio-visual videos with ego-motion. We show that our model can successfully learn from this real-world data, and that it obtains strong performance on sound localization tasks.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Estimating canopy height and its changes at meter resolution from satellite imagery is a significant challenge in computer vision with critical environmental applications.However, the lack of open-access datasets at this resolution hinders the reproducibility and evaluation of models. We introduce Open-Canopy, the first open-access, country-scale benchmark for very high-resolution (1.5 m) canopy height estimation, covering over 87,000 km² across France with 1.5 m resolution satellite imagery and aerial LiDAR data.Additionally, we present Open-Canopy-∆, a benchmark for canopy height change detection between images from different years at tree level—a challenging task for current computer vision models. We evaluate state-of-the-art architectures on these benchmarks, highlighting significant challenges and opportunities for improvement. Our datasets and code are publicly available at [URL].
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Infrared unmanned aerial vehicle (UAV) images captured using thermal detectors are often affected by temperature-dependent low-frequency nonuniformity, which significantly reduces the contrast of the images. Detecting UAV targets under nonuniform conditions is crucial in UAV surveillance applications. Existing methods typically treat infrared nonuniformity correction (NUC) as a preprocessing step for detection, which leads to suboptimal performance. Balancing the two tasks while enhancing detection-beneficial information remains challenging. In this paper, we present a detection-friendly union framework, termed UniCD, that simultaneously addresses both infrared NUC and UAV target detection tasks in an end-to-end manner. We first model NUC as a small number of parameter estimation problem jointly driven by priors and data to generate detection-conducive images. Then, we incorporate a new auxiliary loss with target mask supervision into the backbone of the infrared UAV target detection network to strengthen target features while suppressing the background. To better balance correction and detection, we introduce a detection-guided self-supervised loss to reduce feature discrepancies between the two tasks, thereby enhancing detection robustness to varying nonuniformity levels. Additionally, we construct a new benchmark composed of 50,000 infrared images in various nonuniformity types, multi-scale UAV targets and rich backgrounds with target annotations, called IRBFD. Extensive experiments on …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Estimating video depth in open-world scenarios is challenging due to the diversity of videos in appearance, content motion, camera movement, and length. We present DepthCrafter, an innovative method for generating temporally consistent long depth sequences with intricate details for open-world videos, without requiring any supplementary information such as camera poses or optical flow. The generalization ability to open-world videos is achieved by training the video-to-depth model from a pre-trained image-to-video diffusion model, through our meticulously designed three-stage training strategy. Our training approach enables the model to generate depth sequences with variable lengths at one time, up to 110 frames, and harvest both precise depth details and rich content diversity from realistic and synthetic datasets. We also propose an inference strategy that can process extremely long videos through segment-wise estimation and seamless stitching. Comprehensive evaluations on multiple datasets reveal that DepthCrafter achieves state-of-the-art performance in open-world video depth estimation under zero-shot settings. Furthermore, DepthCrafter facilitates various downstream applications, including depth-based visual effects and conditional video generation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent image-to-3D reconstruction models have greatly advanced geometry generation, but they still struggle to faithfully generate realistic appearance. To address this, we introduce ARM, a novel method that reconstructs high-quality 3D meshes and realistic appearance from sparse-view images. The core of ARM lies in decoupling geometry from appearance, processing appearance within the UV texture space. Unlike previous methods, ARM improves texture quality by explicitly back-projecting measurements onto the texture map and processing them in a UV space module with a global receptive field. To resolve ambiguities between material and illumination in input images, ARM introduces a material prior that encodes semantic appearance information, enhancing the robustness of appearance decomposition. Trained on just 8 H100 GPUs, ARM outperforms existing methods both quantitatively and qualitatively.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Environment understanding in egocentric videos is an important step for applications like robotics, augmented reality and assistive technologies. These videos are characterized by dynamic interactions and a strong dependence on the wearer’s engagement with the environment. Traditional approaches often focus on isolated clips or fail to integrate rich semantic and geometric information, limiting scene comprehension. We introduce Dynamic Image-Video Feature Fields (DIV-FF), a framework that decomposes the egocentric scene into persistent, dynamic, and actor-based components while integrating both image and video-language features. Our model enables detailed segmentation, captures affordances, understands the surroundings and maintains consistent understanding over time. DIV-FF outperforms state-of-the-art methods, particularly in dynamically evolving scenarios, demonstrating its potential to advance long-term, spatio-temporal scene understanding.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
This work presents a novel text-to-vector graphics generation approach, Dream3DVG, allowing for arbitrary viewpoint viewing, progressive detail optimization, and view-dependent occlusion awareness. Our approach is a dual-branch optimization framework, consisting of an auxiliary 3D Gaussian Splatting optimization branch and a 3D vector graphics optimization branch. The introduced 3DGS branch can bridge the domain gaps between text prompts and vector graphics with more consistent guidance. Moreover, 3DGS allows for progressive detail control by scheduling classifier-free guidance, facilitating guiding vector graphics with coarse shapes at the initial stages and finer details at later stages. We also improve the view-dependent occlusions by devising a visibility-awareness rendering module. Extensive results on 3D sketches and 3D iconographies, demonstrate the superiority of the method on different abstraction levels of details, cross-view consistency, and occlusion-aware stroke culling.
|
|
Highlight
|
Poster
[ ExHall D ] 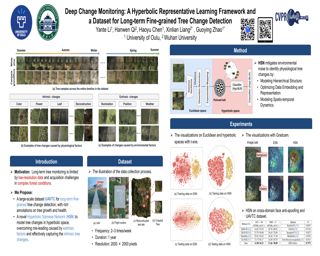
Abstract
In environmental protection, tree monitoring plays an essential role in maintaining and improving ecosystem health. However, precise monitoring is challenging because existing datasets fail to capture continuous fine-grained changes in trees due to low-resolution images and high acquisition costs. In this paper, we introduce UAVTC, a large-scale, long-term, high-resolution dataset collected using UAVs equipped with cameras, specifically designed to detect individual Tree Changes (TCs). UAVTC includes rich annotations and statistics based on biological knowledge, offering a fine-grained view for tree monitoring. To address environmental influences and effectively model the hierarchical diversity of physiological TCs, we propose a novel Hyperbolic Siamese Network (HSN) for TC detection, enabling compact and hierarchical representations of dynamic tree changes. Extensive experiments show that HSN can effectively capture complex hierarchical changes and provide a robust solution for fine-grained TC detection. In addition, HSN generalizes well to cross-domain face anti-spoofing task, highlighting its broader significance in AI. We believe our work, combining ecological insights and interdisciplinary expertise, will benefit the community by offering a new benchmark and innovative AI technologies. Source code and dataset will be made available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
How well are unimodal vision and language models aligned? Although prior work have approached answering this question, their assessment methods do not directly translate to how these models are used in practical vision-language tasks. In this paper, we propose a direct assessment method, inspired by linear probing, to assess vision-language alignment. We identify that the degree of alignment of the SSL vision models depends on their SSL training objective, and we find that the clustering quality of SSL representations has a stronger impact on alignment performance than their linear separability. Next, we introduce Swift Alignment of Image and Language (SAIL), a efficient transfer learning framework that aligns pretrained unimodal vision and language models for downstream vision-language tasks. Since SAIL leverages the strengths of pretrained unimodal models, it requires significantly fewer ($\sim$6\%) paired image-text data for the multimodal alignment compared to models like CLIP which are trained from scratch. SAIL training only requires a single A100 GPU, $\sim$5 hours of training and can accommodate a batch size up to 32,768. SAIL achieves 73.4\% zero-shot accuracy on ImageNet (vs. CLIP's 72.7\%) and excels in zero-shot retrieval, complex reasoning, and semantic segmentation. Additionally, SAIL improves the language-compatibility of vision encoders that in turn …
|
|
Highlight
|
Poster
[ ExHall D ] 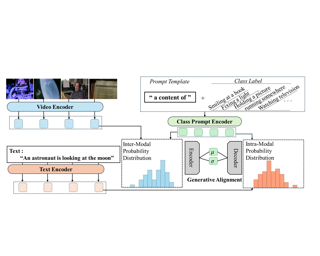
Abstract
Multi-modal understanding plays a crucial role in artificial intelligence by enabling models to jointly interpret inputs from different modalities. However, conventional approaches such as contrastive learning often struggle with modality discrepancies, leading to potential misalignments. In this paper, we propose a novel class anchor alignment approach that leverages class probability distributions for multi-modal representation learning. Our method, Class-anchor-ALigned generative Modeling (CALM), encodes class anchors as prompts to generate and align class probability distributions for each modality, enabling more flexible alignment. Furthermore, we introduce a cross-modal probabilistic variational autoencoder to model uncertainty in the alignment, enhancing the ability to capture deeper relationships between modalities and data variations. Extensive experiments on four benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, especially in out-of-domain evaluations. This highlights its superior generalization capabilities in multi-modal representation learning.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
3D graphics editing is a crucial component in applications like movie production and game design, yet it remains a time-consuming process that demands highly specialized domain expertise. Automating the process is challenging because graphical editing requires performing different tasks, each requiring distinct skill sets. Recently, multi-modal foundation models have emerged as a powerful framework for automating the editing process, but their development and evaluation are bottlenecked by the lack of a comprehensive benchmark that requires human-level perception and real-world editing complexity. In this work, we present BlenderGym, a benchmark designed to systematically evaluate foundational model systems for 3D graphics editing with tasks capturing the various aspects of 3D editing and fixed ground-truth for evaluation. We evaluate closed- and open-source VLMs with BlenderGym and observe that even the state-of-the-art VLMs struggle with tasks relatively easily for a novice Blender user. Enabled by BlenderGym, we study how inference scaling techniques impact graphics editing tasks. Notably, our findings reveal that the verifier used to guide the scaling of generation can itself be improved through scaling, complementing recent insights on scaling of LLM generation in coding and math tasks. We further show that inference compute is not uniformly effective and can be optimized by …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Training large foundation models of remote-sensing (RS) images is almost impossible due to the limited and long-tailed data problems. Fine-tuning natural image pre-trained models on RS images is a straightforward solution. To reduce computational costs and improve performance on tail classes, existing methods apply parameter-efficient fine-tuning (PEFT) techniques, such as LoRA and AdaptFormer. However, we observe that fixed hyperparameters -- such as intra-layer positions, layer depth, and scaling factors, can considerably hinder PEFT performance, as fine-tuning on RS images proves highly sensitive to these settings. To address this, we propose MetaPEFT, a method incorporating adaptive scalers that dynamically adjust module influence during fine-tuning. MetaPEFT dynamically adjusts three key factors of PEFT on RS images: module insertion, layer selection, and module-wise learning rates, which collectively control the influence of PEFT modules across the network. We conduct extensive experiments on three transfer-learning scenarios and five datasets. The results show that MetaPEFT achieves state-of-the-art performance in cross-spectral adaptation, requiring only a small amount of trainable parameters and improving tail-class accuracy significantly. Our code is available in the supplementary materials for review.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Micromobility, which utilizes lightweight devices moving in urban public spaces - such as delivery robots and electric wheelchairs - emerges as a promising alternative to vehicular mobility. Current micromobility depends mostly on human manual operation (in-person or remote control), which raises safety and efficiency concerns when navigating busy urban environments full of obstacles and pedestrians. Assisting humans with AI agents in maneuvering micromobility devices presents a viable solution for enhancing safety and efficiency. In this work, we present a scalable urban simulation solution to advance autonomous micromobility. First, we build URBAN-SIM -- a high-performance robot learning platform for large-scale training of embodied agents in interactive urban scenes. URBAN-SIM contains three critical modules: Hierarchical Urban Generation pipeline, Interactive Dynamics Generation strategy, and Asynchronous Scene Sampling scheme, to improve the diversity, realism, and efficiency of robot learning in simulation. Then, we propose URBAN-BENCH -- a suite of essential tasks and benchmarks to gauge various capabilities of the AI agents in achieving autonomous micromobility. URBAN-BENCH includes eight tasks based on three core skills of the agents: Urban Locomotion, Urban Navigation, and Urban Traverse. We evaluate four robots with heterogeneous embodiments, such as the wheeled and legged robots, across these tasks. Experiments on diverse …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Deep learning-based image registration methods have shown state-of-the-art performance and rapid inference speeds.Despite these advances, many existing approaches fall short in capturing spatially varying information in non-local regions of feature maps due to the reliance on spatially-shared convolution kernels. This limitation leads to suboptimal estimation of deformation fields. In this paper, we propose a 3D Spatial-Awareness Convolution Block (SACB) to enhance the spatial information within feature representations. Our SACB estimates the spatial clusters within feature maps by leveraging feature similarity and subsequently parameterizes the adaptive convolution kernels across diverse regions. This adaptive mechanism generates the convolution kernels (weights and biases) tailored to spatial variations, thereby enabling the network to effectively capture spatially varying information. Building on SACB, we introduce a pyramid flow estimator (named SACB-Net) that integrates SACBs to facilitate multi-scale flow composition, particularly addressing large deformations. Experimental results on the brain IXI and LPBA datasets as well as Abdomen CT datasets demonstrate the effectiveness of SACB and the superiority of SACB-Net over the state-of-the-art learning-based registration methods. The code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recently, the Image Prompt Adapter (IP-Adapter) has been increasingly integrated into text-to-image diffusion models (T2I-DMs) to improve controllability. However, in this paper, we reveal that T2I-DMs equipped with the IP-Adapter (T2I-IP-DMs) enable a new jailbreak attack named the hijacking attack. We demonstrate that, by uploading imperceptible image-space adversarial examples (AEs), the adversary can hijack massive benign users to jailbreak an Image Generation Service (IGS) driven by T2I-IP-DMs and mislead the public to discredit the service provider. Worse still, the IP-Adapter's dependency on open-source image encoders reduces the knowledge required to craft AEs. Extensive experiments verify the technical feasibility of the hijacking attack. In light of the revealed threat, we investigate several existing defenses and explore combining the IP-Adapter with adversarially trained models to overcome existing defenses' limitations.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The distributed nature of training makes Federated Learning (FL) vulnerable to backdoor attacks, where malicious model updates aim to compromise the global model’s performance on specific tasks. Existing defense methods show limited efficacy as they overlook the inconsistency between benign and malicious model updates regarding both general and fine-grained directions. To fill this gap, we introduce AlignIns, a novel defense method designed to safeguard FL systems against backdoor attacks. AlignIns looks into the direction of each model update through a direction alignment inspection process. Specifically, it examines the alignment of model updates with the overall update direction and analyzes the distribution of the signs of their significant parameters, comparing them with the principle sign across all model updates. Model updates that exhibit an unusual degree of alignment are considered malicious and thus be filtered out. We provide the theoretical analysis of the robustness of AlignIns and its propagation error in FL. Our empirical results on both independent and identically distributed (IID) and non-IID datasets demonstrate that AlignIns achieves higher robustness compared to the state-of-the-art defense methods. Code is available at \url{https://anonymous.4open.science/r/AlignIns}.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Detecting 3D objects in point clouds plays a crucial role in autonomous driving systems. Recently, advanced multi-modal methods incorporating camera information have achieved notable performance. For a safe and effective autonomous driving system, algorithms that excel not only in accuracy but also in speed and low latency are essential. However, existing algorithms fail to meet these requirements due to the latency and bandwidth limitations of fixed frame rate sensors, e.g., LiDAR and camera. To address this limitation, we introduce asynchronous event cameras into 3D object detection for the first time. We leverage their high temporal resolution and low bandwidth to enable high-speed 3D object detection. Our method enables detection even during inter-frame intervals when synchronized data is unavailable, by retrieving previous 3D information through the event camera. Furthermore, we introduce the first event-based 3D object detection dataset, DSEC-3DOD, which includes ground-truth 3D bounding boxes at 100 FPS, establishing the first benchmark for event-based 3D detectors. Our code and dataset will be publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We address the problem of gaze target estimation, which aims to predict where a person is looking in a scene. Predicting a person’s gaze target requires reasoning both about the person’s appearance and the contents of the scene. Prior works have developed increasingly complex, hand-crafted pipelines for gaze target estimation that carefully fuse features from separate scene encoders, head encoders, and auxiliary models for signals like depth and pose. Motivated by the success of general-purpose feature extractors on a variety of visual tasks, we propose Gaze-LLE, a novel transformer framework that streamlines gaze target estimation by leveraging features from a frozen DINOv2 encoder. We extract a single feature representation for the scene, and apply a person-specific positional prompt to decode gaze with a lightweight module. We demonstrate state-of-the-art performance across several gaze benchmarks and provide extensive analysis to validate our design choices.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
An interpretable comparison of generative models requires the identification of sample types produced differently by each of the involved models. While several quantitative scores have been proposed in the literature to rank different generative models, such score-based evaluations do not reveal the nuanced differences between the generative models in capturing various sample types. In this work, we attempt to solve a differential clustering problem to detect sample types expressed differently by two generative models. To solve the differential clustering problem, we propose a method called Fourier-based Identification of Novel Clusters (FINC) to identify modes produced by a generative model with a higher frequency in comparison to a reference distribution. FINC provides a scalable stochastic algorithm based on random Fourier features to estimate the eigenspace of kernel covariance matrices of two generative models and utilize the principal eigendirections to detect the sample types present more dominantly in each model. We demonstrate the application of the FINC method to large-scale computer vision datasets and generative model frameworks. Our numerical results suggest the scalability of the developed Fourier-based method in highlighting the sample types produced with different frequencies by widely-used generative models.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present Pippo, a generative model capable of producing a dense set of high-resolution (1K) multi-view images of a person from a single photo. Our approach does not require any parametric model fitting or camera parameters of the input image, and generalizes to arbitrary identities with diverse clothing and hair styles. Pippo is a multi-view diffusion transformer trained in multiple stages. First, we pretrain the model on a billion-scale human-centric image dataset. Second, we train the model on studio data to generate many low-resolution consistent views conditioned on a coarse camera and an input image. Finally, we fine-tune the model on high-resolution data for multi-view generation with minimal placement controls, further improving consistency. This training strategy allows us to retain the generalizability from the large-scale pretraining while enabling high-resolution multi-view synthesis. We investigate several key architecture design choices for multi-view generation with diffusion transformers for precise view and identity control. Using a newly introduced 3D consistency metric, we demonstrate that Pippo outperforms existing approaches on multi-view human generation from a single image.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Image restoration aims to recover content from inputs degraded by various factors, such as adverse weather, blur, and noise. Perceptual Image Restoration (PIR) methods improve visual quality but often do not support downstream tasks effectively. On the other hand, Task-oriented Image Restoration (TIR) methods focus on enhancing image utility for high-level vision tasks, sometimes compromising visual quality. This paper introduces UniRestore, a unified image restoration model that bridges the gap between PIR and TIR by using a diffusion prior. The diffusion prior is designed to generate images that align with human visual quality preferences, but these images are often unsuitable for TIR scenarios. To solve this limitation, UniRestore utilizes encoder features from an autoencoder to adapt the diffusion prior to specific tasks. We propose a Complementary Feature Restoration Module (CFRM) to reconstruct degraded encoder features and a Task Feature Adapter (TFA) module to facilitate adaptive feature fusion in the decoder. This design allows UniRestore to optimize images for both human perception and downstream task requirements, addressing discrepancies between visual quality and functional needs. Integrating these modules also enhances UniRestore’s adapability and efficiency across diverse tasks. Extensive expertments demonstrate the superior performance of UniRestore in both PIR and TIR scenarios.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The emergence of vision-language foundation models, such as CLIP, has revolutionized image-text representation, enabling a broad range of applications via prompt learning. Despite its promise, real-world datasets often contain noisy labels that can degrade prompt learning performance. In this paper, we demonstrate that using mean absolute error (MAE) loss in prompt learning, named PromptMAE, significantly enhances robustness against noisy labels while maintaining high accuracy. Though MAE is straightforward and recognized for its robustness, it is rarely used in noisy-label learning due to its slow convergence and poor performance outside prompt learning scenarios. To elucidate the robustness of PromptMAE, we leverage feature learning theory to show that MAE can suppress the influence of noisy samples, thereby improving the signal-to-noise ratio and enhancing overall robustness. Additionally, we introduce PromptOT, a prompt-based optimal transport data purification method to enhance the robustness further. PromptOT employs text encoder representations in vision-language models as prototypes to construct an optimal transportation matrix. This matrix effectively partitions datasets into clean and noisy subsets, allowing for the application of cross-entropy loss to the clean subset and MAE loss to the noisy subset. Our Noise-Label Prompt Learning method, named NLPrompt, offers a simple and efficient approach that leverages the expressive …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Global effective receptive field plays a crucial role for image style transfer (ST) to obtain high-quality stylized results. However, existing ST backbones (e.g., CNNs and Transformers) suffer huge computational complexity to achieve global receptive fields. Recently, the State Space Model (SSM), especially the improved variant Mamba, has shown great potential for long-range dependency modeling with linear complexity, which offers a approach to resolve the above dilemma. In this paper, we develop a Mamba-based style transfer framework, termed SaMam. Specifically, a mamba encoder is designed to efficiently extract content and style information. In addition, a style-aware mamba decoder is developed to flexibly adapt to various styles. Moreover, to address the problems of local pixel forgetting, channel redundancy and spatial discontinuity of existing SSMs, we introduce both local enhancement and zigzag scan. Qualitative and quantitative results demonstrate that our SaMam outperforms state-of-the-art methods in terms of both accuracy and efficiency.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Zero-shot object counting aims to count instances of arbitrary object categories specified by text descriptions. Existing methods typically rely on vision-language models like CLIP, but often exhibit limited sensitivity to text prompts. We present T2ICount, a one-step diffusion-based framework that leverages rich prior knowledge and fine-grained visual understanding from pretrained diffusion models. While one-step denoising ensures efficiency, it leads to weakened text sensitivity. To address this challenge, we propose a Hierarchical Semantic Correction Module that progressively refines text-image feature alignment, and a Representational Regional Coherence Loss that provides reliable supervision signals by leveraging the cross-attention maps extracted from the denosing U-Net. Furthermore, we observe that current benchmarks mainly focus on majority objects in images, potentially masking models' text sensitivity. To address this, we contribute a challenging re-annotated subset of FSC147 for better evaluation of text-guided counting ability. Extensive experiments demonstrate that our method achieves superior performance across different benchmarks. Code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Realistic 3D full-body talking avatars hold great potential in AR, with applications ranging from e-commerce live streaming to holographic communication. Despite advances in 3D Gaussian Splatting (3DGS) for lifelike avatar creation, existing methods struggle with fine-grained control of facial expressions and body movements in full-body talking tasks. Additionally, they often lack sufficient details and cannot run in real-time on mobile devices. We present TaoAvatar, a high-fidelity, lightweight, 3DGS-based full-body talking avatar driven by various signals. Our approach starts by creating a personalized clothed human parametric template that binds Gaussians to represent appearances. We then pre-train a StyleUnet-based network to handle complex pose-dependent non-rigid deformation, which can capture high-frequency appearance details but is too resource-intensive for mobile devices. To overcome this, we "bake" the non-rigid deformations into a lightweight MLP-based network using a distillation technique and develop blend shapes to compensate for details. Extensive experiments show that TaoAvatar achieves state-of-the-art rendering quality while running in real-time across various devices, maintaining 90 FPS on high-definition stereo devices such as the Apple Vision Pro.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Customized text-to-image generation renders user-specified concepts into novel contexts based on textual prompts. Scaling the number of concepts in customized generation meets a broader demand for user creation, whereas existing methods face challenges with generation quality and computational efficiency. In this paper, we propose LaTexBlend, a novel framework for effectively and efficiently scaling multi-concept customized generation. The core idea of LaTexBlend is to represent single concepts and blend multiple concepts within a Latent Textual space, which is positioned after the text encoder and a linear projection. LaTexBlend customizes each concept individually, storing them in a concept bank with a compact representation of latent textual features that captures sufficient concept information to ensure high fidelity. At inference, concepts from the bank can be freely and seamlessly combined in the latent textual space, offering two key merits for multi-concept generation: 1) excellent scalability, and 2) significant reduction of denoising deviation, preserving coherent layouts. Extensive experiments demonstrate that LaTexBlend can flexibly integrate multiple customized concepts with harmonious structures and high subject fidelity, substantially outperforming baselines in both generation quality and computational efficiency. Our code will be publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent open-vocabulary detectors achieve promising performance with abundant region-level annotated data. In this work, we show that an open-vocabulary detector co-training with a large language model by generating image-level detailed captions for each image can further improve performance. To achieve the goal, we first collect a dataset, GroundingCap-1M, wherein each image is accompanied by associated grounding labels and an image-level detailed caption. With this dataset, we finetune an open-vocabulary detector with training objectives including a standard grounding loss and a caption generation loss. We take advantage of a large language model to generate both region-level short captions for each region of interest and image-level long captions for the whole image. Under the supervision of the large language model, the resulting detector, LLMDet, outperforms the baseline by a clear margin, enjoying superior open-vocabulary ability. Further, we show that the improved LLMDet can in turn build a stronger large multi-modal model, achieving mutual benefits. The code, model, and dataset will be available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
3D characters are essential to modern creative industries, but making them animatable often demands extensive manual work in tasks like rigging and skinning. Existing automatic rigging tools face several limitations, including the necessity for manual annotations, rigid skeleton topologies, and limited generalization across diverse shapes and poses. An alternative approach generates animatable avatars pre-bound to a rigged template mesh. However, this method often lacks flexibility and is typically limited to realistic human shapes. To address these issues, we present Make-It-Animatable, a novel data-driven method to make any 3D humanoid model ready for character animation in less than one second, regardless of its shapes and poses. Our unified framework generates high-quality blend weights, bones, and pose transformations. By incorporating a particle-based shape autoencoder, our approach supports various 3D representations, including meshes and 3D Gaussian splats. Additionally, we employ a coarse-to-fine representation and a structure-aware modeling strategy to ensure both accuracy and robustness, even for characters with non-standard skeleton structures. We conducted extensive experiments to validate our framework's effectiveness. Compared to existing methods, our approach demonstrates significant improvements in both quality and speed. The source code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Without using explicit reward, direct preference optimization (DPO) employs paired human preference data to fine-tune generative models, a method that has garnered considerable attention in large language models (LLMs). However, exploration of aligning text-to-image (T2I) diffusion models with human preferences remains limited. In comparison to supervised fine-tuning, existing methods that align diffusion model suffer from low training efficiency and subpar generation quality due to the long Markov chain process and the intractability of the reverse process. To address these limitations, we introduce DDIM-InPO, an efficient method for direct preference alignment of diffusion models. Our approach conceptualizes diffusion model as a single-step generative model, allowing us to fine-tune the outputs of specific latent variables selectively. In order to accomplish this objective, we first assign implicit rewards to any latent variable directly via a reparameterization technique. Then we construct an Inversion technique to estimate appropriate latent variables for preference optimization. This modification process enables the diffusion model to only fine-tune the outputs of latent variables that have a strong correlation with the preference dataset. Experimental results indicate that our DDIM-InPO achieves state-of-the-art performance with just 400 steps of fine-tuning, surpassing all preference aligning baselines for T2I diffusion models in human preference evaluation …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Estimating touch contact and pressure in egocentric vision is a central task for downstream applications in Augmented Reality, Virtual Reality, as well as many robotic applications, because it provides precise physical insights into hand-object interaction and object manipulation. However, existing contact pressure datasets lack egocentric views and hand poses, which are essential for accurate estimation during in-situ operation, both for AR/VR interaction and robotic manipulation.In this paper, we introduce a novel dataset of touch contact and pressure interaction from an egocentric perspective, complemented with hand pose meshes and fine-grained pressure intensities for each contact. The hand poses in our dataset are optimized using our proposed multi-view sequence-based method that processes footage from our capture rig of 8 accurately calibrated RGBD cameras. comprises 5.0 hours of touch contact and pressure interaction from 21 participants captured by a moving egocentric camera and 7 stationary Kinect cameras, which provided RGB images and depth maps at 30 Hz. In addition, we provide baselines for estimating pressure with different modalities, which will enable future developments and benchmarking on the dataset. Overall, we demonstrate that pressure and hand poses are complementary, which supports our intention to better facilitate the physical understanding of hand-object interactions in AR/VR …
|
|
Highlight
|
Poster
[ ExHall D ] 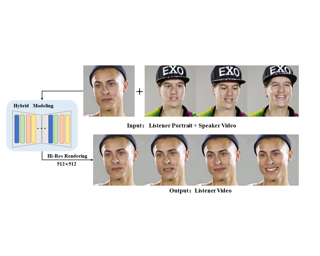
Abstract
Listening head generation aims to synthesize non-verbal responsive listening head videos that naturally react to a certain speaker, for which, both realistic head movements, expressive facial expressions, and high visual qualities are expected. Previous approaches typically follow a two-stage pipeline that first generates intermediate 3D motion signals such as 3DMM coefficients, and then synthesizes the videos by deterministic rendering, suffering from limited motion expressiveness and low visual quality (eg, $256 \times 256)$. In this work, we propose a novel listening head generation method that harnesses the generative capabilities of the diffusion model for both motion generation and high-quality rendering. Crucially, we propose an effective hybrid motion modeling module that addresses training difficulties caused by the scarcity of listening head data while preserving the intricate details that may be lost in explicit motion representations. We further develop a tailored control guidance for head pose and facial expression, by integrating their intrinsic motion characteristics. Our method enables high-fidelity video generation with $512\times 512$ resolution and delivers vivid listener motion feedback. We conduct comprehensive experiments and obtain superior performance in terms of both visual quality and motion expressiveness compared to existing methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Image Quality Assessment (IQA) based on human subjective preferences has undergone extensive research in the past decades. However, with the development of communication protocols, the visual data consumption volume of machines has gradually surpassed that of humans. For machines, the preference depends on downstream tasks such as segmentation and detection, rather than visual appeal. Considering the huge gap between human and machine visual systems, this paper proposes the topic: **Image Quality Assessment for Machine Vision** for the first time. Specifically, we (1) defined the subjective preferences of machines, including downstream tasks, test models, and evaluation metrics; (2) established the Machine Preference Database (MPD), which contains 2.25M fine-grained annotations and 30k reference/distorted image pair instances; (3) verified the performance of mainstream IQA algorithms on MPD. Experiments show that current IQA metrics are human-centric and cannot accurately characterize machine preferences. We sincerely hope that MPD can promote the evolution of IQA from human to machine preferences.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
With the rapid growth of social media and digital photography, visually appealing images have become essential for effective communication and emotional engagement. Among the factors influencing aesthetic appeal, composition—the arrangement of visual elements within a frame—plays a crucial role. In recent years, specialized models for photographic composition have achieved impressive results across various aesthetic tasks. Meanwhile, rapidly advancing multimodal large language models (MLLMs) have excelled in several visual perception tasks. However, their ability to embed and understand compositional information remains underexplored, primarily due to the lack of suitable evaluation datasets. To address this gap, we introduce the Photographic Image Composition Dataset (PICD), a large-scale dataset consisting of 36,857 images categorized into 24 composition categories across 355 diverse scenes. We demonstrate the advantages of PICD over existing datasets in terms of data scale, composition category, label quality, and scene diversity. Building on PICD, we establish benchmarks to evaluate the composition embedding capabilities of specialized models and the compositional understanding ability of MLLMs. To enable efficient and effective evaluation, we propose a novel Composition Discrimination Accuracy (CDA) metric. Our evaluation highlights the limitations of current models and provides insights into directions for improving their ability to embed and understand composition.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Symmetry is a ubiquitous and fundamental property in the visual world, serving as a critical cue for perception and structure interpretation. This paper investigates the detection of 3D reflection symmetry from a single RGB image, and reveals its significant benefit on single-image 3D generation. We introduce Reflect3D, a scalable, zero-shot symmetry detector capable of robust generalization to diverse and real-world scenarios. Inspired by the success of foundation models, our method scales up symmetry detection with a transformer-based architecture. We also leverage generative priors from multi-view diffusion models to address the inherent ambiguity in single-view symmetry detection. Extensive evaluations on various data sources demonstrate that Reflect3D establishes a new state-of-the-art in single-image symmetry detection. Furthermore, we show the practical benefit of incorporating detected symmetry into single-image 3D generation pipelines through a symmetry-aware optimization process. The integration of symmetry significantly enhances the structural accuracy, cohesiveness, and visual fidelity of the reconstructed 3D geometry and textures, advancing the capabilities of 3D content creation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Over the last decade, many notable methods have emerged to tackle the computational resource challenge of the high resolution image recognition (HRIR). They typically focus on identifying and aggregating a few salient regions for classification, discarding sub-salient areas for low training consumption. Nevertheless, many HRIR tasks necessitate the exploration of wider regions to model objects and contexts, which limits their performance in such scenarios. To address this issue, we present a DBPS strategy to enable training with more patches at low consumption. Specifically, in addition to a fundamental buffer that stores the embeddings of most salient patches, DBPS further employs an auxiliary buffer to recycle those sub-salient ones. To reduce the computational cost associated with gradients of sub-salient patches, these patches are primarily used in the forward pass to provide sufficient information for classification. Meanwhile, only the gradients of the salient patches are back-propagated to update the entire network. Moreover, we design a Multiple Instance Learning (MIL) architecture that leverages aggregated information from salient patches to filter out uninformative background within sub-salient patches for better accuracy. Besides, we introduce the random patch drop to accelerate training process and uncover informative regions. Experiment results demonstrate the superiority of our method in …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Rolling shutter (RS) cameras dominate consumer and smartphone markets. Several methods for computing the absolute pose of RS cameras have appeared in the last 20 years, but the relative pose problem has not been fully solved yet. We provide a unified theory for the important class of order-one rolling shutter (RS$_1$) cameras. These cameras generalize the perspective projection to RS cameras, projecting a generic space point to exactly one image point via a rational map. We introduce a new back-projection RS camera model, characterize RS$_1$ cameras, construct explicit parameterizations of such cameras, and determine the image of a space line. We classify all minimal problems for solving the relative camera pose problem with linear RS$_1$ cameras and discover new practical cases. Finally, we show how the theory can be used to explain RS models previously used for absolute pose computation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Scene generation with 3D assets presents a complex challenge, requiring both high-level semantic understanding and low-level geometric reasoning. While Multimodal Large Language Models (MLLMs) excel at semantic tasks, their application to 3D scene generation is hindered by their limited grounding on 3D geometry. In this paper, we investigate how to best work with MLLMs in an object placement task. Towards this goal, we introduce a novel framework, FirePlace, that applies existing MLLMs in (1) 3D geometric reasoning and the extraction of relevant geometric details from the 3D scene, (2) constructing and solving geometric constraints on the extracted low-level geometry, and (3) pruning for final placements that conform to common sense. By combining geometric reasoning with real-world understanding of MLLMs, our method can propose object placements that satisfy both geometric constraints as well as high-level semantic common-sense considerations. Our experiments show that these capabilities allow our method to place objects more effectively in complex scenes with intricate geometry, surpassing the quality of prior work.
|
|
Highlight
|
Poster
[ ExHall D ] 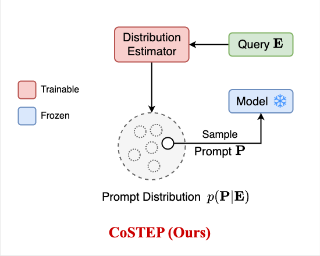
Abstract
Recent advancements in prompt-based learning have significantly advanced image and video class-incremental learning. However, the prompts learned by these methods often fail to capture the diverse and informative characteristics of videos, and struggle to generalize effectively to future tasks and classes. To address these challenges, this paper proposes modeling the distribution of space-time prompts conditioned on the input video using a diffusion model. This generative approach allows the proposed model to naturally handle the diverse characteristics of videos, leading to more robust prompt learning and enhanced generalization capabilities. Additionally, we develop a mechanism that transfers the token relationship modeling capabilities of a pre-trained image transformer to spatio-temporal modeling for videos. Our approach has been thoroughly evaluated across four established benchmarks, showing remarkable improvements over existing state-of-the-art methods in video class-incremental learning.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Generative models have made significant impacts across various domains, largely due to their ability to scale during training by increasing data, computational resources, and model size, a phenomenon characterized by the scaling laws. Recent research has begun to explore inference-time scaling behavior in large language models (LLMs), revealing how performance can further improve with additional computation during inference. Unlike LLMs, diffusion models inherently possess the flexibility to adjust inference-time computation via the number of function evaluations (NFE), although the performance gains typically flatten after a few dozen steps. In this work, we present a framework on the inference-time scaling for diffusion models, that enables diffusion models to further benefit from the increased computation beyond the NFE plateau. Specifically, we consider a search problem aimed at identifying better noises during the sampling process. We structure the design space along two axes: the verifiers used to provide feedback, and the algorithms used to find better candidates. Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time compute leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Quad Photodiode (QPD) sensors represent an evolution by providing four sub-views, whereas dual-pixel (DP) sensors are limited to two sub-views. In addition to enhancing auto-focus performance, QPD sensors also enable disparity estimation in horizontal and vertical directions. However, the characteristics of QPD sensors, including uneven illumination across sub-views and the narrow baseline, render algorithm design difficult. Furthermore, effectively utilizing the two-directional disparity of QPD sensors remains a challenge. The scarcity of QPD disparity datasets also limits the development of learning-based methods. In this work, we address these challenges by first proposing a DPNet for DP disparity estimation. Specifically, we design an illumination-invariant module to reduce the impact of illumination, followed by a coarse-to-fine module to estimate sub-pixel disparity. Building upon the DPNet, we further propose a QuadNet, which integrates the two-directional disparity via an edge-aware fusion module. To facilitate the evaluation of our approaches, we propose the first QPD disparity dataset QPD2K, comprising 2,100 real-world QPD images and corresponding disparity maps. Experiments demonstrate that our approaches achieve state-of-the-art performance in DP and QPD disparity estimation.
|
|
Highlight
|
Poster
[ ExHall D ] 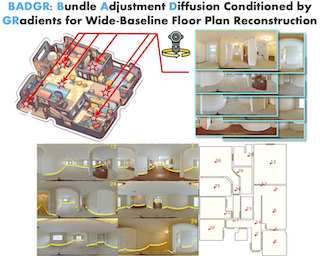
Abstract
Reconstructing precise camera poses and floor plan layouts from a set of wide-baseline RGB panoramas is a difficult and unsolved problem. We present BADGR, a novel diffusion model which performs both reconstruction and bundle adjustment (BA) optimization tasks, to refine camera poses and layouts from a given coarse state using 1D floor boundary information from dozens of images of varying input densities. Unlike a guided diffusion model, BADGR is conditioned on dense per-feature outputs from a single-step Levenberg-Marquardt (LM) optimizer and is trained to predict camera and wall positions while minimizing reprojection errors for view-consistency. The objective of layout generation from denoising diffusion process complements BA optimization by providing additional learned layout-structural constraints on top of the co-visible features across images. These constraints help BADGR to make plausible guesses on spatial relations which help constrain pose graph, such as wall adjacency, collinearity, and learn to mitigate errors from dense boundary observations with global contexts. BADGR trains exclusively on 2D floor plans, simplifying data acquisition, enabling robust augmentation, and supporting variety of input densities. Our experiments and analysis validate our method, which significantly outperforms the state-of-the-art pose and floor plan layouts reconstruction with different input densities.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce a single-view reconstruction technique of volumetric fields in which multiple light scattering effects are omnipresent, such as in clouds. We model the unknown distribution of volumetric fields using an unconditional diffusion model trained on a novel benchmark dataset comprising 1,000 synthetically simulated volumetric density fields. The neural diffusion model is trained on the latent codes of a novel, diffusion-friendly, monoplanar representation. The generative model is used to incorporate a tailored parametric diffusion posterior sampling technique into different reconstruction tasks. A physically-based differentiable volume renderer is employed to provide gradients with respect to light transport in the latent space. This stands in contrast to classic NeRF approaches and makes the reconstructions better aligned with observed data. Through various experiments, we demonstrate single-view reconstruction of volumetric clouds at a previously unattainable quality.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The feature attribution method reveals the contribution of input variables to the decision-making process to provide an attribution map for explanation. Existing methods grounded on the information bottleneck principle compute information in a specific layer to obtain attributions, compressing the features by injecting noise via a parametric damping ratio. However, the attribution obtained in a specific layer neglects evidence of the decision-making process distributed across layers. In this paper, we introduce a comprehensive information bottleneck (CoIBA), which discovers the relevant information in each targeted layer to explain the decision-making process. Our core idea is applying information bottleneck in multiple targeted layers to estimate the comprehensive information by sharing a parametric damping ratio across the layers. Leveraging this shared ratio complements the over-compressed information to discover the omitted clues of the decision by sharing the relevant information across the targeted layers. We suggest the variational approach to fairly reflect the relevant information of each layer by upper bounding layer-wise information. Therefore, CoIBA guarantees that the discarded activation is unnecessary in every targeted layer to make a decision. The extensive experimental results demonstrate the enhancement in faithfulness of the feature attributions provided by CoIBA.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Feed-forward 3D Gaussian Splatting (3DGS) models have gained significant popularity due to their ability to generate scenes immediately without needing per-scene optimization.Although omnidirectional images are getting more popular since they reduce the computation for image stitching to composite a holistic scene, existing feed-forward models are only designed for perspective images.The unique optical properties of omnidirectional images make it difficult for feature encoders to correctly understand the context of the image and make the Gaussian non-uniform in space, which hinders the image quality synthesized from novel views.We propose OmniSplat, a pioneering work for fast feed-forward 3DGS generation from a few omnidirectional images.We introduce Yin-Yang grid and decompose images based on it to reduce the domain gap between omnidirectional and perspective images.The Yin-Yang grid can use the existing CNN structure as it is, but its quasi-uniform characteristic allows the decomposed image to be similar to a perspective image, so it can exploit the strong prior knowledge of the learned feed-forward network.OmniSplat demonstrates higher reconstruction accuracy than existing feed-forward networks trained on perspective images.Furthermore, we enhance the segmentation consistency between omnidirectional images by leveraging attention from the encoder of OmniSplat, providing fast and clean 3DGS editing results.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent advances in image inpainting increasingly use generative models to handle large irregular masks. However, these models can create unrealistic inpainted images due to two main issues: (1) Context Instability: Even with unmasked areas as context, generative models may still generate arbitrary objects in the masked region that don’t align with the rest of the image. (2) Hue Inconsistency: Inpainted regions often have color shifts that causes a smeared appearance, reducing image quality.Retraining the generative model could help solve these issues, but it’s costly since state-of-the-art latent-based diffusion and rectified flow models require a three-stage training process: training a VAE, training a generative U-Net or transformer, and fine-tuning for inpainting.Instead, this paper proposes a post-processing approach, dubbed as ASUKA (Aligned Stable inpainting with UnKnown Areas prior), to improve inpainting models. To address context instability, we leverage a Masked Auto-Encoder (MAE) for reconstruction-based priors. This strengthens context alignment while maintaining the model's generation capabilities. To address hue inconsistency, we propose a specialized VAE decoder that treats latent-to-image decoding as a local harmonization task, significantly reducing color shifts for hue-consistent inpainting. We validate ASUKA on SD 1.5 and FLUX inpainting variants using the Places2 benchmark and MISATO, our proposed diverse collection of …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Large Vision-Language Models (LVLMs) have obtained impressive performance in visual content understanding and multi-modal reasoning. Unfortunately, these large models suffer from serious hallucination problems and tend to generate fabricated responses. Recently, several Contrastive Decoding (CD) strategies have been proposed to alleviate hallucination by introducing disturbed inputs. Although great progress has been made, these CD strategies mostly apply a one-size-fits-all approach for all input conditions. In this paper, we revisit this process through extensive experiments. Related results show that hallucination causes are hybrid and each generative step faces a unique hallucination challenge. Leveraging these meaningful insights, we introduce a simple yet effective Octopus-like framework that enables the model to adaptively identify hallucination types and create a dynamic CD workflow. Our Octopus framework not only outperforms existing methods across four benchmarks but also demonstrates excellent deployability and expansibility. Our code will be released.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Observing objects of small size has always been a charming pursuit of human beings.However, due to the physical phenomenon of diffraction, the optical resolution is restricted to approximately half the wavelength of light, which impedes the observation of subwavelength objects, typically smaller than 200 nm. This constrains its application in numerous scientific and industrial fields that aim to observe objects beyond the diffraction limit, such as native state coronavirus inspection.Fortunately, deep learning methods have shown remarkable potential in uncovering underlying patterns within data, promising to overcome the diffraction limit by revealing the mapping pattern between diffraction images and their corresponding ground truth object localization images. However, the absence of suitable datasets has hindered progress in this field - collecting high-quality optical data of subwavelength objects is very challenging as these objects are inherently invisible under conventional microscopy, making it impossible to perform standard visual calibration and drift correction. Therefore, in collaboration with top optical scientists, we provide the first general optical imaging dataset based on the "LEGO" concept for addressing the diffraction limit. Drawing an analogy to the modular construction of the LEGO blocks, we construct a comprehensive optical imaging dataset comprising subwavelength fundamental elements, *i.e.*, small square units that …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recently single-view 3D generation via Gaussian splatting has emerged and developed quickly. They learn 3D Gaussians from 2D RGB images generated from pre-trained multi-view diffusion (MVD) models, and have shown a promising avenue for 3D generation through a single image. Despite the current progress, these methods still suffer from the inconsistency jointly caused by the geometric ambiguity in the 2D images, and the lack of structure of 3D Gaussians, leading to distorted and blurry 3D object generation. In this paper, we propose to fix these issues by GS-RGBN, a new RGBN-volume Gaussian Reconstruction Model designed to generate high-fidelity 3D objects from single-view images. Our key insight is a structured 3D representation can simultaneously mitigate the afore-mentioned two issues. To this end, we propose a novel hybrid Voxel-Gaussian representation, where a 3D voxel representation contains explicit 3D geometric information, eliminating the geometric ambiguity from 2D images. It also structures Gaussians during learning so that the optimization tends to find better local optima. Our 3D voxel representation is obtained by a fusion module that aligns RGB features and surface normal features, both of which can be estimated from 2D images. Extensive experiments demonstrate the superiority of our methods over prior works in …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Despite their remarkable performance, modern Diffusion Transformers (DiTs) are hindered by substantial resource requirements during inference, stemming from the fixed and large amount of compute needed for each denoising step. In this work, we revisit the conventional static paradigm that allocates a fixed compute budget per denoising iteration and propose a dynamic strategy instead. Our simple and sample-efficient framework enables pre-trained DiT models to be converted into flexible ones --- dubbed FlexiDiT --- allowing them to process inputs at varying compute budgets. We demonstrate how a single flexible model can generate images without any drop in quality, while reducing the required FLOPs by more than $40$\% compared to their static counterparts, for both class-conditioned and text-conditioned image generation. Our method is general and agnostic to input and conditioning modalities. We show how our approach can be readily extended for video generation, where FlexiDiT models generate samples with up to $75$\% less compute without compromising performance.
|
|
Highlight
|
Poster
[ ExHall D ] 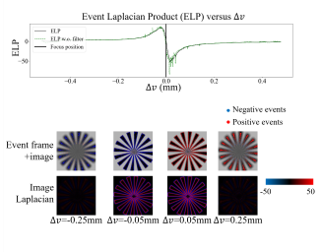
Abstract
High-speed autofocus in extreme scenes remains a significant challenge. Traditional methods rely on repeated sampling around the focus position, resulting in ''focus hunting''. Event-driven methods have advanced focusing speed and improved performance in low-light conditions; however, current approaches still require at least one lengthy round of ''focus hunting'', involving the collection of a complete focus stack. We introduce the Event Laplacian Product (ELP) focus detection function, which combines event data with grayscale Laplacian information, redefining focus search as a detection task. This innovation enables the first one-step event-driven autofocus, cutting focusing time by up to two-thirds and reducing focusing error by 24 times on the DAVIS346 dataset and 22 times on the EVK4 dataset. Additionally, we present an autofocus pipeline tailored for event-only cameras, achieving accurate results across a range of challenging motion and lighting conditions. All datasets and code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Human image generation is a key focus in image synthesis due to its broad applications. However, generating high-quality human images remains challenging because even slight inaccuracies in anatomy, pose, or fine details can compromise visual realism. To address these challenges, we explore Direct Preference Optimization (DPO), a method that trains models to generate images similar to preferred (winning) images while diverging from non-preferred (losing) ones. Conventional DPO approaches typically employ generated images as winning images, which may limit the model's ability to achieve high levels of realism. To overcome this limitation, we propose an enhanced DPO approach that incorporates high-quality real images as winning images, encouraging the model to produce outputs that resemble those real images rather than generated ones. Specifically, our approach, \textbf{HG-DPO} (\textbf{H}uman image \textbf{G}eneration through \textbf{DPO}), employs a novel curriculum learning framework that allows the model to gradually improve toward generating realistic human images, making the training more feasible than attempting the improvement all at once. Furthermore, we demonstrate that HG-DPO effectively adapts to personalized text-to-image tasks, generating high-quality, identity-specific images, which highlights the practical value of our approach.
|
|
Highlight
|
Poster
[ ExHall D ] 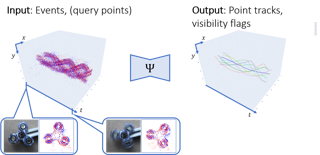
Abstract
Tracking any point (TAP) recently shifted the motion estimation paradigm from focusing on individual salient points with local templates to tracking arbitrary points with global image contexts. However, while research has mostly focused on driving the accuracy of models in nominal settings, addressing scenarios with difficult lighting conditions and high-speed motions remains out of reach due to the limitations of the sensor. This work addresses this challenge with the first event camera-based TAP method. It leverages the high temporal resolution and high dynamic range of event cameras for robust high-speed tracking, and the global contexts in TAP methods to handle asynchronous and sparse event measurements. We further extend the TAP framework to handle event feature variations induced by motion - thereby addressing an open challenge in purely event-based tracking - with a novel feature alignment loss which ensures the learning of motion-robust features. Our method is trained with data from a new data generation pipeline and systematically ablated across all design decisions. Our method shows strong cross-dataset generalization and performs 135% better on the average Jaccard metric than the baselines. Moreover, on an established feature tracking benchmark, it achieves a 19% improvement over the previous best event-only method and even …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this research, we propose a novel denoising diffusion model based on shortest-path modeling that optimizes residual propagation to enhance both denoising efficiency and quality. Drawing on Denoising Diffusion Implicit Models (DDIM) and insights from graph theory, our model, termed the Shortest Path Diffusion Model (ShortDF), treats the denoising process as a shortest-path problem aimed at minimizing reconstruction error. By optimizing the initial residuals, we improve the efficiency of the reverse diffusion process and the quality of the generated samples. Extensive experiments on multiple standard benchmarks demonstrate that ShortDF significantly reduces diffusion time (or steps) while enhancing the visual fidelity of generated samples compared to prior methods. This work, we suppose, paves the way for interactive diffusion-based applications and establishes a foundation for rapid data generation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Trajectory prediction plays a crucial role in autonomous driving systems, and exploring its vulnerability has garnered widespread attention. However, existing trajectory prediction attack methods often rely on single-point attacks to make efficient perturbations. This limits their applications in real-world scenarios due to the transient nature of single-point attacks, their susceptibility to filtration, and the uncertainty regarding the deployment environment. To address these challenges, this paper proposes a novel LiDAR-induced attack framework to impose multi-frame attacks by optimization-driven adversarial location search, achieving endurance, efficiency, and robustness. This framework strategically places objects near the adversarial vehicle to implement an attack and introduces three key innovations. First, successive state perturbations are generated using a multi-frame single-point attack strategy, effectively misleading trajectory predictions over extended time horizons. Second, we efficiently optimize adversarial objects' locations through three specialized loss functions to achieve desired perturbations. Lastly, we improve robustness by treating the adversarial object as a point without size constraints during the location search phase and reduce dependence on both the specific attack point and the adversarial object's properties. Extensive experiments confirm the superior performance and robustness of our framework.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Capturing high dynamic range (HDR) scenes is one of the most important issues in camera design. Majority of cameras use exposure fusion technique, which fuses images captured by different exposure levels, to increase dynamic range. However, this approach can only handle images with limited exposure difference, normally 3-4 stops. When applying to very high dynamic scenes where a large exposure difference is required, this approach often fails due to incorrect alignment or inconsistent lighting between inputs, or tone mapping artifacts. In this work, we propose UltraFusion, the first exposure fusion technique that can merge input with 9 stops differences. The key idea is that we model the exposure fusion as a guided inpainting problem, where the under-exposed image is used as a guidance to fill the missing information of over-exposed highlight in the over-exposed region. Using under-exposed image as a soft guidance, instead of a hard constrain, our model is robust to potential alignment issue or lighting variations. Moreover, utilizing the image prior of the generative model, our model also generates natural tone mapping, even for very high-dynamic range scene. Our approach outperforms HDR-Transformer on latest HDR benchmarks. Moreover, to test its performance in ultra high dynamic range scene, we …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present GEN3C, a generative video model with precise Camera Control and temporal 3D Consistency. Prior video models already generate realistic videos, but they tend to leverage little 3D information, leading to inconsistencies, such as objects popping in and out of existence. Camera control, if implemented at all, is imprecise, because camera parameters are mere inputs to the neural network which must then infer how the video depends on the camera. In contrast, GEN3C is guided by a 3D cache: point clouds obtained by predicting the pixel-wise depth of seed images or previously generated frames. When generating the next frames, GEN3C is conditioned on the 2D renderings of the 3D cache with the new camera trajectory provided by the user. Crucially, this means that GEN3C neither has to remember what it previously generated nor does it have to infer the image structure from the camera pose. The model, instead, can focus all its generative power on previously unobserved regions, as well as advancing the scene state to the next frame. Our results demonstrate more precise camera control than prior work, as well as state-of-the-art results in sparse-view novel view synthesis, even in challenging settings such as driving scenes and monocular …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Personalized 3D avatar editing holds significant promise due to its user-friendliness and availability to applications such as AR/VR and virtual try-ons. Previous studies have explored the feasibility of 3D editing, but often struggle to generate visually pleasing results, possibly due to the unstable representation learning under mixed optimization of geometry and texture in complicated reconstructed scenarios. In this paper, we aim to provide an accessible solution for ordinary users to create their editable 3D avatars with precise region localization, geometric adaptability, and photorealistic renderings. To tackle this challenge, we introduce a meticulously designed framework that decouples the editing process into local spatial adaptation and realistic appearance learning, utilizing a hybrid Tetrahedron-constrained Gaussian Splatting (TetGS) as the underlying representation. TetGS combines the controllable explicit structure of tetrahedral grids with the high-precision rendering capabilities of 3D Gaussian Splatting and is optimized in a progressive manner comprising three stages: 3D avatar instantiation from real-world monocular videos to provide accurate priors for TetGS initialization; localized spatial adaptation with explicitly partitioned tetrahedrons to guide the redistribution of Gaussian kernels; and geometry-based appearance generation with a coarse-to-fine activation strategy. Both qualitative and quantitative experiments demonstrate the effectiveness and superiority of our approach in generating photorealistic 3D …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Addressing the retrieval of unsafe content from vision-language models such as CLIP is an important step towards real-world integration. Current efforts have relied on unlearning techniques that try to erase the model’s knowledge of unsafe concepts. While effective in reducing unwanted outputs, unlearning limits the model's capacity to discern between safe and unsafe content. In this work, we introduce a novel approach that shifts from unlearning to an awareness paradigm by leveraging the inherent hierarchical properties of the hyperbolic space. We propose to encode safe and unsafe content as an entailment hierarchy, where both are placed in different regions of hyperbolic space. Our HySAC, Hyperbolic Safety-Aware CLIP, employs entailment loss functions to model the hierarchical and asymmetrical relations between safe and unsafe image-text pairs. This modelling – ineffective in standard vision-language models due to their reliance on Euclidean embeddings – endows the model with awareness of unsafe content, enabling it to serve as both a multimodal unsafe classifier and a flexible content retriever, with the option to dynamically redirect unsafe queries toward safer alternatives or retain the original output. Extensive experiments show that our approach not only enhances safety recognition, but also establishes a more adaptable and interpretable framework for …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Audio Descriptions (ADs) aim to provide a narration of a movie in text form, describing non-dialogue-related narratives, such as characters, actions, or scene establishment. Automatic generation of ADs remains challenging due to: i) the domain gap between movie-AD data and existing data used to train vision-language models, and ii) the issue of contextual redundancy arising from highly similar neighboring visual clips in a long movie. In this work, we propose **DistinctAD**, a novel two-stage framework for generating ADs that emphasize distinctiveness to produce better narratives. To address the domain gap, we introduce a CLIP-AD adaptation strategy that does not require additional AD corpora, enabling more effective alignment between movie and AD modalities at both global and fine-grained levels. In Stage-II, DistinctAD incorporates two key innovations: (i) a Contextual Expectation-Maximization Attention (EMA) module that reduces redundancy by extracting common bases from consecutive video clips, and (ii) an explicit distinctive word prediction loss that filters out repeated words in the context, ensuring the prediction of unique terms specific to the current AD. Comprehensive evaluations on MAD-Eval, CMD-AD, and TV-AD benchmarks demonstrate the superiority of DistinctAD, with the model consistently outperforming baselines, particularly in Recall@k/N, highlighting its effectiveness in producing high-quality, distinctive ADs.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Scaling by training on large datasets has been shown to enhance the quality and fidelity of image generation and manipulation with diffusion models; however, such large datasets are not always accessible in medical imaging due to cost and privacy issues, which contradicts one of the main applications of such models to produce synthetic samples where real data is scarce. Also, finetuning on pre-trained general models has been a challenge due to the distribution shift between the medical domain and the pre-trained models. Here, we propose Latent Drift (LD) for diffusion models that can be adopted for any fine-tuning method to mitigate the issues faced by the distribution shift or employed in inference time as a condition. Latent Drifting enables diffusion models to be conditioned for medical images fitted for the complex task of counterfactual image generation, which is crucial to investigate how parameters such as gender, age, and adding or removing diseases in a patient would alter the medical images. We evaluate our method on three public longitudinal benchmark datasets of brain MRI and chest X-rays for counterfactual image generation. Our results demonstrate significant performance gains in various scenarios when combined with different fine-tuning schemes. The source code of this …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Human pose plays a crucial role in the digital age. While recent works have achieved impressive progress in understanding and generating human poses, they often support only a single modality of control signals and operate in isolation, limiting their application in real-world scenarios. This paper presents UniPose, a framework employing Large Language Models (LLMs) to comprehend, generate, and edit human poses across various modalities, including images, text, and 3D SMPL poses. Specifically, we apply a pose tokenizer to convert 3D poses into discrete pose tokens, enabling seamless integration into the LLM within a unified vocabulary. To further enhance the fine-grained pose perception capabilities, we facilitate UniPose with a mixture of visual encoders, among them a pose-specific visual encoder. Benefiting from a unified learning strategy, UniPose effectively transfers knowledge across different pose-relevant tasks, adapts to unseen tasks, and exhibits extended capabilities. This work serves as the first attempt at building a general-purpose framework for pose comprehension, generation, and editing. Extensive experiments highlight UniPose's competitive and even superior performance across various pose-relevant tasks.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Accurate depth estimation from monocular videos remains challenging due to ambiguities inherent in single-view geometry, as crucial depth cues like stereopsis are absent. However, humans often perceive relative depth intuitively by observing variations in the size and spacing of objects as they move. Inspired by this, we propose a novel method that infers relative depth by examining the spatial relationships and temporal evolution of a set of tracked 2D trajectories. Specifically, we use off-the-shelf point tracking models to capture 2D trajectories. Then, our approach employs spatial and temporal transformers to process these trajectories and directly infer depth changes over time. Evaluated on the TAPVid-3D benchmark, our method demonstrates robust zero-shot performance, generalizing effectively from synthetic to real-world datasets. Results indicate that our approach achieves temporally smooth, high-accuracy depth predictions across diverse domains.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The latest emerged 4D Panoptic Scene Graph (4D-PSG) provides an advanced-ever representation for comprehensively modeling the dynamic 4D visual real world. Unfortunately, current pioneering 4D-PSG research can largely suffer from data scarcity issues severely, as well as the resulting out-of-vocabulary problems; also, the pipeline nature of the benchmark generation method can lead to suboptimal performance. To address these challenges, this paper investigates a novel framework for 4D-PSG generation that leverages rich 2D visual scene annotations to enhance 4D scene learning. First, we introduce a 4D Large Language Model (4D-LLM) integrated with a 3D mask decoder for end-to-end generation of 4D-PSG. A chained SG inference mechanism is further designed to exploit LLMs' open-vocabulary capabilities to infer accurate and comprehensive object and relation labels iteratively. Most importantly, we propose a 2D-to-4D visual scene transfer learning framework, where a spatial-temporal scene transcending strategy effectively transfers dimension-invariant features from abundant 2D SG annotations to 4D scenes, effectively compensating for data scarcity in 4D-PSG. Extensive experiments on the benchmark data demonstrate that we strikingly outperform baseline models by an average of 14.62%, highlighting the effectiveness of our method.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Composed Image Retrieval (CIR) aims to retrieve target images that closely resemble a reference image while integrating user-specified textual modifications, thereby capturing user intent more precisely. This dual-modality approach is especially valuable in internet search and e-commerce, facilitating tasks like scene image search with object manipulation and product recommendations with attribute changes. Existing training-free zero-shot CIR (ZS-CIR) methods often employ a two-stage process: they first generate a caption for the reference image and then use Large Language Models for reasoning to obtain a target description. However, these methods suffer from missing critical visual details and limited reasoning capabilities, leading to suboptimal retrieval performance. To address these challenges, we propose a novel, training-free one-stage method, One-Stage Reflective Chain-of-Thought Reasoning for ZS-CIR (OSrCIR), which employs Multimodal Large Language Models to retain essential visual information in a single-stage reasoning process, eliminating the information loss seen in two-stage methods. Our Reflective Chain-of-Thought framework further improves interpretative accuracy by aligning manipulation intent with contextual cues from reference images. OSrCIR achieves performance gains of 1.80% to 6.44% over existing training-free methods across multiple tasks, setting new state-of-the-art results in ZS-CIR and enhancing its utility in vision-language applications. Our code is available at https://anonymous.4open.science/r/osrcir24/.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
3D plane reconstruction from a single image is a crucial yet challenging topic in 3D computer vision. Previous state-of-the-art (SOTA) methods have focused on training their system on a single dataset from either indoor or outdoor domain, limiting their generalizability across diverse testing data. In this work, we introduce a novel framework dubbed ZeroPlane, a Transformer-based model targeting zero-shot 3D plane detection and reconstruction from a single image, over diverse domains and environments. To enable data-driving models on multiple domains, we have curated a large-scale (over 14 datasets and 560,000 images), high-resolution, densely-annotated planar benchmark from various indoor and outdoor scenes. To address the challenge of achieving desirable planar geometry on multi-dataset training, we propose to disentangle the representation of plane normal and offset, and employ an exemplar-guided, classification-then-regression paradigm to learn plane and offset respectively. Additionally, we employ advanced backbones as image encoder, and present an effective pixel-geometry-enhanced plane embedding module to further facilitate planar reconstruction. Extensive experiments across multiple zero-shot evaluation datasets have demonstrated that our approach significantly outperforms previous methods on both reconstruction accuracy and generalizability, especially over in-the-wild data. We will release all of the labeled data, code and models upon the acceptance of this paper.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce the task of text-to-diagram generation, which focuses on creating structured visual representations directly from textual descriptions. Existing approaches in text-to-image and text-to-code generation lack the logical organization and flexibility needed to produce accurate, editable diagrams, often resulting in outputs that are either unstructured or difficult to modify. To address this gap, we introduce DiagramGenBenchmark, a comprehensive evaluation framework encompassing eight distinct diagram categories, including flowcharts, model architecture diagrams, and mind maps. Additionally, we present DiagramAgent, an innovative framework with four core modules—Plan Agent, Code Agent, Check Agent, and Diagram-to-Code Agent—designed to facilitate both the generation and refinement of complex diagrams. Our extensive experiments, which combine objective metrics with human evaluations, demonstrate that DiagramAgent significantly outperforms existing baseline models in terms of accuracy, structural coherence, and modifiability. This work not only establishes a foundational benchmark for the text-to-diagram generation task but also introduces a powerful toolset to advance research and applications in this emerging area.
|
|
Highlight
|
Poster
[ ExHall D ] 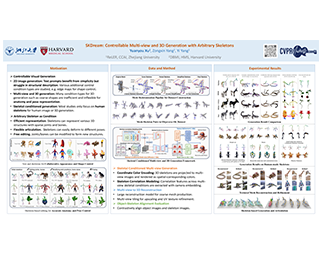
Abstract
Controllable generation has achieved substantial progress in both 2D and 3D domains, yet current conditional generation methods still face limitations in describing detailed shape structures. Skeletons can effectively represent and describe object anatomy and pose. Unfortunately, past studies are often limited to human skeletons. In this work, we generalize skeletal conditioned generation to arbitrary structures. First, we design a reliable mesh skeletonization pipeline to generate a large-scale mesh-skeleton paired dataset.Based on the dataset, a multi-view and 3D generation pipeline is built. We propose to represent 3D skeletons by Coordinate Color Encoding as 2D conditional images. A Skeletal Correlation Module is designed to extract global skeletal features for condition injection. After multi-view images are generated, 3D assets can be obtained by incorporating a large reconstruction model, followed with a UV texture refinement stage. As a result, our method achieves instant generation of multi-view and 3D contents which are aligned with given skeletons. The proposed techniques largely improve the object-skeleton alignment and generation quality.Project page at https://skdream3d.github.io/. Dataset, code and models will be released in public.
|
|
Highlight
|
Poster
[ ExHall D ] 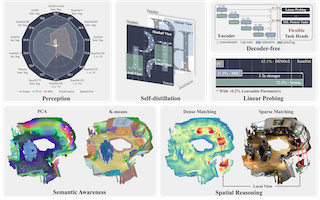
Abstract
In this paper, we question whether we have a reliable self-supervised point cloud model that can be used for diverse 3D tasks via simple linear probing, even with limited data and minimal computation. We find that existing 3D self-supervised learning approaches fall short when evaluated on representation quality through linear probing. We hypothesize that this is due to what we term the geometric shortcut, which causes representations to collapse to low-level spatial features. This challenge is unique to 3D and arises from the sparse nature of point cloud data. We address it through two key strategies: obscuring spatial information and enhancing the reliance on input features, ultimately composing a Sonata of 140k point clouds through self-distillation. Sonata is simple and intuitive, yet its learned representations are strong and reliable: zero-shot visualizations demonstrate semantic grouping, alongside strong spatial reasoning through nearest-neighbor relationships. Sonata demonstrates exceptional parameter and data efficiency, tripling linear probing accuracy (from 21.8% to 72.5%) on ScanNet and nearly doubling performance with only 1% of the data compared to previous approaches. Full fine-tuning further advances SOTA across both 3D indoor and outdoor perception tasks. All code and weights will be made available.
|
|
Highlight
|
Poster
[ ExHall D ] 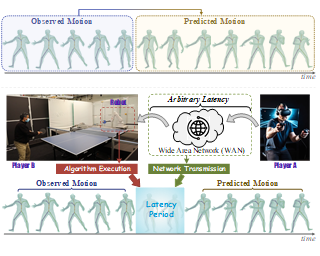
Abstract
We investigate a new task in human motion prediction, which aims to forecast future body poses from historically observed sequences while accounting for arbitrary latency. This differs from existing works that assume an ideal scenario where future motions can be ``instantaneously'' predicted, thereby neglecting time delays caused by network transmission and algorithm execution. Addressing this task requires tackling two key challenges: The length of latency period can vary significantly across samples; the prediction model must be efficient. In this paper, we propose ALIEN, which treats the motion as a continuous function parameterized by a neural network, enabling predictions under any latency condition. By incorporating Mamba-like linear attention as a hyper-network and designing subsequent low-rank modulation, ALIEN efficiently learns a set of implicit neural representation weights from the observed motion to encode instance-specific information. Additionally, our model integrates the primary motion prediction task with an extra-designed variable-delay pose reconstruction task in a unified multi-task learning framework, enhancing its ability to capture richer motion patterns. Extensive experiments demonstrate that our approach outperforms state-of-the-art baselines adapted for our new task, while maintaining competitive performance in traditional prediction setting.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Automated crop mapping through Satellite Image Time Series (SITS) has emerged as a crucial avenue for agricultural monitoring and management. However, due to the low resolution and unclear parcel boundaries, annotating pixel-level masks is exceptionally complex and time-consuming in SITS. This paper embraces the weakly supervised paradigm (i.e., only image-level categories available) to liberate the crop mapping task from the exhaustive annotation burden. The unique characteristics of SITS give rise to several challenges in weakly supervised learning: (1) noise perturbation from spatially neighboring regions, and (2) erroneous semantic bias from anomalous temporal periods. To address the above difficulties, we propose a novel method, termed exploring space-time perceptive clues (Exact). First, we introduce a set of spatial clues to explicitly capture the representative patterns of different crops from the most class-relative regions. Besides, we leverage the temporal-to-class interaction of the model to emphasize the contributions of pivotal clips, thereby enhancing the model perception for crop regions. Build upon the space-time perceptive clues, we derive the clue-based CAMs to effectively supervise the SITS segmentation network. Our method demonstrates impressive performance on various SITS benchmarks. Remarkably, the segmentation network trained on Exact-generated masks achieves 95% of its fully supervised performance, showing the bright …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The increasing adoption of large-scale models under 7 billion parameters in both language and vision domains enables inference tasks on a single consumer-grade GPU but makes fine-tuning models of this scale, especially 7B models, challenging. This limits the applicability of pruning methods that require full fine-tuning. Meanwhile, pruning methods that do not require fine-tuning perform well at low sparsity levels (10%-50%) but struggle at mid-to-high sparsity levels (50%-70%), where the error behaves equivalently to that of semi-structured pruning. To address these issues, this paper introduces ICP, which finds a balance between full fine-tuning and zero fine-tuning. First, Sparsity Rearrange is used to reorganize the predefined sparsity levels, followed by Block-wise Compensate Pruning, which alternates pruning and compensation on the model’s backbone, fully utilizing inference results while avoiding full model fine-tuning. Experiments show that ICP improves performance at mid-to-high sparsity levels compared to baselines, with only a slight increase in pruning time and no additional peak memory overhead.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Vision-language generative reward models (VL-GenRMs) play a crucial role in aligning and evaluating multimodal AI systems, yet their own evaluation remains under-explored. Current assessment methods primarily rely on AI-annotated preference labels from traditional VL tasks, which can introduce biases and often fail to effectively challenge state-of-the-art models.To address these limitations, we introduce VL-RewardBench, a comprehensive benchmark spanning general multimodal queries, visual hallucination detection, and complex reasoning tasks.Through our AI-assisted annotation pipeline combining sample selection with human verification, we curate 1,250 high-quality examples specifically designed to probe model limitations.Comprehensive evaluation across 16 leading large vision-language models, demonstrates VL-RewardBench's effectiveness as a challenging testbed, where even GPT-4o achieves only 65.4\% accuracy, and state-of-the-art open-source models such as Qwen2-VL-72B, struggle to surpass random-guessing. Importantly, performance on VL-RewardBench strongly correlates (Pearson's r $>$ 0.9) with MMMU-Pro accuracy using Best-of-N sampling with VL-GenRMs.Analysis experiments uncover three critical insights for improving VL-GenRMs: (i) models predominantly fail at basic visual perception tasks rather than reasoning tasks; (ii) inference-time scaling benefits vary dramatically by model capacity; and (iii) training VL-GenRMs to learn to judge substantially boosts judgment capability (+14.3\% accuracy for a 7B VL-GenRM).We believe VL-RewardBench along with the experimental insights will become a valuable resource for …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present **Material Anything**, a fully-automated, unified diffusion framework designed to generate physically-based materials for 3D objects. Unlike existing methods that rely on complex pipelines or case-specific optimizations, Material Anything offers a robust, end-to-end solution adaptable to objects under diverse lighting conditions. Our approach leverages a pre-trained image diffusion model, enhanced with a triple-head architecture and rendering loss to improve stability and material quality. Additionally, we introduce confidence masks as a dynamic switcher within the diffusion model, enabling it to effectively handle both textured and texture-less objects across varying lighting conditions. By employing a progressive material generation strategy guided by these confidence masks, along with a UV-space material refiner, our method ensures consistent, UV-ready material outputs. Extensive experiments demonstrate our approach outperforms existing methods across a wide range of object categories and lighting conditions.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent advances in 3D human-centric generation have made significant progress. However, existing methods still struggle with generating novel Human-Object Interactions (HOIs), particularly for open-set objects. We identify three main challenges of this task: precise human object relation reasoning, adaptive affordance parsing for unseen objects, and realistic human pose synthesis that aligns with the description and 3D object geometry. In this work, we propose a novel zero-shot 3D HOI generation framework, leveraging the knowledge from large-scale pretrained models without training from specific datasets. More specifically, we first generate an initial human pose by sampling multiple hypotheses through multi-view SDS based on the input text and object geometry. We then utilize a pre-trained 2D image diffusion model to parse unseen objects and extract contact points, avoiding the limitations imposed by existing 3D asset knowledge. Finally, we introduce a detailed optimization to generate fine-grained, precise and natural interaction, enforcing realistic 3D contact between the involved body parts, including hands in grasp, and 3D object. This is achieved by distilling relational feedback from LLMs to capture detailed human-object relations from the text inputs. Extensive experiments validate the effectiveness of our approach compared to prior work, particularly in terms of the fine-grained nature of interactions …
|
|
Highlight
|
Poster
[ ExHall D ] 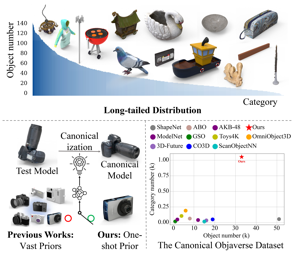
Abstract
3D object canonicalization is a fundamental task, essential for a variety of downstream tasks. Existing methods rely on either cumbersome manual processes or priors learned from extensive, per-category training samples. Real-world datasets, however, often exhibit long-tail distributions, challenging existing learning-based methods, especially in categories with limited samples. We address this by introducing the first one-shot category-level object canonicalization framework, requiring only a single canonical model as a reference (the "prior model") for each category. To canonicalize any object, our framework first extracts semantic cues with large language models (LLMs) and vision-language models (VLMs) to establish correspondences with the prior model. We introduce a novel loss function to enforce geometric and semantic consistency, aligning object orientations precisely despite significant shape variations. Moreover, we adopt a support-plane strategy to reduce search space for initial poses and utilize a semantic relationship map to select the canonical pose from multiple hypotheses. Extensive experiments on multiple datasets demonstrate that our framework achieves state-of-the-art performance and validate key design choices. Using our framework, we create the Canonical Objaverse Dataset (COD), canonicalizing 33K samples in the Objaverse-LVIS dataset, underscoring the effectiveness of our framework on handling large-scale datasets.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We propose 4Real-Video, a novel framework for generating 4D videos, organized as a grid of video frames with both time and viewpoint axes. In this grid, each row contains frames sharing the same timestep, while each column contains frames from the same viewpoint. One stream performs viewpoint updates on columns, and the other stream performs temporal updates on rows. After each diffusion transformer layer, a newly designed synchronization layer exchanges information between the two token streams. We propose two implementations of the synchronization layer, using either hard or soft synchronization.This feedforward architecture improves upon previous work in three ways: higher inference speed, enhanced visual quality (measured by FVD, CLIP, and VideoScore), and improved temporal and viewpoint consistency (measured by VideoScore, GIM-Confidence, and Dust3R-Confidence).
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Vision-based pose estimation of articulated robots with unknown joint angles has applications in collaborative robotics and human-robot interaction tasks. Current frameworks use neural network encoders to extract image features and downstream layers to predict joint angles and robot pose. While images of robots inherently contain rich information about the robot’s physical structures, existing methods often fail to leverage it fully; therefore, limiting performance under occlusions and truncations. To address this, we introduce RoboPEPP, a method that fuses information about the robot’s physical model into the encoder using a masking-based self-supervised embedding-predictive architecture. Specifically, we mask the robot’s joints and pre-train an encoder-predictor model to infer the joints’ embeddings from surrounding unmasked regions, enhancing the encoder’s understanding of the robot’s physical model. The pre-trained encoder-predictor pair, along with joint angle and keypoint prediction networks, is then fine-tuned for pose and joint angle estimation. Random masking of input during fine-tuning and keypoint filtering during evaluation further improves robustness. Our method, evaluated on several datasets, achieves the best results in robot pose and joint angle estimation while being the least sensitive to occlusions and requiring the lowest execution time.
|
|
Highlight
|
Poster
[ ExHall D ] 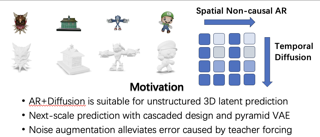
Abstract
Recent advances in auto-regressive transformers have revolutionized generative modeling across domains, from language processing to visual generation, demonstrating remarkable capabilities. However, applying these advances to 3D generation presents three key challenges: the unordered nature of 3D data conflicts with sequential prediction paradigms, conventional vector quantization approaches incur substantial compression loss when applied to 3D meshes, and the lack of efficient scaling strategies for higher resolution. To address these limitations, we introduce MAR-3D, which integrates a pyramid variational autoencoder with a cascaded masked auto-regressive transformer (Cascaded MAR) for progressive latent token denoising. Our architecture employs random masking during training and auto-regressive denoising in random order during inference, naturally accommodating the unordered property of 3D latent tokens. Additionally, we propose a cascaded training strategy with condition augmentation that enables efficient up-scaling the latent token resolution. Extensive experiments demonstrate that MAR-3D not only achieves superior performance and generalization capabilities compared to existing methods but also exhibits enhanced scaling properties over joint distribution modeling approaches like diffusion transformers in 3D generation.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Integrating large language models (LLMs) into autonomous driving has attracted significant attention with the hope of improving generalization and explainability. However, existing methods often focus on either driving or vision-language understanding but achieving both high driving performance and extensive language understanding remains challenging. In addition, the dominant approach to tackle vision-language understanding is using visual question answering. However, for autonomous driving, this is only useful if it is grounded in the action space. Otherwise, the model’s answers could be inconsistent with its behavior. Therefore, we propose a model that can handle three different tasks: (1) closed-loop driving, (2) vision-language understanding, and (3) language-action alignment. Our model SimLingo is based on a vision language model (VLM) and works using only camera, excluding expensive sensors like LiDAR. SimLingo obtains state-of-the-art performance on the widely used CARLA simulator on the Leaderboard 2.0 and the Bench2Drive benchmarks. Additionally, we achieve strong results in a wide variety of language-related tasks while maintaining high driving performance. We will release code, data and models upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
A key challenge for controllable image editing is the fact that visual attributes with semantic meanings are not always independent of each other, resulting in spurious correlations in model training. However,most existing methods ignore such issue, leading to biased causal representations learning and unintended changes to unrelated features in the edited images.This leads us to present a diffusion-based causal representation learning framework called CIDiffuser that employs structural causal models (SCMs) to capture causal representations of visual attributes to address the spurious correlation.The framework first adopts a semanticencoder to decompose the representation into the target part, which includes visual attributes of interest to the user, and the ``other" part.We then introduce a direct causal effect learning module to capture the total direct causal effect between the potential outcomes before and after intervening on the visual attributes.In addition, a diffusion-based learning strategy is designed to optimize the representation learning process.Empirical evaluations on two benchmark datasets and one in-house dataset suggest our approach significantly outperforms the state-of-the-art methods, enabling controllable image editing by modifying learned visual representations.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
As concerns regarding privacy in deep learning continue to grow, individuals are increasingly apprehensive about the potential exploitation of their personal knowledge in trained models. Despite several research efforts to address this, they often fail to consider the real-world demand from users for complete knowledge erasure. Furthermore, our investigation reveals that existing methods have a risk of leaking personal knowledge through embedding features. To address these issues, we introduce a novel concept of $\textbf{K}$nowledge $\textbf{D}$eletion ($\textbf{KD}$), an advanced task that considers both concerns, and provides an appropriate metric, named $\textbf{K}$nowledge $\textbf{R}$etention score ($\textbf{KR}$), for assessing knowledge retention in feature space. To achieve this, we propose a novel training-free erasing approach named $\textbf{E}$rasing $\textbf{S}$pace $\textbf{C}$oncept ($\textbf{ESC}$), which restricts the important subspace for the forgetting knowledge by eliminating the relevant activations in the feature. In addition, we suggest $\textbf{ESC}$ with $\textbf{T}$raining ($\textbf{ESC-T}$), which uses a learnable mask to better balance the trade-off between forgetting and preserving knowledge in KD. Our extensive experiments on various datasets and models demonstrate that our proposed methods achieve the fastest and state-of-the-art performance. Notably, our methods are applicable to diverse forgetting scenarios, such as facial domain setting, demonstrating the generalizability of our methods.
|
|
Highlight
|
ImagineFSL: Self-Supervised Pretraining Matters on Imagined Base Set for VLM-based Few-shot Learning
Poster
[ ExHall D ] 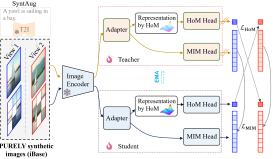
Abstract
Adapting CLIP models for few-shot recognition has recently attracted significant attention. Despite considerable progress, these adaptations remain hindered by the pervasive challenge of data scarcity. Text-to-image models, capable of generating abundant photorealistic labeled images, offer a promising solution. However, existing approaches treat synthetic images merely as complements to real images, rather than as standalone knowledge repositories stemming from distinct foundation models. To overcome this limitation, we reconceptualize synthetic images as an *imagined base set*, i.e., a unique, large-scale synthetic dataset encompassing diverse concepts. We introduce a novel CLIP adaptation methodology called *ImagineFSL*, involving pretraining on the imagined base set followed by fine-tuning on downstream few-shot tasks. We find that, compared to no pretraining, both supervised and self-supervised pretraining are beneficial, with the latter providing better performance. Building on this finding, we propose an improved self-supervised method tailored for few-shot scenarios, enhancing the transferability of representations from synthetic to real image domains. Additionally, we present an image generation pipeline that employs chain-of-thought and in-context learning techniques, harnessing foundation models to automatically generate diverse, realistic images. Our methods are validated across eleven datasets, consistently outperforming state-of-the-art methods by substantial margins.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Unsupervised panoptic segmentation aims to partition an image into semantically meaningful regions and distinct object instances without training on manually annotated data. In contrast to prior work on unsupervised panoptic scene understanding, we eliminate the need for object-centric training data, enabling the unsupervised understanding of complex scenes. To that end, we present the first unsupervised panoptic method that directly trains on scene-centric imagery. In particular, we propose an approach to obtain high-resolution panoptic pseudo labels on complex scene-centric data combining visual representations, depth, and motion cues. Utilizing both pseudo-label training and a panoptic self-training strategy yields a novel approach that accurately predicts panoptic segmentation of complex scenes without requiring any human annotations. Our approach significantly improves panoptic quality, e.g., surpassing the recent state of the art in unsupervised panoptic segmentation on Cityscapes by 9.4% points in PQ.
|
|
Highlight
|
Poster
[ ExHall D ] 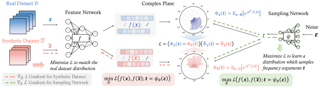
Abstract
Dataset distillation has emerged as a powerful approach for reducing data requirements in deep learning. Among various methods, distribution matching-based approaches stand out for their balance of computational efficiency and strong performance. However, existing distance metrics used in distribution matching often fail to accurately capture distributional differences, leading to unreliable measures of discrepancy. In this paper, we reformulate dataset distillation as a minmax optimization problem and introduce Neural Characteristic Function Discrepancy (NCFD), a comprehensive and theoretically grounded metric for measuring distributional differences. NCFD leverages the Characteristic Function (CF) to encapsulate full distributional information, employing a neural network to optimize the sampling strategy for the CF's frequency arguments, thereby maximizing the discrepancy to enhance distance estimation. Simultaneously, we minimize the difference between real and synthetic data under this optimized NCFD measure. Our approach, termed Neural Characteristic Function Matching (NCFM), inherently aligns the phase and amplitude of neural features in the complex plane for both real and synthetic data, achieving a balance between realism and diversity in synthetic samples. Experiments demonstrate that our method achieves significant performance gains over state-of-the-art methods on both low- and high-resolution datasets. Notably, we achieve a 20.5\% accuracy boost on ImageSquawk. Our method also reduces GPU memory …
|
|
Highlight
|
Poster
[ ExHall D ] 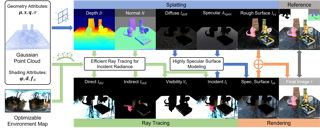
Abstract
3D Gaussian Splatting (3DGS), a recently emerged multi-view 3D reconstruction technique, has shown significant advantages in real-time rendering and explicit editing. However, 3DGS encounters challenges in the accurate modeling of both high-frequency view-dependent appearances and global illumination effects, including inter-reflection. This paper introduces SpecTRe-GS, which addresses these challenges and models highly Specular surfaces that reflect nearby objects through Tracing Rays in 3D Gaussian Splatting. SpecTRe-GS separately models reflections from highly specular and rough surfaces to leverage the distinctions between their reflective properties, integrating an efficient ray tracer within the 3DGS framework for querying secondary rays, thus achieving fast and accurate rendering. Also, it incorporates normal prior guidance and joint geometry optimization at various stages of the training process to enhance geometry reconstruction for undistorted reflections. The proposed SpecTRe-GS demonstrates superior performance compared to existing 3DGS-based methods in capturing highly specular inter-reflections, as confirmed by experiments conducted on both synthetic and real-world scenes. We also showcase the editing applications enabled by the scene decomposition capabilities of SpecTRe-GS.
|
|
Highlight
|
Poster
[ ExHall D ] 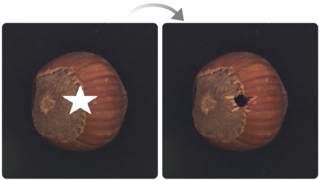
Abstract
Developing effective visual inspection models remains challenging due to the scarcity of defect data, especially in new or low-defect-rate manufacturing processes. While recent approaches have attempted to generate defect images using image generation models, producing highly realistic defects remains difficult. In this paper, we propose DefectFill, a novel method for realistic defect generation that requires only a few reference defect images. DefectFill leverages a fine-tuned inpainting diffusion model, optimized with our custom loss functions that incorporate defect, object, and cross-attention terms. This approach enables the inpainting diffusion model to precisely capture detailed, localized defect features and seamlessly blend them into defect-free objects. Additionally, we introduce the Low-Fidelity Selection method to further enhance the quality of the generated defect samples. Experiments demonstrate that DefectFill can generate high-quality defect images, and visual inspection models trained on these images achieve state-of-the-art performance on the MVTec AD dataset.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Our code, data, and pre-trained models will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Identity-preserving text-to-video (IPT2V) generation aims to create high-fidelity videos with consistent human identity. It is an important task in video generation but remains an open problem for generative models. This paper pushes the technical frontier of IPT2V in two directions that have not been resolved in the literature: (1) A tuning-free pipeline without tedious case-by-case finetuning, and (2) A frequency-aware heuristic identity-preserving Diffusion Transformer (DiT)-based control scheme. To achieve these goals, we propose **ConsisID**, a tuning-free DiT-based controllable IPT2V model to keep human-**id**entity **consis**tent in the generated video. Inspired by prior findings in frequency analysis of vision/diffusion transformers, it employs identity-control signals in the frequency domain, where facial features can be decomposed into low-frequency global features (e.g., profile, proportions) and high-frequency intrinsic features (e.g., identity markers that remain unaffected by pose changes). First, from a low-frequency perspective, we introduce a global facial extractor, which encodes the reference image and facial key points into a latent space, generating features enriched with low-frequency information. These features are then integrated into the shallow layers of the network to alleviate training challenges associated with DiT. Second, from a high-frequency perspective, we design a local facial extractor to capture high-frequency details and inject them into …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
While image-text foundation models have succeeded across diverse downstream tasks, they still face challenges in the presence of spurious correlations between the input and label. To address this issue, we propose a simple three-step approach--Project-Probe-Aggregate (PPA)--that enables parameter-efficient fine-tuning for foundation models without relying on group annotations. Building upon the failure-based debiasing scheme, our method, PPA, improves its two key components: minority samples identification and the robust training algorithm.Specifically, we first train biased classifiers by projecting image features onto the nullspace of class proxies from text encoders. Next, we infer group labels using the biased classifier and probe group targets with prior correction. Finally, we aggregate group weights of each class to produce the debiased classifier. Our theoretical analysis shows that our PPA enhances minority group identification and is Bayes optimal for minimizing the balanced group error, mitigating spurious correlations. Extensive experimental results confirm the effectiveness of our PPA: it outperforms the state-of-the-art by an average worst-group accuracy while requiring less than 0.01% tunable parameters without training group labels.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Human Motion Recovery (HMR) research mainly focuses on ground-based motions such as running. The study on capturing climbing motion, an off-ground motion, is sparse. This is partly due to the limited availability of climbing motion datasets, especially large-scale and challenging 3D labeled datasets. To address the insufficiency of climbing motion datasets, we collect AscendMotion, a large-scale well-annotated, and challenging climbing motion dataset. It consists of 412k RGB, LiDAR frames, and IMU measurements, which includes the challenging climbing motions of 22 professional climbing coaches across 12 different rocks. Capturing the climbing motions is challenging as it requires precise recovery of not only the complex pose but also the global position of climbers. Although multiple global HMR methods have been proposed, they cannot faithfully capture climbing motions. To address the limitations of HMR methods for climbing, we propose ClimbingCap, a motion recovery method that reconstructs continuous 3D human climbing motion in a global coordinate system. One key insight is to use the RGB and the LiDAR modalities to separately reconstruct motions in camera coordinates and global coordinates and optimize them jointly. We demonstrate the quality of the AscendMotion dataset and present promising results from ClimbingCap. The AscendMotion dataset and the source code …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Although large multimodal models (LMMs) have demonstrated remarkable capabilities in visual scene interpretation and reasoning, their capacity for complex and precise 3-dimensional spatial reasoning remains uncertain. Existing benchmarks focus predominantly on 2D spatial understanding and lack a framework to comprehensively evaluate 6D spatial reasoning across varying complexities.To address this limitation, we present **PulseCheck457**, a scalable and unbiased synthetic dataset designed with **4** key spatial components: multi-object recognition, 2D and 3D spatial relationships, and 3D orientation. **PulseCheck457** supports a cascading evaluation structure, offering **7** question types across **5** difficulty levels that progress from basic single-object recognition to our newly proposed complex 6D spatial reasoning tasks.We evaluated various large multimodal models (LMMs) on **PulseCheck457**, observing a general decline in performance as task complexity increases, particularly in 3D reasoning and 6D spatial tasks. To quantify these challenges, we introduce the Relative Performance Dropping Rate (RPDR), highlighting key weaknesses in 3D reasoning capabilities. Leveraging the unbiased attribute design of our dataset, we also uncover prediction biases across different attributes, with similar patterns observed in real-world image settings.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Attribute detection is crucial for many computer vision tasks, as it enables systems to describe properties such as color, texture, and material. Current approaches often rely on labor-intensive annotation processes which are inherently limited: objects can be described at an arbitrary level of detail (e.g., color vs. color shades), leading to ambiguities when the annotators are not instructed carefully. Furthermore, they operate within a predefined set of attributes, reducing scalability and adaptability to unforeseen downstream applications. We present Compositional Caching (ComCa), a training-free method for open-vocabulary attribute detection that overcomes these constraints. ComCa requires only the list of target attributes and objects as input, using them to populate an auxiliary cache of images by leveraging web-scale databases and Large Language Models to determine attribute-object compatibility. To account for the compositional nature of attributes, cache images receive soft attribute labels. Those are aggregated at inference time based on the similarity between the input and cache images, refining the predictions of underlying Vision-Language Models (VLMs). Importantly, our approach is model-agnostic, compatible with various VLMs. Experiments on public datasets demonstrate that ComCa significantly outperforms zero-shot and cache-based baselines, competing with recent training-based methods, proving that a carefully designed training-free approach can successfully address …
|
|
Highlight
|
Poster
[ ExHall D ] 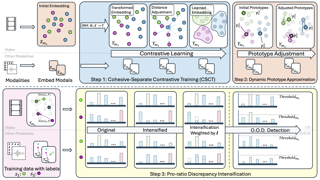
Abstract
Out-of-distribution (OOD) detection is crucial for ensuring the robustness of machine learning models by identifying samples that deviate from the training distribution. While traditional OOD detection has predominantly focused on single-modality inputs, such as images, recent advancements in multimodal models have shown the potential of utilizing multiple modalities (e.g., video, optical flow, audio) to improve detection performance. However, existing approaches often neglect intra-class variability within in-distribution (ID) data, assuming that samples of the same class are perfectly cohesive and consistent. This assumption can lead to performance degradation, especially when prediction discrepancies are indiscriminately amplified across all samples. To address this issue, we propose Dynamic Prototype Updating (DPU), a novel plug-and-play framework for multimodal OOD detection that accounts for intra-class variations. Our method dynamically updates class center representations for each class by measuring the variance of similar samples within each batch, enabling tailored adjustments. This approach allows us to intensify prediction discrepancies based on the updated class centers, thereby enhancing the model’s robustness and generalization across different modalities. Extensive experiments on two tasks, five datasets, and nine base OOD algorithms demonstrate that DPU significantly improves OOD detection performances, setting a new state-of-the-art in multimodal OOD detection, including improvements up to 80% …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Given a multi-view video, which viewpoint is most informative for a human observer? Existing methods rely on heuristics or expensive “best-view" supervision to answer this question, limiting their applicability. We propose a weakly supervised approach that leverages language accompanying an instructional multi-view video as a means to recover its most informative viewpoint(s). Our key hypothesis is that the more accurately an individual view can predict a view-agnostic text summary, the more informative it is. To put this into action, we propose a framework that uses the relative accuracy of view-dependent caption predictions as a proxy for best view pseudo-labels. Then, those pseudo-labels are used to train a view selector, together with an auxiliary camera pose predictor that enhances view-sensitivity. During inference, our model takes as input only a multi-view video—no language or camera poses—and returns the best viewpoint to watch at each timestep. On two challenging datasets comprised of diverse multi-camera setups and how-to activities, our model consistently outperforms state-of-the-art baselines, both with quantitative metrics and human evaluation.
|
|
Highlight
|
Poster
[ ExHall D ] 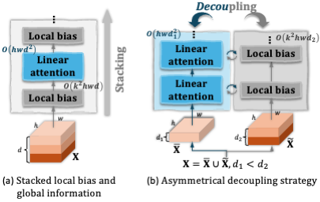
Abstract
Recently, large efforts have been made to design efficient linear-complexity visual Transformers. However, current linear attention models are generally unsuitable to be deployed in resource-constrained mobile devices, due to suffering from either few efficiency gains or significant accuracy drops. In this paper, we propose a new deCoupled duAl-interactive lineaR attEntion (CARE) mechanism, revealing that features' decoupling and interaction can fully unleash the power of linear attention. We first propose an asymmetrical feature decoupling strategy that asymmetrically decouples the learning process for local inductive bias and long-range dependencies, thereby preserving sufficient local and global information while effectively enhancing the efficiency of models. Then, a dynamic memory unit is employed to maintain critical information along the network pipeline. Moreover, we design a dual interaction module to effectively facilitate interaction between local inductive bias and long-range information as well as among features at different layers. By adopting a decoupled learning way and fully exploiting complementarity across features, our method can achieve both high efficiency and accuracy. Extensive experiments on ImageNet-1K, COCO, and ADE20K datasets demonstrate the effectiveness of our approach, e.g., achieving $78.4/82.1\%$ top-1 accuracy on ImagegNet-1K at the cost of only $0.7/1.9$ GMACs. Codes will be released on github.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Multimodal large language models (MLLMs) have garnered widespread attention from researchers due to their remarkable understanding and generation capabilities in visual language tasks (e.g., visual question answering). However, the rapid pace of knowledge updates in the real world makes offline training of MLLMs costly, and when faced with non-stationary data streams, MLLMs suffer from catastrophic forgetting during learning. In this paper, we propose an MLLMs-based dual momentum Mixture-of-Experts ($\texttt{CL-MoE}$) framework for continual visual question answering. We integrate MLLMs with continual learning to utilize the rich commonsense knowledge in LLMs.We introduce a Dual-Router MoE (RMoE) to select the global and local experts using task-level and instance-level routers, to robustly assign weights to the experts most appropriate for the task. Then, we design a dynamic Momentum MoE (MMoE) to update the parameters of experts dynamically based on the relationships between the experts and tasks, so that the model can absorb new knowledge while maintaining existing knowledge. The extensive experimental results indicate that our method achieves state-of-the-art performance on 10 VQA tasks, proving the effectiveness of our approach. The codes and weights will be released on GitHub.
|
|
Highlight
|
Poster
[ ExHall D ] 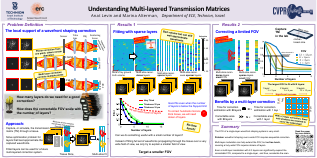
Abstract
Transmission matrices, mapping the propagation of light from one end of the tissue to the other, form an important mathematical tool in the analysis of tissue scattering and the design of wavefront shaping systems. To understand the relationship between their content and the volumetric structure of the tissue, we wish to fit them with multi-slice models, composed of a set of planar aberrations spaced throughout the volume. The number of layers used in such a model would largely affect the amount of information compression and the ease in which we can use such layered models in a wavefront-shaping system. This work offers a theoretical study of such multi-layered models. We attempt to understand how many layers are required for a good fit, and how does the approximation degrade when a smaller number of such layers is used. We show analytically that transmission matrices can be well fitted with very sparse layers. This leads to optimistic predictions on our ability to use them to design future wavefront shaping systems which can correct tissue aberration over a wide field-of-view.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Image generation today can produce somewhat realistic images from text prompts. However, if one asks the generator to synthesize a particular camera setting such as creating different fields of view using a 24mm lens versus a 70mm lens, the generator will not be able to interpret and generate scene-consistent images. This limitation not only hinders the adoption of generative tools in photography applications but also exemplifies a broader issue of bridging the gap between the data-driven models and the physical world. In this paper, we introduce the concept of Generative Photography, a framework designed to control camera intrinsic settings during content generation. The core innovation of this work are the concepts of Dimensionality Lifting and Contrastive Camera Learning, which achieve continuous and consistent transitions for different camera settings. Experimental results show that our method produces significantly more scene-consistent photorealistic images than state-of-the-art models such as Stable Diffusion 3 and FLUX.
|
|
Highlight
|
Poster
[ ExHall D ] 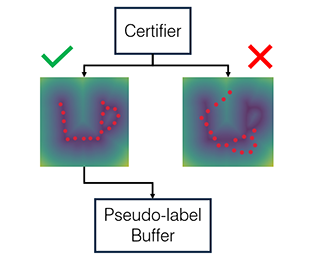
Abstract
We consider the problem of estimating object pose and shape from an RGB-D image. Our first contribution is to introduce CRISP, a category-agnostic object pose and shape estimation pipeline. The pipeline implements an encoder-decoder model for shape estimation. It uses FiLM-conditioning for implicit shape reconstruction and a DPT-based network for estimating pose-normalized points for pose estimation. As a second contribution, we propose an optimization-based pose and shape corrector that can correct estimation errors caused by a domain gap. Observing that the shape decoder is well behaved in the convex hull of known shapes, we approximate the shape decoder with an active shape model, and show that this reduces the shape correction problem to a constrained linear least squares problem, which can be solved efficiently by an interior point algorithm. Third, we introduce a self-training pipeline to perform self-supervised domain adaptation of CRISP. The self-training is based on a correct-and-certify approach, which leverages the corrector to generate pseudo-labels at test time, and uses them to self-train CRISP. We demonstrate CRISP (and the self-training) on YCBV, SPE3R, and NOCS datasets. CRISP shows high performance on all the datasets. Moreover, our self-training is capable of bridging a large domain gap. Finally, CRISP also …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce a novel approach to reconstruct simulation-ready garments with intricate appearance. Despite recent advancements, existing methods often struggle to balance the need for accurate garment reconstruction with the ability to generalize to new poses and body shapes or require large amounts of data to achieve this. In contrast, our method only requires a multi-view capture of a single static frame. We represent garments as hybrid mesh-embedded 3D Gaussian splats (or simply Gaussians), where the Gaussians capture near-field shading and high-frequency details, while the mesh encodes far-field albedo and optimized reflectance parameters. We achieve novel pose generalization by exploiting the mesh from our hybrid approach, enabling physics-based simulation and surface rendering techniques, while also capturing fine details with Gaussians that accurately reconstruct garment details. Our optimized garments can be used for simulating garments on novel poses, and garment relighting.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) have noticeably advanced photo-realistic novel view synthesis using images from densely spaced camera viewpoints. However, these methods struggle in few-shot scenarios due to limited supervision. In this paper, we present NexusGS, a 3DGS-based approach that enhances novel view synthesis from sparse-view images by directly embedding depth information into point clouds, without relying on complex manual regularizations. Exploiting the inherent epipolar geometry of 3DGS, our method introduces a novel point cloud densification strategy that initializes 3DGS with a dense point cloud, reducing randomness in point placement while preventing over-smoothing and overfitting. Specifically, NexusGS comprises three key steps: Epipolar Depth Nexus, Flow-Resilient Depth Blending, and Flow-Filtered Depth Pruning. These steps leverage optical flow and camera poses to compute accurate depth maps, while mitigating the inaccuracies often associated with optical flow. By incorporating epipolar depth priors, NexusGS ensures reliable dense point cloud coverage and supports stable 3DGS training under sparse-view conditions. Experiments demonstrate that NexusGS significantly enhances depth accuracy and rendering quality, surpassing state-of-the-art methods by a considerable margin. Furthermore, we validate the superiority of our generated point clouds by substantially boosting the performance of competing methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Composed Image Retrieval (CIR) is a multi-modal task that seeks to retrieve target images by harmonizing a reference image with a modified instruction. The main challenge in CIR lies in compositional conflicts between the reference image (e.g., blue, long sleeve) and the modified instruction (e.g., grey, short sleeve). Previous works attempt to mitigate such conflicts through feature-level manipulation, commonly employing learnable masks to obscure conflicting features within the reference image. However, the inherent complexity of feature spaces poses significant challenges in precise conflict neutralization, thereby leading to uncontrollable results. To this end, this paper proposes the Compositional Conflict Identification and Neutralization (CCIN) framework, which sequentially identifies and neutralizes compositional conflicts for effective CIR. Specifically, CCIN comprises two core modules: 1) Compositional Conflict Identification module, which utilizes LLM-based analysis to identify specific conflicting attributes, and 2) Compositional Conflict Neutralization module, which first generates a kept instruction to preserve non-conflicting attributes, then neutralizes conflicts under collaborative guidance of both the kept and modified instructions. Furthermore, an orthogonal parameter regularization loss is introduced to emphasize the distinction between target and conflicting features. Extensive experiments demonstrate the superiority of CCIN over the state-of-the-arts.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Continuous space-time video super-resolution (C-STVSR) endeavors to upscale videos simultaneously at arbitrary spatial and temporal scales, which has recently garnered increasing interest. However, prevailing methods struggle to yield satisfactory videos at out-of-distribution spatial and temporal scales. On the other hand, event streams characterized by high temporal resolution and high dynamic range, exhibit compelling promise in vision tasks. This paper presents EvEnhancer, an innovative approach that marries the unique advantages of event streams to elevate effectiveness, efficiency, and generalizability for C-STVSR. Our approach hinges on two pivotal components: 1) Event-adapted synthesis capitalizes on the spatiotemporal correlations between frames and events to discern and learn long-term motion trajectories, enabling the adaptive interpolation and fusion of informative spatiotemporal features; 2) Local implicit video transformer integrates local implicit video neural function with cross-scale spatiotemporal attention to learn continuous video representations utilized to generate plausible videos at arbitrary resolutions and frame rates. Experiments show that EvEnhancer achieves superiority on synthetic and real-world datasets and preferable generalizability on out-of-distribution scales against state-of-the-art methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Diffusion models have enabled the generation of high-quality images with a strong focus on realism and textual fidelity. Yet, large-scale text-to-image models, such as Stable Diffusion, struggle to generate images where foreground objects are placed over a chroma key background, limiting their ability to separate foreground and background elements without fine-tuning. To address this limitation, we present a novel Training-Free Chroma Key Content Generation Diffusion Model (TKG-DM), which optimizes the initial random noise to produce images with foreground objects on a specifiable color background. Our proposed method is the first to explore the manipulation of the color aspects in initial noise for controlled background generation, enabling precise separation of foreground and background without fine-tuning. Extensive experiments demonstrate that our training-free method outperforms existing methods in both qualitative and quantitative evaluations, matching or surpassing fine-tuned models. Finally, we successfully extend it to other tasks (e.g., consistency models and text-to-video), highlighting its transformative potential across various generative applications where independent control of foreground and background is crucial.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We introduce 4D Motion Scaffolds (MoSca), a modern 4D reconstruction system designed to reconstruct and synthesize novel views of dynamic scenes from monocular videos captured casually in the wild. To address such a challenging and ill-posed inverse problem, we leverage prior knowledge from foundational vision models and lift the video data to a novel Motion Scaffold (MoSca) representation, which compactly and smoothly encodes the underlying motions/deformations. The scene geometry and appearance are then disentangled from the deformation field and are encodedby globally fusing the Gaussians anchored onto the MoSca and optimized via Gaussian Splatting. Additionally, camera focal length and poses can be solved using bundle adjustment without the need of any other pose estimation tools.Experiments demonstrate state-of-the-art performance on dynamic rendering benchmarks and its effectiveness on real videos.
|
|
Highlight
|
Poster
[ ExHall D ] 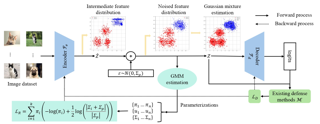
Abstract
By locally encoding raw data into intermediate features, collaborative inference enables end users to leverage powerful deep learning models without exposure of sensitive raw data to cloud servers.However, recent studies have revealed that these intermediate features may not sufficiently preserve privacy, as information can be leaked and raw data can be reconstructed via model inversion attacks (MIAs).Obfuscation-based methods, such as noise corruption, adversarial representation learning, and information filters, enhance the inversion robustness by obfuscating the task-irrelevant redundancy empirically.However, methods for quantifying such redundancy remain elusive, and the explicit mathematical relation between this redundancy and worst-case robustness against inversion has not yet been established.To address that, this work first theoretically proves that the conditional entropy of inputs given intermediate features provides a guaranteed lower bound on the reconstruction mean square error (MSE) under any MIA.Then, we derive a differentiable and solvable measure for bounding this conditional entropy based on the Gaussian mixture estimation and propose a conditional entropy maximization (CEM) algorithm to enhance the inversion robustness. Experimental results on four datasets demonstrate the effectiveness and adaptability of our proposed CEM; without compromising the feature utility and computing efficiency, integrating the proposed CEM into obfuscation-based defense mechanisms consistently boosts their inversion robustness, …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Generating dense multiview images from text prompts is crucial for creating high-fidelity 3D assets. Nevertheless, existing methods struggle with space-view correspondences, resulting in sparse and low-quality outputs. In this paper, we introduce CoSER, a novel consistent dense Multiview Text-to-Image Generator for Text-to-3D, achieving both efficiency and quality by meticulously learning neighbor-view coherence and further alleviating ambiguity through the swift traversal of all views. For achieving neighbor-view consistency, each viewpoint densely interacts with adjacent viewpoints to perceive the global spatial structure, and aggregates information along motion paths explicitly defined by physical principles to refine details. To further enhance cross-view consistency and alleviate content drift, CoSER rapidly scan all views in spiral bidirectional manner to aware holistic information and then scores each point based on semantic material. Subsequently, we conduct weighted down-sampling along the spatial dimension based on scores, thereby facilitating prominent information fusion across all views with lightweight computation. Technically, the core module is built by integrating the attention mechanism with a selective state space model, exploiting the robust learning capabilities of the former and the low overhead of the latter. Extensive evaluation shows that CoSER is capable of producing dense, high-fidelity, content-consistent multiview images that can be flexibly integrated into …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper presents our latest advancements, *Goku*, a new family of joint image-and-video generation models based on rectified flow Transformers to achieve industry-grade performance. We present the foundational elements required for high-quality visual generation, including data curation, model design, flow formulation, etc. Key contributions inclued a meticulous data filtering pipeline that ensures high-quality, fine-grained image and video data curation; and the pioneering use of rectified flow for enhanced interaction among video and image tokens. Goku models achieve superior performance in both qualitative and quantitative assessments. Notably, \ours achieves top scores on major benchmarks: 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, alongside 82.7 on VBench for text-to-video tasks. We hope this report offers valuable insights into joint image-and-video generation models for the research community.
|
|
Highlight
|
Poster
[ ExHall D ] 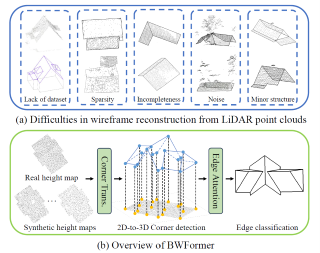
Abstract
In this paper, we present BWFormer, a novel Transformer-based model for building wireframe reconstruction from airborne LiDAR point cloud. The problem is solved in a ground-up manner by detecting the building corners in 2D, lifting and connecting them in 3D space afterwards with additional data augmentation.Due to the 2.5D characteristic of the airborne LiDAR point cloud, we simplify the problem by projecting the points on the ground plane to produce a 2D height map. With the height map, a heat map is first predicted with pixel-wise corner likelihood to predict the possible 2D corners.Then, 3D corners are predicted by a Transformer-based network with extra height embedding initialization.This 2D-to-3D corner detection strategy reduces the search space significantly.To recover the topological connections among the corners, edges are finally predicted from geometrical and visual cues in the height map with the proposed edge attention mechanism, which extracts holistic features and preserves local details simultaneously.In addition, due to the limited datasets in the field and the irregularity of the point clouds, a conditional latent diffusion model for LiDAR scanning simulation is utilized for data augmentation.BWFormer surpasses other state-of-the-art methods, especially in reconstruction completeness. We commit to release all our codes and pre-trained models.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Zero-Shot Anomaly Detection (ZSAD) is an emerging AD paradigm. Unlike the traditional unsupervised AD setting that requires a large number of normal samples to train a model, ZSAD is more practical for handling data-restricted real-world scenarios. Recently, Multimodal Large Language Models (MLLMs) have shown revolutionary reasoning capabilities in various vision tasks. However, the reasoning of image abnormalities remains underexplored due to the lack of corresponding datasets and benchmarks. To facilitate research in anomaly detection and reasoning, we establish the first visual instruction tuning dataset, Anomaly-Instruct-125k, and the evaluation benchmark, VisA-D&R. Through investigation with our benchmark, we reveal that current MLLMs like GPT-4o cannot accurately detect and describe fine-grained anomalous details in images. To address this, we propose Anomaly-OneVision (Anomaly-OV), the first specialist visual assistant for ZSAD and reasoning, based on LLaVA-OneVision. Inspired by human behavior in visual inspection, Anomaly-OV leverages a Look-Twice Feature Matching (LTFM) mechanism to adaptively select and emphasize abnormal visual tokens for its LLM. Extensive experiments demonstrate that Anomaly-OV achieves significant improvements over advanced generalist models in both detection and reasoning. Furthermore, extensions to medical and 3D anomaly reasoning are provided for future study.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Depth Anything has achieved remarkable success in monocular depth estimation with strong generalization ability. However, it suffers from temporal inconsistency in videos, hindering its practical applications. Various methods have been proposed to alleviate this issue by leveraging video generation models or introducing priors from optical flow and camera poses. Nonetheless, these methods are only applicable to short videos (10 seconds) and require a trade-off between quality and computational efficiency. We propose Video Depth Anything for high-quality, consistent depth estimation in super-long videos (over several minutes) without sacrificing efficiency. We base our model on Depth Anything V2 and replace its head with an efficient spatial-temporal head. We design a straightforward yet effective temporal consistency loss by constraining the temporal depth gradient, eliminating the need for additional geometric priors. The model is trained on a joint dataset of video depth and unlabeled images, similar to Depth Anything V2. Moreover, a novel key-frame-based strategy is developed for long video inference. Experiments show that our model can be applied to arbitrarily long videos without compromising quality, consistency, or generalization ability. Comprehensive evaluations on multiple video benchmarks demonstrate that our approach sets a new state-of-the-art in zero-shot video depth estimation. We offer models of different …
|
|
Highlight
|
Poster
[ ExHall D ] 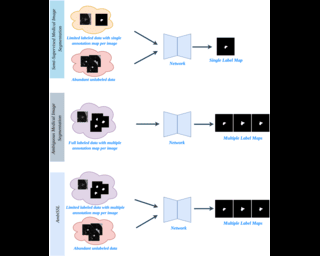
Abstract
Despite the remarkable progress of deep learning-based methods in medical image segmentation, their use in clinical practice remains limited for two main reasons. First, obtaining a large medical dataset with precise annotations to train segmentation models is challenging. Secondly, most current segmentation techniques generate a single deterministic segmentation mask for each image. However, in real-world scenarios, there is often significant uncertainty regarding what defines the ``correct" segmentation, and various expert annotators might provide different segmentations for the same image. To tackle both of these problems, we propose Annotation Ambiguity Aware Semi-Supervised Medical Image Segmentation (AmbiSSL). AmbiSSL combines a small amount of multi-annotator labeled data and a large set of unlabeled data to generate diverse and plausible segmentation maps. Our method consists of three key components: (1) The Diverse Pseudo-Label Generation (DPG) module utilizes multiple decoders, created by performing randomized pruning on the original backbone decoder. These pruned decoders enable the generation of a diverse pseudo-label set; (2) a Semi-Supervised Latent Distribution Learning (SSLDL) module constructs acommon latent space by utilizing both ground truth annotations andpseudo-label set; and (3) a Cross-Decoder Supervision (CDS) module, which enables pruned decoders to guide each other’s learning. We evaluated the proposed method on two publicly …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
3D fluorescence microscopy is essential for understanding fundamental life processes through long-term live-cell imaging. However, due to inherent issues in imaging principles, it faces significant challenges including spatially varying noise and anisotropic resolution, where the axial resolution lags behind the lateral resolution up to 4.5 times. Meanwhile, laser power is kept low to maintain cell viability, leading to inaccessible low-noise and high-resolution paired ground truth (GT). To tackle these limitations, a dual Cycle-consistent Diffusion is proposed to effectively mine intra-volume imaging priors within 3D cell volumes in an unsupervised manner, $i.e.$, Volume Tells (VTCD), achieving de-noising and super-resolution (SR) simultaneously. Specifically, a spatially iso-distributed denoiser is designed to exploit the noise distribution consistency between adjacent low-noise and high-noise regions within the 3D cell volume, suppressing the spatially varying noise.Then, in light of the structural consistency of the cell volume, a cross-plane global-propagation SR module propagates high-resolution details from the XY plane into adjacent regions in the XZ and YZ planes, progressively enhancing resolution across the entire 3D cell volume.Experimental results on 10 $in$ $vivo$ cellular dataset demonstrate high improvements in both denoising and super-resolution, with axial resolution enhanced from ~ 430 nm to ~ 90 nm.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Understanding bimanual human hand activities is a critical problem in AI and robotics. We cannot build large models of bimanual activities because existing datasets lack the scale, coverage of diverse hand activities, and detailed annotations. We introduce GigaHands, a massive annotated dataset capturing 34 hours of bimanual hand activities from 56 subjects and 417 objects, totaling 14k motion clips derived from 183 million frames paired with 84k text annotations. Our markerless capture setup and data acquisition protocol enable fully automatic 3D hand and object estimation while minimizing the effort required for text annotation. The scale and diversity of GigaHands enable broad applications, including text-driven action synthesis, hand motion captioning, and dynamic radiance field reconstruction.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Real-time free-view human rendering from sparse-view RGB inputs is a challenging task due to sensor scarcity and the tight time budget. To ensure efficiency, recent methods leverage 2D CNNs operating in texture space to learn rendering primitives. However, they either jointly learn geometry and appearance, or they ignore relevant sparse image information for geometry estimation, significantly harming visual quality and robustness to unseen body poses. To address this issue, we present Double Unprojected Textures, which at the core disentangles coarse geometric deformation estimation from appearance synthesis, enabling robust and photorealistic 4K rendering in real-time. Specifically, we first introduce a novel image-conditioned template deformation network, which estimates the coarse deformation of the human template from a first unprojected texture. This updated geometry is then used to apply a second and more accurate texture unprojection. The resulting texture map has fewer artifacts and better alignment with input views, which benefits our learning of finer-level geometry and appearance represented by Gaussian splats. We validate the effectiveness and efficiency of the proposed method in quantitative and qualitative experiments, which significantly surpasses other state-of-the-art methods.
|
|
Highlight
|
Poster
[ ExHall D ] 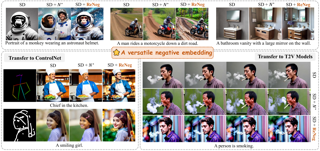
Abstract
In text-to-image (T2I) generation applications, negative embeddings have proven to be a simple yet effective approach for enhancing generation quality. Typically, these negative embeddings are derived from user-defined negative prompts, which, while being functional, are not necessarily optimal.In this paper, we introduce ReNeg, an end-to-end method designed to learn improved Negative embeddings guided by a Reward model. We employ a reward feedback learning framework and integrate classifier-free guidance (CFG) into the training process, which was previously utilized only during inference, thus enabling the effective learning of negative embeddings.We also propose two strategies for learning both global and per-sample negative embeddings. Extensive experiments show that the learned negative embedding significantly outperforms null-text and handcrafted counterparts, achieving substantial improvements in human preference alignment. Additionally, the negative embedding learned within the same text embedding space exhibits strong generalization capabilities.For example, using the same CLIP text encoder, the negative embedding learned on SD1.5 can be seamlessly transferred to text-to-image or even text-to-video models such as ControlNet, ZeroScope, and VideCrafter2, resulting in consistent performance improvements across the board. Code and learned negative embeddings will be released.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In real-world environments, a LiDAR point cloud registration method with robust generalization capabilities (across varying distances and datasets) is crucial for ensuring safety in autonomous driving and other LiDAR-based applications. However, current methods fall short in achieving this level of generalization. To address these limitations, we propose UGP, a pruned framework designed to enhance generalization power for LiDAR point cloud registration. The core insight in UGP is the elimination of cross-attention mechanisms to improve generalization, allowing the network to concentrate on intra-frame feature extraction. Additionally, we introduce a progressive self-attention module to reduce ambiguity in large-scale scenes and integrate Bird’s Eye View (BEV) features to incorporate semantic information about scene elements. Together, these enhancements significantly boost the network’s generalization performance. We validated our approach through various generalization experiments in multiple outdoor scenes. In cross-distance generalization experiments on KITTI and nuScenes, UGP achieved state-of-the-art mean Registration Recall rates of 94.5\% and 91.4\%, respectively. In cross-dataset generalization from nuScenes to KITTI, UGP achieved a state-of-the-art mean Registration Recall of 90.9\%.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Despite the advent in 3D hand pose estimation, current methods predominantly focus on single-image 3D hand reconstruction in the camera frame, overlooking the world-space motion of the hands. Such limitation prohibits their direct use in egocentric video settings, where hands and camera are continuously in motion. In this work, we propose HaWoR, a high-fidelity method for hand motion reconstruction in world coordinates from egocentric videos. We propose to decouple the task by reconstructing the hand motion in the camera space and estimating the camera trajectory in the world coordinate system. To achieve precise camera trajectory estimation, we propose an adaptive egocentric SLAM framework that addresses the shortcomings of traditional SLAM methods, providing robust performance under challenging camera dynamics. To ensure robust hand motion trajectories, even when the hands move out of view frustum, we devise a novel motion infiller network that effectively completes the missing frames of the sequence. Through extensive quantitative and qualitative evaluations, we demonstrate that HaWoR achieves state-of-the-art performance on both hand motion reconstruction and world-frame camera trajectory estimation under different egocentric benchmark datasets. Code and models will be made publicly available for research purposes.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Autonomous driving visual question answering (AD-VQA) aims to answer questions related to perception, prediction, and planning based on given driving scene images, heavily relying on the model's spatial perception capabilities.Previous works typically express spatial comprehension through textual representations of spatial coordinates, resulting in semantic gaps between visual coordinate representations and textual descriptions.This oversight hinders the accurate transmission of spatial information and increases the expressive burden.To address this, we propose Marker-based Prompt Learning framework (MPDrive), which transforms spatial coordinates into concise visual markers, ensuring linguistic consistency and enhancing the accuracy of visual perception and spatial expression in AD-VQA.Specifically, MPDrive converts complex spatial coordinates into text-based visual marker predictions, simplifying the expression of spatial information for autonomous decision-making.Moreover, we introduce visual marker images as conditional inputs and integrate object-level fine-grained features to further enhance multi-level spatial perception abilities.Extensive experiments on the DriveLM and CODA-LM datasets show that MPDrive performs at state-of-the-art levels, particularly in cases requiring sophisticated spatial understanding.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We present a novel, hardware rasterized rendering approach for ray-based 3D Gaussian Splatting (RayGS), obtaining both fast and high-quality results for novel view synthesis. Our work contains a mathematically rigorous and geometrically intuitive derivation about how to efficiently estimate all relevant quantities for rendering RayGS models, structured with respect to standard hardware rasterization shaders. Our solution is the first enabling rendering RayGS models at sufficiently high frame rates to support quality-sensitive applications like Virtual and Mixed Reality. Our second contribution enables alias-free rendering for RayGS, by addressing mip-related issues arising when rendering diverging scales during training and testing. We demonstrate significant performance gains, across different benchmark scenes, while retaining state-of-the-art appearance quality of RayGS.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Erase inpainting, or object removal, aims to precisely remove target objects within masked regions while preserving the overall consistency of the surrounding content. Despite diffusion-based methods have made significant strides in the field of image inpainting, challenges remain regarding the emergence of unexpected objects or artifacts. We assert that the inexact diffusion pathways established by existing standard optimization paradigms constrain the efficacy of object removal. To tackle these challenges, we propose a novel Erase Diffusion, termed EraDiff, aimed at unleashing the potential power of standard diffusion in the context of object removal. In contrast to standard diffusion, the EraDiff adapts both the optimization paradigm and the network to improve the coherence and elimination of the erasure results.We first introduce a Chain-Rectifying Optimization (CRO) paradigm, a sophisticated diffusion process specifically designed to align with the objectives of erasure. This paradigm establishes innovative diffusion transition pathways that simulate the gradual elimination of objects during optimization, allowing the model to accurately capture the intent of object removal. Furthermore, to mitigate deviations caused by artifacts during the sampling pathways, we develop a simple yet effective Self-Rectifying Attention (SRA) mechanism. The SRA calibrates the sampling pathways by altering self-attention activation, allowing the model to effectively …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper presents MetricGrids, a novel grid-based neural representation that combines elementary metric grids in various metric spaces to approximate complex nonlinear signals. While grid-based representations are widely adopted for their efficiency and scalability, the existing feature grids with linear indexing for continuous-space points can only provide degenerate linear latent space representations, and such representations cannot be adequately compensated to represent complex nonlinear signals by the following compact decoder. To address this problem while keeping the simplicity of a regular grid structure, our approach builds upon the standard grid-based paradigm by constructing multiple elementary metric grids as high-order terms to approximate complex nonlinearities, following the Taylor expansion principle. Furthermore, we enhance model compactness with hash encoding based on different sparsities of the grids to prevent detrimental hash collisions, and a high-order extrapolation decoder to reduce explicit grid storage requirements. experimental results on both 2D and 3D reconstructions demonstrate the superior fitting and rendering accuracy of the proposed method across diverse signal types, validating its robustness and generalizability.
|
|
Highlight
|
Poster
[ ExHall D ] 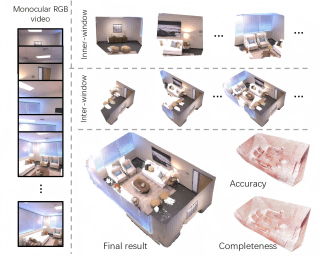
Abstract
In this paper, we introduce SLAM3R, a novel and effective monocular RGB SLAM system for real-time and high-quality dense 3D reconstruction. SLAM3R provides an end-to-end solution by seamlessly integrating local 3D reconstruction and global coordinate registration through feed-forward neural networks. Given a video input, the system first converts it into overlapping clips using a sliding window mechanism. Unlike traditional pose optimization-based methods, SLAM3R directly regresses 3D pointmaps from RGB images and then progressively aligns and deforms these local pointmaps to create a globally consistent scene reconstruction - all without explicitly solving any camera parameters. Experiments across datasets consistently show that SLAM3R achieves state-of-the-art reconstruction accuracy and completeness while maintaining real-time performance at 20+ FPS. Upon acceptance, we will release our code to support further research.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent advances in radiance field reconstruction, such as 3D Gaussian Splatting (3DGS), have achieved high-quality novel view synthesis and fast rendering by representing scenes with compositions of Gaussian primitives. However, 3D Gaussians present several limitations for scene reconstruction. Accurately capturing hard edges is challenging without significantly increasing the number of Gaussians, creating a large memory footprint. Moreover, they struggle to represent flat surfaces, as they are diffused in space. Without hand-crafted regularizers, they tend to disperse irregularly around the actual surface. To circumvent these issues, we introduce a novel method, named 3D Convex Splatting (3DCS), which leverages 3D smooth convexes as primitives for modeling geometrically-meaningful radiance fields from multi-view images. Smooth convex shapes offer greater flexibility than Gaussians, allowing for a better representation of 3D scenes with hard edges and dense volumes using fewer primitives. Powered by our efficient CUDA-based rasterizer, 3DCS achieves superior performance over 3DGS on benchmarks such as Mip-NeRF360, Tanks and Temples, and Deep Blending. Specifically, our method attains an improvement of up to 0.81 in PSNR and 0.026 in LPIPS compared to 3DGS while maintaining high rendering speeds and reducing the number of required primitives. Our results highlight the potential of 3D Convex Splatting to become …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent advancements in visual generation technologies have markedly increased the scale and availability of video datasets, which are crucial for training effective video generation models. However, a significant lack of high-quality, human-centric video datasets presents a challenge to progress in this field. To bridge this gap, we introduce \textbf{OpenHumanVid}, a large-scale and high-quality human-centric video dataset characterized by precise and detailed captions that encompass both human appearance and motion states, along with supplementary human motion conditions, including skeleton sequences and speech audio.To validate the efficacy of this dataset and the associated training strategies, we propose an extension of existing classical diffusion transformer architectures and conduct further pretraining of our models on the proposed dataset. Our findings yield two critical insights: First, the incorporation of a large-scale, high-quality dataset substantially enhances evaluation metrics for generated human videos while preserving performance in general video generation tasks. Second, the effective alignment of text with human appearance, human motion, and facial motion is essential for producing high-quality video outputs.Based on these insights and corresponding methodologies, the straightforward extended network trained on the proposed dataset demonstrates an obvious improvement in the generation of human-centric videos.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Large Language Models (LLMs) demonstrate enhanced capabilities and reliability by reasoning more, evolving from Chain-of-Thought prompting to product-level solutions like OpenAI o1. Despite various efforts to improve LLM reasoning, high-quality long-chain reasoning data and optimized training pipelines still remain inadequately explored in vision-language tasks. In this paper, we present Insight-V, an early effort to 1) scalably produce long and robust reasoning data for complex multi-modal tasks, and 2) an effective training pipeline to enhance the reasoning capabilities of multi-modal large language models (MLLMs). Specifically, to create long and structured reasoning data without human labor, we design a two-step pipeline with a progressive strategy to generate sufficiently long and diverse reasoning paths and a multi-granularity assessment method to ensure data quality. We observe that directly supervising MLLMs with such long and complex reasoning data will not yield ideal reasoning ability. To tackle this problem, we design a multi-agent system consisting of a reasoning agent dedicated to performing long-chain reasoning and a summary agent trained to judge and summarize reasoning results. We further incorporate an iterative DPO algorithm to enhance the reasoning agent's generation stability and quality. Based on the popular LLaVA-NeXT model, our method shows an average improvement of 7.5% across …
|
|
Highlight
|
Poster
[ ExHall D ] 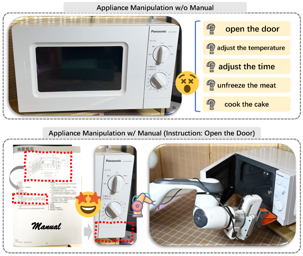
Abstract
Correct use of electrical appliances has significantly improved human life quality. Unlike simple tools that can be manipulated with common sense, different parts of electrical appliances have specific functions defined by manufacturers. If we want the robot to heat bread by microwave, we should enable them to review the microwave’s manual first. From the manual, it can learn about component functions, interaction methods, and representative task steps about appliances. However, previous manual-related works remain limited to question-answering tasks while existing manipulation researchers ignore the manual's important role and fail to comprehend multi-page manuals. In this paper, we propose the first manual-based appliance manipulation benchmark CheckManual. Specifically, we design a large model-assisted human-revised data generation pipeline to create manuals based on CAD appliance models. With these manuals, we establish novel manual-based manipulation challenges, metrics, and simulator environments for model performance evaluation. Furthermore, we propose the first manual-based manipulation planning model ManualPlan to set up a group of baselines for the CheckManual benchmark.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recently, sparsely-supervised 3D object detection has gained great attention, achieving performance close to fully-supervised 3D objectors while requiring only a few annotated instances. Nevertheless, these methods suffer challenges when accurate labels are extremely absent. In this paper, we propose a boosting strategy, termed SP3D, explicitly utilizing the cross-modal semantic prompts generated from Large Multimodal Models (LMMs) to boost the 3D detector with robust feature discrimination capability under sparse annotation settings. Specifically, we first develop a Confident Points Semantic Transfer (CPST) module that generates accurate cross-modal semantic prompts through boundary-constrained center cluster selection. Based on these accurate semantic prompts, which we treat as seed points, we introduce a Dynamic Cluster Pseudo-label Generation (DCPG) module to yield pseudo-supervision signals from the geometry shape of multi-scale neighbor points. Additionally, we design a Distribution Shape score (DS score) that chooses high-quality supervision signals for the initial training of the 3D detector. Experiments on the KITTI dataset and Waymo Open Dataset (WOD) have validated that SP3D can enhance the performance of sparsely supervised detectors by a large margin under meager labeling conditions.Moreover, we verified SP3D in the zero-shot setting, where its performance exceeded that of the state-of-the-art methods. The code will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Diffusion-based human animation aims to animate a human character based on a source human image as well as driving signals such as a sequence of poses. Leveraging the generative capacity of diffusion model, existing approaches are able to generate high-fidelity poses, but struggle with significant viewpoint changes, especially in zoom-in/zoom-out scenarios where camera-character distance varies. This limits the applications such as cinematic shot type plan or camera control. We propose a pose-correlated reference selection diffusion network, supporting substantial viewpoint variations in human animation. Our key idea is to enable the network to utilize multiple reference images as input, since significant viewpoint changes often lead to missing appearance details on the human body. To eliminate the computational cost, we first introduce a novel pose correlation module to compute similarities between non-aligned target and source poses, and then propose an adaptive reference selection strategy, utilizing the attention map to identify key regions for animation generation. To train our model, we curated a large dataset from public TED talks featuring varied shots of the same character, helping the model learn synthesis for different perspectives. Our experimental results show that with the same number of reference images, our model performs favorably compared to the …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Existing human Motion Capture (MoCap) method mostly focus on the visual similarity while neglecting the physical plausibility. As a result, downstream tasks such as driving virtual human in 3D scene or humanoid robots in real world suffer from issues such as timing drift and jitter, spatial problems like sliding and penetration, and poor global trajectory accuracy. In this paper, we revisit human MoCap from the perspective of interaction between human body and physical world by exploring the role of pressure. Firstly, we construct a large-scale Human Motion capture dataset with Pressure, RGB and Optical sensors (named MotionPRO), which comprises 70 volunteers performing 400 types of motion. Secondly, we examine both the necessity and effectiveness of the pressure signal through two challenging tasks: (1) pose and trajectory estimation based solely on pressure: We propose a network that incorporates a small-kernel decoder and a long-short-term attention module, and proof that pressure could provide accurate global trajectory and plausible lower body pose. (2) pose and trajectory estimation by fusing pressure and RGB: We impose constraints on orthographic similarity along the camera axis and whole-body contact along the vertical axis to enhance the cross-attention strategy for fusing pressure and RGB feature maps. Experiments demonstrate …
|
|
Highlight
|
Poster
[ ExHall D ] 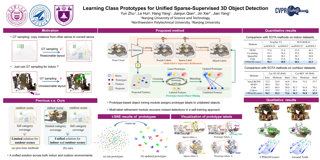
Abstract
Both indoor and outdoor scene perceptions are essential for embodied intelligence. However, current sparse supervised 3D object detection methods focus solely on outdoor scenes without considering indoor settings. To this end, we propose a unified sparse supervised 3D object detection method for both indoor and outdoor scenes through learning class prototypes to effectively utilize unlabeled objects. Specifically, we first propose a prototype-based object mining module that converts the unlabeled object mining into a matching problem between class prototypes and unlabeled features. By using optimal transport matching results, we assign prototype labels to high-confidence features, thereby achieving the mining of unlabeled objects. We then present a multi-label cooperative refinement module to effectively recover missed detections in sparse supervised 3D object detection through pseudo label quality control and prototype label cooperation. Experiments show that our method achieves state-of-the-art performance under the one object per scene sparse supervised setting across indoor and outdoor datasets. With only one labeled object per scene, our method achieves about 78\%, 90\%, and 96\% performance compared to the fully supervised detector on ScanNet V2, SUN RGB-D, and KITTI, respectively, highlighting the scalability of our method.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Parameter-efficient fine-tuning (PEFT) has attracted significant attention due to the growth of pre-trained model sizes and the need to fine-tune (FT) them for superior downstream performance. Despite a surge in new PEFT methods, a systematic study to understand their performance and suitable application scenarios is lacking, leaving questions like "when to apply PEFT" and "which method to use" largely unanswered, especially in visual recognition. In this paper, we conduct a unifying empirical study of representative PEFT methods with Vision Transformers. We systematically tune their hyper-parameters to fairly compare their accuracy on downstream tasks. Our study offers a practical user guide and unveils several new insights. First, if tuned carefully, different PEFT methods achieve similar accuracy in the low-shot benchmark VTAB-1K. This includes simple approaches like FT the bias terms that were reported inferior. Second, despite similar accuracy, we find that PEFT methods make different mistakes and high-confidence predictions, likely due to their different inductive biases. Such an inconsistency (or complementariness) opens up the opportunity for ensemble methods, and we make preliminary attempts at this. Third, going beyond the commonly used low-shot tasks, we find that PEFT is also useful in many-shot regimes, achieving comparable or better accuracy than full FT …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
There is growing interest in solving computer vision problems such as mesh or point set alignment using Adiabatic Quantum Computing (AQC). Unfortunately, modern experimental AQC devices such as D-Wave only support Quadratic Unconstrained Binary Optimization (QUBO) problems, which severely limits their applicability. This paper proposes a new way to overcome this limitation and introduces QuCOOP, an optimization framework extending the scope of AQC to composite and binary-parameterized, possibly non-quadratic problems. The key idea of QuCOOP is to iteratively approximate the original objective function by a sequel of local (intermediate) QUBO forms, whose binary parameters can be sampled on AQC devices. We experiment with quadratic assignment problems, shape matching and point set registration without knowing the correspondences in advance. Our approach achieves state-of-the-art results across multiple instances of tested problems.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Traditional feedback learning for hallucination reduction relies on labor-intensive manual labeling or expensive proprietary models.This leaves the community without foundational knowledge about how to build high-quality feedback with open-source MLLMs.In this work, we introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm. RLAIF-V maximally explores open-source MLLMs from two perspectives, including high-quality feedback data generation for preference learning and self-feedback guidance for inference-time scaling.Extensive experiments on seven benchmarks in both automatic and human evaluation show that RLAIF-V substantially enhances the trustworthiness of models at both preference learning and inference time. RLAIF-V 7B reduces object hallucination by 80.7\% and overall hallucination by 33.7\%. Remarkably, RLAIF-V 12B further reveals the self-alignment potential of open-source MLLMs, where the model can learn from feedback of itself to achieve super GPT-4V trustworthiness.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Subject-driven image personalization has seen notable advancements, especially with the advent of the ReferenceNet paradigm. ReferenceNet excels in integrating image reference features, making it highly applicable in creative and commercial settings. However, current implementations of ReferenceNet primarily operate as latent-level feature extractors, which limit their potential. This constraint hinders the provision of appropriate features to the denoising backbone across different timesteps, leading to suboptimal image consistency. In this paper, we revisit the extraction of reference features and propose TFCustom, a model framework designed to focus on reference image features at different temporal steps and frequency levels. Specifically, we firstly propose synchronized ReferenceNet to extract reference image features while simultaneously optimizing noise injection and denoising for the reference image. We also propose a time-aware frequency feature refinement module that leverages high- and low-frequency filters, combined with time embeddings, to adaptively select the degree of reference feature injection. Additionally, to enhance the similarity between reference objects and the generated image, we introduce a novel reward-based loss that encourages greater alignment between the reference and generated images. Experimental results demonstrate state-of-the-art performance in both multi-object and single-object reference generation, with significant improvements in texture and textual detail generation over existing methods.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Multimodal Language Learning Models (MLLMs) have shown remarkable performance in image understanding, generation, and editing, with recent advancements achieving pixel-level grounding with reasoning. However, these models for common objects struggle with fine-grained face understanding. In this work, we introduce the \textbf{\textit{FacePlayGround-240K}} dataset, the first pioneering large-scale, pixel-grounded face caption and question-answer (QA) dataset, meticulously curated for alignment pretraining and instruction-tuning. We present the \textbf{\textit{GroundingFace}} framework, specifically designed to enhance fine-grained face understanding. This framework significantly augments the capabilities of existing grounding models in face part segmentation, face attribute comprehension, while preserving general scene understanding. Comprehensive experiments validate that our approach surpasses current state-of-the-art models in pixel-grounded face captioning/QA and various downstream tasks, including face captioning, referring segmentation, and zero-shot face attribute recognition.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Autoregressive models have emerged as a powerful approach for visual generation but suffer from slow inference speed due to their sequential token-by-token prediction process.In this paper, we propose a simple yet effective approach for parallelized autoregressive visual generation that improves generation efficiency while preserving the advantages of autoregressive modeling.Our key insight is that the feasibility of parallel generation is closely tied to visual token dependencies - while tokens with weak dependencies can be generated in parallel, adjacent tokens with strong dependencies are hard to generate together, as independent sampling of strongly correlated tokens may lead to inconsistent decisions.Based on this observation, we develop a parallel generation strategy that generates distant tokens with weak dependencies in parallel while maintaining sequential generation for strongly dependent local tokens. Specifically, we first generate initial tokens in each region sequentially to establish the global structure, then enable parallel generation across distant regions while maintaining sequential generation within each region. Our approach can be seamlessly integrated into standard autoregressive models without modifying the architecture or tokenizer. Experiments on ImageNet and UCF-101 demonstrate that our method achieves a 3.6$\times$ speedup with comparable quality and up to 9.5$\times$ speedup with minimal quality degradation across both image and video …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recovering 3D scenes from sparse views is a challenging task due to its inherent ill-posed problem. Conventional methods have developed specialized solutions (e.g., geometry regularization or feed-forward deterministic model) to mitigate the issue. However, they still suffer from performance degradation by minimal overlap across input views with insufficient visual information. Fortunately, recent video generative models show promise in addressing this challenge as they are capable of generating video clips with plausible 3D structures. Powered by large pretrained video diffusion models, some pioneering research start to explore the potential of video generative prior and create 3D scenes from sparse views. Despite impressive improvements, they are limited by slow inference time and the lack of 3D constraint, leading to inefficiencies and reconstruction artifacts that do not align with real-world geometry structure. In this paper, we propose VideoScene to distill the video diffusion model to generate 3D scenes in one step, aiming to build an efficient and effective tool to bridge the gap from video to 3D. Specifically, we design a 3D-aware leap flow distillation strategy to leap over time-consuming redundant information and train a dynamic denoising policy network to adaptively determine the optimal leap timestep during inference. Extensive experiments demonstrate that our …
|
|
Highlight
|
Poster
[ ExHall D ] 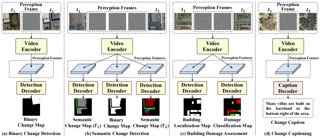
Abstract
In this paper, we present Change3D, a framework that reconceptualizes the change detection and captioning tasks through video modeling. Recent methods have achieved remarkable success by regarding each pair of bi-temporal images as separate frames. They employ a shared-weight image encoder to extract spatial features and then use a change extractor to capture differences between the two images. However, image feature encoding, being a task-agnostic process, cannot attend to changed regions effectively. Furthermore, different change extractors designed for various change detection and captioning tasks make it difficult to have a unified framework. To tackle these challenges, Change3D regards the bi-temporal images as comprising two frames akin to a tiny video. By integrating learnable perception frames between the bi-temporal images, a video encoder enables the perception frames to interact with the images directly and perceive their differences. Therefore, we can get rid of the intricate change extractors, providing a unified framework for different change detection and captioning tasks. We verify Change3D on multiple tasks, encompassing change detection (including binary change detection, semantic change detection, and building damage assessment) and change captioning, across eight standard benchmarks. Without bells and whistles, this simple yet effective framework can achieve superior performance with an ultra-light …
|
|
Highlight
|
Poster
[ ExHall D ] 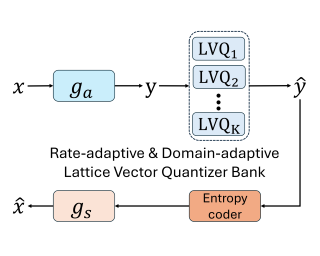
Abstract
Recent research has explored integrating lattice vector quantization (LVQ) into learned image compression models. Due to its more efficient Voronoi covering of vector space than scalar quantization (SQ), LVQ achieves better rate-distortion (R-D) performance than SQ, while still retaining the low complexity advantage of SQ. However, existing LVQ-based methods have two shortcomings: 1) lack of a multirate coding mode, hence incapable to operate at different rates; 2) the use of a fixed lattice basis, hence nonadaptive to changing source distributions. To overcome these shortcomings, we propose a novel adaptive LVQ method, which is the first among LVQ-based methods to achieve both rate and domain adaptations. By scaling the lattice basis vector, our method can adjust the density of lattice points to achieve various bit rate targets, achieving superior R-D performance to current SQ-based variable rate models. Additionally, by using a learned invertible linear transformation between two different input domains, we can reshape the predefined lattice cell to better represent the target domain, further improving the R-D performance. To our knowledge, this paper represents the first attempt to propose a unified solution for rate adaptation and domain adaptation through quantizer design.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Multimodal Large Language Models (MLLMs) hallucinate, resulting in an emerging topic of visual hallucination evaluation (VHE). This paper contributes a ChatGPT-Prompted visual hallucination evaluation Dataset (PhD) for objective VHE at a large scale. The essence of VHE is to ask an MLLM questions about specific images to assess its susceptibility to hallucination. Depending on what to ask (objects, attributes, sentiment, etc.) and how the questions are asked, we structure PhD along two dimensions, i.e., task and mode. Five visual recognition tasks, ranging from low-level (object / attribute recognition) to middle-level (sentiment / position recognition and counting), are considered. Besides a normal visual QA mode, which we term PhD-base, PhD also asks questions with inaccurate context (PhD-iac) or with incorrect context (PhD-icc), or with AI-generated counter common sense images (PhD-ccs). We construct PhD by a ChatGPT-assisted semi-automated pipeline, encompassing four pivotal modules: task-specific hallucinatory item (hitem) selection, hitem-embedded question generation, inaccurate / incorrect context generation, and counter-common-sense (CCS) image generation. With over 14k daily images, 750 CCS images and 102k VQA triplets in total, PhD reveals considerable variability in MLLMs' performance across various modes and tasks, offering valuable insights into the nature of hallucination. As such, PhD stands as a potent …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image generation models are capable of producing harmful content, such as images containing sexual or violent material. Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities. Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive. Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)? Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models. To address these challenges, we propose a …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Long video generation involves generating extended videos using models trained on short videos, suffering from distribution shifts due to varying frame counts. It necessitates the use of local information from the original short frames to enhance visual and motion quality, and global information from the entire long frames to ensure appearance consistency. Existing training-free methods struggle to effectively integrate the benefits of both, as appearance and motion in videos are closely coupled, leading to inconsistency and poor quality. In this paper, we reveal that global and local information can be precisely decoupled into consistent appearance and motion intensity information by applying Principal Component Analysis (PCA), allowing for refined complementary integration of global consistency and local quality. With this insight, we propose FreePCA, a training-free long video generation paradigm based on PCA that simultaneously achieves high consistency and quality. Concretely, we decouple consistent appearance and motion intensity features by measuring cosine similarity in the principal component space. Critically, we progressively integrate these features to preserve original quality and ensure smooth transitions, while further enhancing consistency by reusing the mean statistics of the initial noise. Experiments demonstrate that FreePCA can be applied to various video diffusion models without requiring training, leading to …
|
|
Highlight
|
Poster
[ ExHall D ] 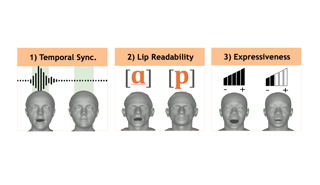
Abstract
Recent advancements in speech-driven 3D talking head generation have achieved impressive advance in lip synchronization. However, existing models still fall short in capturing a perceptual alignment between diverse speech characteristics and lip movements. In this work, we define essential criteria—temporal synchronization, lip readability, and expressiveness— for perceptually accurate lip movements in response to speech signals. We also introduce a speech-mesh synchronized representation that captures the intricate correspondence between speech and facial mesh. We plug in this representation as a perceptual loss to guide lip movements, ensuring they are perceptually aligned with the given speech. Additionally, we utilize this representation as a perceptual metric and introduce two other physically-grounded lip synchronization metrics to evaluate these three criteria. Experiments demonstrate that training 3D talking head models with our perceptual loss significantly enhances all three aspects of perceptually accurate lip synchronization. Codes will be released if accepted.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Multi-view clustering (MVC) aims to exploit complementary information from diverse views to enhance clustering performance. Since pseudo-labels can provide additional semantic information, many MVC methods have been proposed to guide unsupervised multi-view learning through pseudo-labels. These methods implicitly assume that the predicted pseudo-labels are predicted correctly. However, due to the challenges in training a flawless unsupervised model, this assumption can be easily violated, thereby leading to the Noisy Pseudo-label Problem (NPP). Moreover, these existing approaches typically rely on the assumption of perfect cross-view alignment. In practice, it is frequently compromised due to noise or sensor differences, thereby resulting in the Noisy Correspondence Problem (NCP). Based on the above observations, we reveal and study unsupervised multi-view learning under NPP and NCP. To this end, we propose Robust Noisy Pseudo-label Learning (ROLL) to prevent the overfitting problem caused by both NPP and NCP. Specifically, we first adopt traditional contrastive learning to warm up the model, thereby generating the pseudo-labels in a self-supervised manner. Afterward, we propose noise-tolerance pseudo-label learning to deal with the noise in the predicted pseudo-labels, thereby embracing the robustness against NPP. To further mitigate the overfitting problem, we present robust multi-view contrastive learning to mitigate the negative impact of …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this paper, we propose an efficient multi-level convolution architecture for 3D visual grounding. Conventional methods are difficult to meet the requirements of real-time inference due to the two-stage or point-based architecture. Inspired by the success of multi-level fully sparse convolutional architecture in 3D object detection, we aim to build a new 3D visual grounding framework following this technical route. However, as in 3D visual grounding task the 3D scene representation should be deeply interacted with text features, sparse convolution-based architecture is inefficient for this interaction due to the large amount of voxel features. To this end, we propose text-guided pruning (TGP) and completion-based addition (CBA) to deeply fuse 3D scene representation and text features in an efficient way by gradual region pruning and target completion. Specifically, TGP iteratively sparsifies the 3D scene representation and thus efficiently interacts the voxel features with text features by cross-attention. To mitigate the affect of pruning on delicate geometric information, CBA adaptively fixes the over-pruned region by voxel completion with negligible computational overhead. Compared with previous single-stage methods, our method achieves top inference speed and surpasses previous fastest method by 100\% FPS. Our method also achieves state-of-the-art accuracy even compared with two-stage methods, with …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Given a piece of text, a video clip, and a reference audio, the movie dubbing task aims to generate speech that aligns with the video while cloning the desired voice. The existing methods have two primary deficiencies: (1) They struggle to simultaneously hold audio-visual sync and achieve clear pronunciation; (2) They lack the capacity to express user-defined emotions. To address these problems, we propose EmoDubber, an emotion-controllable dubbing architecture that allows users to specify emotion type and emotional intensity while satisfying high-quality lip sync and pronunciation. Specifically, we first design Lip-related Prosody Aligning (LPA), which focuses on learning the inherent consistency between lip motion and prosody variation by duration level contrastive learning to incorporate reasonable alignment. Then, we design Pronunciation Enhancing (PE) strategy to fuse the video-level phoneme sequences by efficient conformer to improve speech intelligibility. Next, the speaker identity adapting module aims to decode acoustics prior and inject the speaker style embedding. After that, the proposed Flow-based User Emotion Controlling (FUEC) is used to synthesize waveform by flow matching prediction network conditioned on acoustics prior. In this process, the FUEC determines the gradient direction and guidance scale based on the user's emotion instructions by the positive and negative guidance …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Estimating 3D motion from 2D observations is a long-standing research challenge. Prior work typically requires training on datasets containing ground truth 3D motions, limiting their applicability to activities well-represented in existing motion capture data. This dependency particularly hinders generalization to out-of-distribution scenarios or subjects where collecting 3D ground truth is challenging, such as complex athletic movements or animal motion. We introduce MVLift, a novel approach to predict global 3D motion---including both joint rotations and root trajectories in the world coordinate system---using only 2D pose sequences for training. Our multi-stage framework leverages 2D motion diffusion models to progressively generate consistent 2D pose sequences across multiple views, a key step in recovering accurate global 3D motion. MVLift generalizes across various domains, including human poses, human-object interactions, and animal poses. Despite not requiring 3D supervision, it outperforms prior work on five datasets, including those methods that require 3D supervision.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
This paper introduces a novel dataset construction pipeline that samples pairs of frames from videos and uses multimodal large language models (MLLMs) to generate editing instructions for training instruction-based image manipulation models. Video frames inherently preserve the identity of subjects and scenes, ensuring consistent content preservation during editing. Additionally, video data captures diverse, natural dynamics—such as non-rigid subject motion and complex camera movements—that are difficult to model otherwise, making it an ideal source for scalable dataset construction. Using this approach, we create a new dataset to train InstructMove, a model capable of instruction-based complex manipulations that are difficult to achieve with synthetically generated datasets. Our model demonstrates state-of-the-art performance in tasks such as adjusting subject poses, rearranging elements, and altering camera perspectives.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent 3D deep networks such as SwinUNETR, SwinUNETRv2, and 3D UX-Net have shown promising performance by leveraging self-attention and large-kernel convolutions to capture the volumetric context. However, their substantial computational requirements limit their use in real-time and resource-constrained environments. The high #FLOPs and #Params in these networks stem largely fromcomplex decoder designs with high-resolution layers and excessive channel counts. In this paper, we propose EffiDec3D, an optimized 3D decoder that employs a channel reduction strategy across all decoder stages, which sets the number of channels to the minimum needed for accurate feature representation. Additionally, EffiDec3D removes the high-resolution layers when their contribution to segmentation quality is minimal. Our optimized EffiDec3D decoder achieves a 96.4% reduction in #Params and a 93.0% reduction in #FLOPs compared to the decoder of original 3D UX-Net. Similarly, for SwinUNETR and SwinUNETRv2 (which share an identical decoder), we observe reductions of 94.9% in #Params and 86.2% in #FLOPs. Our extensive experiments on 12 different medical imaging tasks confirm that EffiDec3D not only significantly reduces the computational demands, but also maintains a performance level comparable to original models, thus establishing a new standard for efficient 3D medical image segmentation. We will make the source code public upon …
|
|
Highlight
|
Poster
[ ExHall D ] 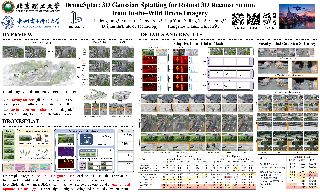
Abstract
Drones have become essential tools for reconstructing wild scenes due to their outstanding maneuverability. Recent advances in radiance field methods have achieved remarkable rendering quality, providing a new avenue for 3D reconstruction from drone imagery. However, dynamic distractors in wild environments challenge the static scene assumption in radiance fields, while limited view constraints hinder the accurate capture of underlying scene geometry. To address these challenges, we introduce DroneSplat, a novel framework designed for robust 3D reconstruction from in-the-wild drone imagery. Our method adaptively adjusts masking thresholds by integrating local-global segmentation heuristics with statistical approaches, enabling precise identification and elimination of dynamic distractors in static scenes. We enhance 3D Gaussian Splatting with multi-view stereo predictions and a voxel-guided optimization strategy, supporting high-quality rendering under limited view constraints. For comprehensive evaluation, we provide a drone-captured 3D reconstruction dataset encompassing both dynamic and static scenes. Extensive experiments demonstrate that DroneSplat outperforms both 3DGS and NeRF baselines in handling in-the-wild drone imagery.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Building Free-Viewpoint Videos in a streaming manner offers the advantage of rapid responsiveness compared to offline training methods, greatly enhancing user experience. However, current streaming approaches face challenges of high per-frame reconstruction time (10s+) and error accumulation, limiting their broader application. In this paper, we propose Instant Gaussian Stream (IGS), a fast and generalizable streaming framework, to address these issues. First, we introduce a generalized Anchor-driven Gaussian Motion Network, which projects multi-view 2D motion features into 3D space, using anchor points to drive the motion of all Gaussians. This generalized Network generates the motion of Gaussians for each target frame in the time required for a single inference. Second, we propose a Key-frame-guided Streaming Strategy that refines each key frame, enabling accurate reconstruction of temporally complex scenes while mitigating error accumulation. We conducted extensive in-domain and cross-domain evaluations, demonstrating that our approach can achieve streaming with a average per-frame reconstruction time of 2s+, alongside a enhancement in view synthesis quality.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus remains on developing their capabilities in static image understanding. The potential of MLLMs to process sequential visual data is still insufficiently explored, highlighting the lack of a comprehensive, high-quality assessment of their performance. In this paper, we introduce Video-MME, the first-ever full-spectrum, Multi-Modal Evaluation benchmark of MLLMs in Video analysis. Our work distinguishes from existing benchmarks through four key features: 1) Diversity in video types, spanning 6 primary visual domains with 30 subfields to ensure broad scenario generalizability; 2) Duration in temporal dimension, encompassing both short-, medium-, and long-term videos, ranging from 11 seconds to 1 hour, for robust contextual dynamics; 3) Breadth in data modalities, integrating multi-modal inputs besides video frames, including subtitles and audios, to unveil the all-round capabilities of MLLMs; 4) Quality in annotations, utilizing rigorous manual labeling by expert annotators to facilitate precise and reliable model assessment. With Video-MME, we extensively evaluate various state-of-the-art MLLMs, and reveal that Gemini 1.5 Pro is the best-performing commercial model, significantly outperforming the open-source models with an average accuracy of 75\%, compared to 71.9% for …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Self-Supervised Learning (SSL) presents an exciting opportunity to unlock the potential of vast, untapped clinical datasets, for various downstream applications that suffer from the scarcity of labeled data.While SSL has revolutionized fields like natural language processing and computer vision, its adoption in 3D medical image computing has been limited by three key pitfalls: Small pre-training dataset sizes, architectures inadequate for 3D medical image analysis, and insufficient evaluation practices. In this paper, we address these issues by i) leveraging a large-scale dataset of 39k 3D brain MRI volumes and ii) using a Residual Encoder U-Net architecture within the state-of-the-art nnU-Net framework. iii) A robust development framework, incorporating 5 development and 8 testing brain MRI segmentation datasets, allowed performance-driven design decisions to optimize the simple concept of Masked Auto Encoders (MAEs) for 3D CNNs. The resulting model not only surpasses previous SSL methods but also outperforms the strong nnU-Net baseline by an average of approximately 3 Dice points setting a new state-of-the-art.Our code and models are made available.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
This paper introduces a novel approach to improve camera position estimation in global Structure-from-Motion (SfM) frameworks by filtering inaccurate pose graph edges, representing relative translation estimates, before applying translation averaging. In SfM, pose graph vertices represent cameras and edges relative poses (rotation and translation) between cameras. We formulate the edge filtering problem as a vertex filtering in the dual graph - a line graph where the vertices stem from edges in the original graph, and the edges from cameras. Exploiting such a representation, we frame the problem as a binary classification over nodes in the dual graph. To learn such a classification and find outlier edges, we employ a Transformer architecture-based technique. To address the challenge of memory overflow often caused by converting to a line graph, we introduce a clustering-based graph processing approach, enabling the application of our method to arbitrarily large pose graphs. The proposed method outperforms existing relative translation filtering techniques in terms of final camera position accuracy and can be seamlessly integrated with any other filter. The code will be made public.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Recent advancements in diffusion models have set new benchmarks in image and video generation, enabling realistic visual synthesis across single- and multi-frame contexts. However, these models still struggle with efficiently and explicitly generating 3D-consistent content. To address this, we propose World-consistent Video Diffusion (WVD), a novel framework that incorporates explicit 3D supervision using XYZ images, which encode global 3D coordinates for each image pixel. More specifically, we train a diffusion transformer to learn the joint distribution of RGB and XYZ frames. This approach supports multi-task adaptability via a flexible inpainting strategy. For example, WVD can estimate XYZ frames from ground-truth RGB or generate novel RGB frames using XYZ projections along a specified camera trajectory. In doing so, WVD unifies tasks like single-image-to-3D generation, multi-view stereo, and camera-controlled video generation.Our approach demonstrates competitive performance across multiple benchmarks, providing a scalable solution for 3D-consistent video and image generation with a single pretrained model.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this work, we tackle action-scene hallucination in Video Large Language Models (Video-LLMs), where models incorrectly predict actions based on the scene context or scenes based on observed actions. We observe that existing Video-LLMs often suffer from action-scene hallucination due to two main factors. First, existing Video-LLMs intermingle spatial and temporal features by applying an attention operation across all tokens. Second, they use the standard Rotary Position Embedding (RoPE), which causes the text tokens to overemphasize certain types of tokens depending on their sequential orders. To address these issues, we introduce MASH-VLM, Mitigating Action-Scene Hallucination in Video-LLMs through disentangled spatial-temporal representations. Our approach includes two key innovations: (1) DST-attention, a novel attention mechanism that disentangles the spatial and temporal tokens within the LLM by using masked attention to restrict direct interactions between the spatial and temporal tokens; (2) Harmonic-RoPE, which extends the dimensionality of the positional IDs, allowing the spatial and temporal tokens to maintain balanced positions relative to the text tokens. To evaluate the action-scene hallucination in Video-LLMs, we introduce the UNSCENE benchmark with 1,320 videos and 4,078 QA pairs. Extensive experiments demonstrate that MASH-VLM achieves state-of-the-art results on the UNSCENE benchmark, as well as on existing video understanding …
|
|
Highlight
|
Poster
[ ExHall D ] 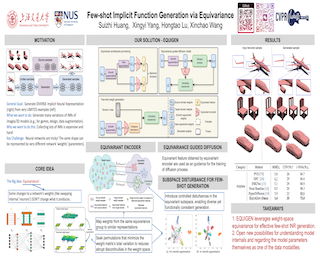
Abstract
Implicit Neural Representations (INRs) have emerged as a powerful framework for representing continuous signals. However, generating diverse INR weights remains challenging due to limited training data. We introduce Few-shot Implicit Function Generation, a new problem setup that aims to generate diverse yet functionally consistent INR weights from only a few examples. This is challenging because even for the same signal, the optimal INRs can vary significantly depending on their initializations. To tackle this, we propose EquiGen, a framework that can generate new INRs from limited data. The core idea is that functionally similar networks can be transformed into one another through weight permutations, forming an equivariance group. By projecting these weights into an equivariant latent space, we enable diverse generation within these groups, even with few examples. EquiGen implements this through an equivariant encoder trained via contrastive learning and smooth augmentation, an equivariance-guided diffusion process, and controlled perturbations in the equivariant subspace. Experiments on 2D image and 3D shape INR datasets demonstrate that our approach effectively generates diverse INR weights while preserving their functional properties in few-shot scenarios.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Diffusion models, and their generalization, flow matching, have had a remarkable impact on the field of media generation. Here, the conventional approach is to learn the complex mapping from a simple source distribution of Gaussian noise to the target media distribution. For cross-modal tasks such as text-to-image generation, this same mapping from noise to image is learnt whilst including a conditioning mechanism in the model. One key and thus far relatively unexplored feature of flow matching is that, unlike Diffusion models, they are not constrained for the source distribution to be noise. Hence, in this paper, we propose a paradigm shift, and ask the question of whether we can instead train flow matching models to learn a direct mapping from the distribution of one modality to the distribution of another, thus obviating the need for both the noise distribution and conditioning mechanism. We present a general and simple framework, CrossFlow, for cross-modal flow matching. We show the importance of applying Variational Encoders to the input data, and introduce a method to enable Classifier-free guidance. Surprisingly, for text-to-image, CrossFlow with a vanilla transformer without cross attention slightly outperforms standard flow matching, and we show that it scales better with training steps …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
A variety of text-guided image editing models have been proposed recently. However, there is no widely-accepted standard evaluation method mainly due to the subjective nature of the task, letting researchers rely on manual user study. To address this, we introduce a novel Human-Aligned benchmark for Text-guided Image Editing (HATIE). Providing a large-scale benchmark set covering a wide range of editing tasks, it allows reliable evaluation, not limited to specific easy-to-evaluate cases. Also, HATIE provides a fully-automated and omnidirectional evaluation pipeline. Particularly, we combine multiple scores measuring various aspects of editing so as to align with human perception. We empirically verify that the evaluation of HATIE is indeed human-aligned in various aspects, and provide benchmark results on several state-of-the-art models to provide deeper insights on their performance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The increasing demand for high-quality 3D assets across various industries necessitates efficient and automated 3D content creation. Despite recent advancements in 3D generative models, existing methods still face challenges with optimization speed, geometric fidelity, and the lack of assets for physically based rendering (PBR). In this paper, we introduce 3DTopia-XL, a scalable native 3D generative model designed to overcome these limitations. 3DTopia-XL leverages a novel primitive-based 3D representation, PrimX, which encodes detailed shape, albedo, and material field into a compact tensorial format, facilitating the modeling of high-resolution geometry with PBR assets. On top of the novel representation, we propose a generative framework based on Diffusion Transformer (DiT), which comprises 1) Primitive Patch Compression, 2) and Latent Primitive Diffusion. 3DTopia-XL learns to generate high-quality 3D assets from textual or visual inputs. Extensive qualitative and quantitative experiments are conducted to demonstrate that 3DTopia-XL significantly outperforms existing methods in generating high-quality 3D assets with fine-grained textures and materials, efficiently bridging the quality gap between generative models and real-world applications.
|
|
Highlight
|
Poster
[ ExHall D ] 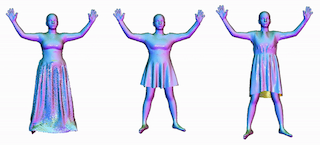
Abstract
Achieving realistic animated human avatars requires accurate modeling of pose-dependent clothing deformations. Existing learning-based methods heavily rely on the Linear Blend Skinning (LBS) of minimally-clothed human models like SMPL to model deformation. However, these methods struggle to handle loose clothing, such as long dresses, where the canonicalization process becomes ill-defined when the clothing is far from the body, leading to disjointed and fragmented results. To overcome this limitation, we propose a novel hybrid framework to model challenging clothed humans. Our core idea is to use dedicated strategies to model different regions, depending on whether they are close to or distant from the body. This free-form generation paradigm brings enhanced flexibility and expressiveness to our hybrid framework, enabling it to capture the intricate geometric details of challenging loose clothing, such as skirts and dresses. Experimental results on the benchmark dataset featuring loose clothing demonstrate that our method achieves state-of-the-art performance with superior visual fidelity and realism, particularly in the most challenging cases.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Unsupervised Camoflaged Object Detection (UCOD) has gained attention since it doesn't need to rely on extensive pixel-level labels. Existing UCOD methods typically generate pseudo-labels using fixed strategies and train $1 \times 1$ convolutional layers as a simple decoder, leading to low performance compared to fully-supervised methods. We emphasize two drawbacks in these approaches: 1). The model is prone to fitting incorrect knowledge due to the pseudo-label containing substantial noise. 2). The simple decoder fails to capture and learn the semantic features of camouflaged objects, especially for small-sized objects, due to the low-resolution pseudo-labels and severe confusion between foreground and background pixels. To this end, we propose a UCOD method with a teacher-student framework via Dynamic Pseudo-label Learning called UCOD-DPL, which contains an Adaptive Pseudo-label Module (APM), a Dual-Branch Adversarial (DBA) decoder, and a Look-Twice mechanism. The APM module adaptively combines pseudo-labels generated by fixed strategies and the teacher model to prevent the model from overfitting incorrect knowledge while preserving the ability for self-correction; the DBA decoder takes adversarial learning of different segmentation objectives, guides the model to overcome the foreground-background confusion of camouflaged objects, and the Look-Twice mechanism mimics the human tendency to zoom in on camouflaged objects and performs …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Training-free diffusion-based methods have achieved remarkable success in style transfer, eliminating the need for extensive training or fine-tuning. However, due to the lack of targeted training for style information extraction and constraints on the content image layout, training-free methods often suffer from layout changes of original content and content leakage from style images. Through a series of experiments, we discovered that an effective startpoint in the sampling stage significantly enhances the style transfer process. Based on this discovery, we propose StyleSSP, which focuses on obtaining a better startpoint to address layout changes of original content and content leakage from style image. StyleSSP comprises two key components: (1) Frequency Manipulation: To improve content preservation, we reduce the low-frequency components of the DDIM latent, allowing the sampling stage to pay more attention to the layout of content images; and (2) Negative Guidance via Inversion: To mitigate the content leakage from style image, we employ negative guidance in the inversion stage to ensure that the startpoint of the sampling stage is distanced from the content of style image. Experiments show that StyleSSP surpasses previous training-free style transfer baselines, particularly in preserving original content and minimizing the content leakage from style image.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent advancements in neural 3D representations, such as neural radiance fields (NeRF) and 3D Gaussian splatting (3DGS), have made accurate estimation of the 3D structure from multiview images possible. However, this capability is limited to estimating the visible external structure, and it is still difficult to identify the invisible internal structure hidden behind the surface. To overcome this limitation, we address a new task called structure from collision (SfC), which aims to estimate the structure (including the invisible internal one) of an object from the appearance changes at collision. To solve this task, we propose a novel model called SfC-NeRF, which optimizes the invisible internal structure (i.e., internal volume density) of the object through a video sequence under physical, appearance (i.e., visible external structure)-preserving, and key-frame constraints. In particular, to avoid falling into undesirable local optima owing to its ill-posed nature, we propose volume annealing, i.e., searching for the global optima by repeatedly reducing and expanding the volume. Extensive experiments on 60 cases involving diverse structures (i.e., various cavity shapes, locations, and sizes) and various material properties reveal the properties of SfC and demonstrate the effectiveness of the proposed SfC-NeRF.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Traditional reinforcement learning methods for interaction skills rely on labor-intensive, manually designed rewards that do not generalize well across different skills. Inspired by how humans learn from demonstrations, we propose ISMimic, the first data-driven approach that Mimics both human and ball motions to learn diverse Interaction Skills, e.g., a wide variety of challenging basketball skills. ISMimic employs a unified configuration to learn diverse interaction skills from human-ball motion datasets, with skill diversity and generalization improving as the dataset grows. This approach allows training a single policy to learn multiple interaction skills and allows smooth skill switching. The interaction skills acquired by ISMimic can be easily reused by a high-level controller to accomplish high-level tasks. To evaluate our approach, we introduce two basketball datasets that collectively contain about 35 minutes of diverse basketball skills. Experiments show that our method can effectively acquire various reusable basketball skills including diverse styles of dribbling, layup, and shooting. Video results and 3D visualization are available at https://ismimic.github.io
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Scene graph (SG) representations can neatly and efficiently describe scene semantics, which has driven sustained intensive research in SG generation. In the real world, multiple modalities often coexist, with different types, such as images, text, video, and 3D data, expressing distinct characteristics. Unfortunately, current SG research is largely confined to single-modality scene modeling, preventing the full utilization of the complementary strengths of different modality SG representations in depicting holistic scene semantics.To this end, we introduce Universal SG (USG), a novel representation capable of fully characterizing comprehensive semantic scenes from any given combination of modality inputs, encompassing modality-invariant and modality-specific scenes. Further, we tailor a niche-targeting USG parser, USG-Par, which effectively addresses two key bottlenecks of cross-modal object alignment and out-of-domain challenges. We design the USG-Par with modular architecture for end-to-end USG generation, in which we devise an object associator to relieve the modality gap for cross-modal object alignment. Further, we propose a text-centric scene contrasting learning mechanism to mitigate domain imbalances by aligning multimodal objects and relations with textual SGs. Through extensive experiments, we demonstrate that USG offers a stronger capability for expressing scene semantics than standalone SGs, and also that our USG-Par achieves higher efficacy and performance.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
As an effective approach to equip models with multi-task capabilities without additional training, model merging has garnered significant attention. However, existing merging methods face challenges of redundant parameter conflicts and the excessive storage burden of fine-tuned parameters. In this work, through controlled experiments, we reveal that for fine-tuned task vectors, only those parameters with magnitudes above a certain threshold contribute positively to the task, exhibiting a pulse-like characteristic. We then attempt leveraging this pulse-like characteristic to binarize the task vectors and reduce storage overhead. Further controlled experiments show that the binarized task vectors incur almost no decrease in fine-tuning and merging performance, and even exhibit stronger performance improvements as the proportion of redundant parameters increases. Based on these insights, we propose Task Switch (T-Switch), which decomposes task vectors into three components: 1) an activation switch instantiated by a binarized mask vector, 2) a polarity switch instantiated by a binarized sign vector, and 3) a scaling knob instantiated by a scalar coefficient. By storing task vectors in a binarized form, T-Switch alleviates parameter conflicts while ensuring efficient task parameter storage. Furthermore, to enable automated switch combination in T-Switch, we further introduce Auto-Switch, which enables training-free switch combination via retrieval from a …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Temporal consistency is critical in video prediction. Traditional methods, such as temporal attention mechanisms and 3D convolutions, often struggle with significant object movements and fail to capture long-range temporal dependencies in dynamic scenes. To address these limitations, we propose the Tracktention Layer, a novel architectural component that explicitly integrates motion information using point tracks — sequences of corresponding points across frames. By incorporating these motion cues, the Tracktention Layer enhances temporal alignment and effectively handles complex object motions, maintaining consistent feature representations over time. Our approach is computationally efficient and can be seamlessly integrated into existing models, such as Vision Transformers, with minimal modification. Empirical evaluations on standard video estimation benchmarks demonstrate that models augmented with the Tracktention Layer exhibit significantly improved temporal consistency compared to baseline models.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Monitoring wildlife is essential for ecology and especially in light of the increasing human impact on ecosystems. Camera traps have emerged as habitat-centric sensors enabling the study of wildlife-environment interactions at scale with minimal disturbance. While computer vision models are becoming more powerful for general video understanding tasks, they struggle comparatively with camera trap videos. This gap in terms of performance and applicability can be partly attributed to the lack of annotated video datasets. To advance research in wild animal behavior monitoring we present MammAlps, a multimodal and multi-view dataset of wildlife behavior monitoring from 9 camera-traps in the Swiss National Park. MammAlps contains over 14 hours of video with audio, 2D segmentation maps and 8.5 hours of individual tracks densely labeled for species and behavior. Behaviors were annotated at two levels of complexity: actions representing simple behaviors and high-level activities. Based on 6,135 single animal clips, we propose the first hierarchical and multimodal animal behavior recognition benchmark using audio, video and reference scene segmentation maps as inputs. To enable future ecology research, we also propose a second benchmark aiming at identifying activities, species, number of individuals and meteorological conditions from 397 multi-view and long-term ecological events, including false positive …
|
|
Highlight
|
Poster
[ ExHall D ] 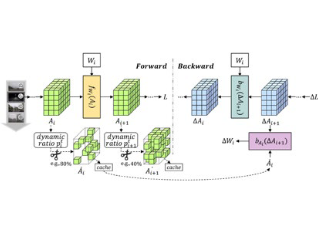
Abstract
Despite the growing integration of deep models into mobile and embedded terminals, the accuracy of these models often declines significantly during inference due to various deployment interferences. Test-time adaptation (TTA) has emerged as an effective strategy to improve the performance of deep models by adapting them to unlabeled target data online. Yet, the significant memory cost, particularly in memory-constrained IoT terminals, impedes the effective deployment of most backward-propagation-based TTA methods. To tackle memory constraints, we introduce SURGEON, a method that substantially reduces memory cost while preserving comparable accuracy improvements during fully test-time adaptation (FTTA) without relying on specific network architectures or modifications to the original training procedure. Specifically, we propose a novel dynamic activation sparsity strategy that directly prunes activations at layer-specific dynamic ratios, allowing for flexible control of learning ability and memory cost in a data-sensitive manner during adaptation. Among this, two metrics, Gradient Importance and Layer Activation Memory, are considered to determine the layer-wise activation pruning ratios, reflecting accuracy contribution and memory efficiency, respectively. Experimentally, our method surpasses previous TTA baselines by not only reducing memory usage but also achieving superior accuracy, delivering SOTA performance across diverse datasets, network architectures, and tasks.
|
|
Highlight
|
Poster
[ ExHall D ] 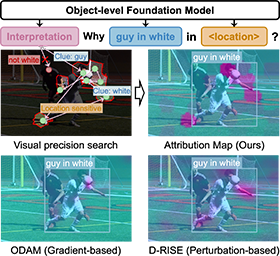
Abstract
Advances in multimodal pre-training have propelled object-level foundation models, such as Grounding DINO and Florence-2, in tasks like visual grounding and object detection. However, interpreting these models’ decisions has grown increasingly challenging. Existing interpretable attribution methods for object-level task interpretation have notable limitations: (1) gradient-based methods lack precise localization due to visual-textual fusion in foundation models, and (2) perturbation-based methods produce noisy saliency maps, limiting fine-grained interpretability. To address these, we propose a Visual Precision Search method that generates accurate attribution maps with fewer regions. Our method bypasses internal model parameters to overcome attribution issues from multimodal fusion, dividing inputs into sparse sub-regions and using consistency and collaboration scores to accurately identify critical decision-making regions. We also conducted a theoretical analysis of the boundary guarantees and scope of applicability of our method. Experiments on RefCOCO, MS COCO, and LVIS show our approach enhances object-level task interpretability over SOTA for Grounding DINO and Florence-2 across various evaluation metrics, with faithfulness gains of 23.7\%, 31.6\%, and 20.1\% on MS COCO, LVIS, and RefCOCO for Grounding DINO, and 102.9\% and 66.9\% on MS COCO and RefCOCO for Florence-2. Additionally, our method can interpret failures in visual grounding and object detection tasks, surpassing existing …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Generating 360-degree panoramas from narrow field of view (NFoV) image is a promising computer vision task for Virtual Reality (VR) applications. Existing methods mostly assess the generated panoramas with InceptionNet or CLIP based metrics, which tend to perceive the image quality and is $\textbf{not suitable for evaluating the distortion}$. In this work, we first propose a distortion-specific CLIP, named Distort-CLIP to accurately evaluate the panorama distortion and discover the $\textbf{``visual cheating''}$ phenomenon in previous works (i.e., tending to improve the visual results by sacrificing distortion accuracy). This phenomenon arises because prior methods employ a single network to learn the distinct panorama distortion and content completion at once, which leads the model to prioritize optimizing the latter. To address the phenomenon, we propose $\textbf{PanoDecouple}$, a decoupled diffusion model framework, which decouples the panorama generation into distortion guidance and content completion, aiming to generate panoramas with both accurate distortion and visual appeal. Specifically, we design a DistortNet for distortion guidance by imposing panorama-specific distortion prior and a modified condition registration mechanism; and a ContentNet for content completion by imposing perspective image information. Additionally, a distortion correction loss function with Distort-CLIP is introduced to constrain the distortion explicitly. The extensive experiments validate that …
|
|
Highlight
|
Poster
[ ExHall D ] 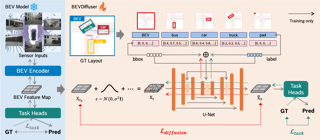
Abstract
Bird's-eye-view (BEV) representations play a crucial role in autonomous driving tasks. Despite recent advancements in BEV generation, inherent noise, stemming from sensor limitations and the learning process, remains largely unaddressed, resulting in suboptimal BEV representations that adversely impact the performance of downstream tasks. To address this, we propose BEVDiffuser, a novel diffusion model that effectively denoises BEV feature maps using the ground-truth object layout as guidance. BEVDiffuser can be operated in a plug-and-play manner during training time to enhance existing BEV models without requiring any architectural modifications. Extensive experiments on the challenging nuScenes dataset demonstrate BEVDiffuser's exceptional denoising and generation capabilities, which enable significant enhancement to existing BEV models, as evidenced by notable improvements of 12.3\% in mAP and 10.1\% in NDS achieved for 3D object detection without introducing additional computational complexity. Moreover, substantial improvements in long-tail object detection and under challenging weather and lighting conditions further validate BEVDiffuser's effectiveness in denoising and enhancing BEV representations.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this paper, we propose H-MoRe, a novel pipeline for learning precise human-centric motion representation. Our approach dynamically preserves relevant human motion while filtering out background movement. Notably, unlike previous methods relying on fully supervised learning from synthetic data, H-MoRe learns directly from real-world scenarios in a self-supervised manner, incorporating both human pose and body shape information. Inspired by kinematics, H-MoRe represents absolute and relative movements of each body point in a matrix format that captures nuanced motion details, termed world-local flows. H-MoRe offers refined insights into human motion, which can be integrated seamlessly into various action-related applications. Experimental results demonstrate that H-MoRe brings substantial improvements across various downstream tasks, including gait recognition(CL@R1: +16.01%), action recognition(Acc@1: +8.92%), and video generation(FVD: -67.07%). Additionally, H-MoRe exhibits high inference efficiency (34 fps), making it suitable for most real-time scenarios. Models and code will be released upon publication.
|
|
Highlight
|
Poster
[ ExHall D ] 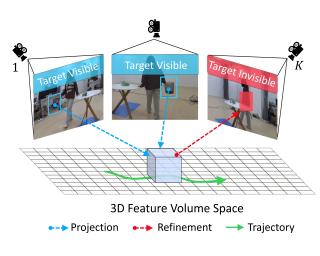
Abstract
Multi-view object tracking (MVOT) offers promising solutions to challenges such as occlusion and target loss, which are common in traditional single-view tracking. However, progress has been limited by the lack of comprehensive multi-view datasets and effective cross-view integration methods. To overcome these limitations, we compiled a Multi-View object Tracking (MVTrack) dataset of 234K high-quality annotated frames featuring 27 distinct objects across various scenes. In conjunction with this dataset, we introduce a novel MVOT method, Multi-View Integration Tracker (MITracker), to efficiently integrate multi-view object features and provide stable tracking outcomes. MITracker can track any object in video frames of arbitrary length from arbitrary viewpoints. The key advancements of our method over traditional single-view approaches come from two aspects: (1) MITracker transforms 2D image features into a 3D feature volume and compresses it into a bird’s eye view (BEV) plane, facilitating inter-view information fusion; (2) we propose an attention mechanism that leverages geometric information from fused 3D feature volume to refine the tracking results at each view. MITracker outperforms existing methods on the MVTrack and GMTD datasets, achieving state-of-the-art performance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In this paper, we present a new Structure-from-Motion pipeline that uses a non-parametric camera projection model. The model is self-calibrated during the reconstruction process and can fit a wide variety of cameras, ranging from simple low-distortion pinhole cameras to more extreme optical systems such as fisheye or catadioptric cameras. The key component in our framework is an adaptive calibration procedure that can estimate partial calibrations, only modeling regions of the image where sufficient constraints are available. In experiments, we show that our method achieves comparable accuracy in scenarios where traditional Structure-from-Motion pipelines excel and it outperforms its parametric opponents in cases where they are unable to self-calibrate their parametric models.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in multimodal research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including True/False, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model’s ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
How can we enable models to comprehend video anomalies occurring over varying temporal scales and contexts?Traditional Video Anomaly Understanding (VAU) methods focus on frame-level anomaly prediction, often missing the interpretability of complex and diverse real-world anomalies. Recent multimodal approaches leverage visual and textual data but lack hierarchical annotations that capture both short-term and long-term anomalies.To address this challenge, we introduce HIVAU-70k, a large-scale benchmark for hierarchical video anomaly understanding across any granularity. We develop a semi-automated annotation engine that efficiently scales high-quality annotations by combining manual video segmentation with recursive free-text annotation using large language models (LLMs). This results in over 70,000 multi-granular annotations organized at clip-level, event-level, and video-level segments.For efficient anomaly detection in long videos, we propose the Anomaly-focused Temporal Sampler (ATS). ATS integrates an anomaly scorer with a density-aware sampler to adaptively select frames based on anomaly scores, ensuring that the multimodal LLM concentrates on anomaly-rich regions, which significantly enhances both efficiency and accuracy.Extensive experiments demonstrate that our hierarchical instruction data markedly improves anomaly comprehension. The integrated ATS and visual-language model outperform traditional methods in processing long videos.Our benchmark and model will be publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce ``Humans and Structure from Motion'', a novel approach for reconstructing multiple people within a metric world coordinate system from a sparse set of images capturing a scene. Our method jointly estimates human body pose, shape, camera positions, and scene structure, capturing the spatial relationships among people and their location in the environment. Unlike existing methods that require calibrated setups, our approach operates with minimal constraints by leveraging the strength of both human body priors and data-driven SfM. By leveraging multi-view geometry, our method is the first work that effectively recovers humans and scene structure without assumptions about human-scene contact. We evaluate our approach on two challenging benchmarks, EgoHumans and EgoExo4D, demonstrating significant improvements in human location estimation within the world coordinate frame (3.51m to 1.04m and 2.9m to 0.56m respectively). Notably, our results also reveal that incorporating human data in the classical SfM task improves camera pose estimation (RRA@15: 0.74 to 0.89 in EgoHumans), when multiple humans are used for correspondence. We will release our code and data.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Spike cameras, as an innovative neuromorphic camera that captures scenes with the 0-1 bit stream at 40 kHz, are increasingly employed for the 3D reconstruction task via Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS). Previous spike-based 3D reconstruction approaches often employ a casecased pipeline: starting with high-quality image reconstruction from spike streams based on established spike-to-image reconstruction algorithms, then progressing to camera pose estimation and 3D reconstruction. However, this cascaded approach suffers from substantial cumulative errors, where quality limitations of initial image reconstructions negatively impact pose estimation, ultimately degrading the fidelity of the 3D reconstruction. To address these issues, we propose a synergistic optimization framework USP-Gaussian, that unifies spike-based image reconstruction, pose correction, and Gaussian splatting into an end-to-end framework. Leveraging the multi-view consistency afforded by 3DGS and the motion capture capability of the spike camera, our framework enables a joint iterative optimization that seamlessly integrates information between the spike-to-image network and 3DGS. Experiments on synthetic datasets with accurate poses demonstrate that our method surpasses previous approaches by effectively eliminating cascading errors. Moreover, we integrate pose optimization to achieve robust 3D reconstruction in real-world scenarios with inaccurate initial poses, outperforming alternative methods by effectively reducing noise and preserving …
|
|
Highlight
|
Poster
[ ExHall D ] 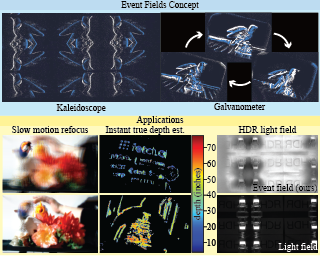
Abstract
Event cameras, which feature pixels that independently respond to changes in brightness, are becoming increasingly popular in high-speed applications due to their lower latency, reduced bandwidth requirements, and enhanced dynamic range compared to traditional frame-based cameras. Numerous imaging and vision techniques have leveraged event cameras for high-speed scene understanding by capturing high-framerate, high-dynamic range videos, primarily utilizing the temporal advantages inherent to event cameras. Additionally, imaging and vision techniques have utilized the light field---a complementary dimension to temporal information---for enhanced scene understanding. In this work, we propose "Event Fields", a new approach that utilizes innovative optical designs for event cameras to capture light fields at high speed. We develop the underlying mathematical framework for Event Fields and introduce two foundational frameworks to capture them practically: spatial multiplexing to capture temporal derivatives and temporal multiplexing to capture angular derivatives. To realize these, we design two complementary optical setups---one using a kaleidoscope for spatial multiplexing and another using a galvanometer for temporal multiplexing. We evaluate the performance of both designs using a custom-built simulator and real hardware prototypes, showcasing their distinct benefits. Our event fields unlock the full advantages of typical light fields—like post-capture refocusing and depth estimation—now supercharged for high-speed and …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Despite recent successes in novel view synthesis using 3D Gaussian Splatting (3DGS), modeling scenes with sparse inputs remains a challenge. In this work, we address two critical yet overlooked issues in real-world sparse-input modeling: extrapolation and occlusion. To tackle these issues, we propose to use a reconstruction by generation pipeline that leverages learned priors from video diffusion models to provide plausible interpretations for regions outside the field of view or occluded. However, the generated sequences exhibit inconsistencies that do not fully benefit subsequent 3DGS modeling. To address the challenge of inconsistency, we introduce a novel scene-grounding guidance based on rendered sequences from an optimized 3DGS, which tames the diffusion model to generate consistent sequences. This guidance is training-free and does not require any fine-tuning of the diffusion model. To facilitate holistic scene modeling, we also propose a trajectory initialization method. It effectively identifies regions that are outside the field of view and occluded. We further design a scheme tailored for 3DGS optimization with generated sequences. Experiments demonstrate that our method significantly improves upon the baseline and achieves state-of-the-art performance on challenging benchmarks.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
In recent years, the interpretability of Deep Neural Networks (DNNs) has garnered significant attention, particularly due to their widespread deployment in critical domains like healthcare, finance, and autonomous systems. To address the challenge of understanding how DNNs make decisions, Explainable AI (XAI) methods, such as saliency maps, have been developed to provide insights into the inner workings of these models. This paper introduces DiffCAM, a novel XAI method designed to overcome limitations in existing Class Activation Map (CAM)-based techniques, which often rely on decision boundary gradients to estimate feature importance. DiffCAM differentiates itself by considering the actual data distribution of the reference class, identifying feature importance based on how a target example differs from reference examples. This approach captures the most discriminative features without relying on decision boundaries or prediction results, making DiffCAM applicable to a broader range of models, including foundation models. Through extensive experiments, we demonstrate the superior performance and flexibility of DiffCAM in providing meaningful explanations across diverse datasets and scenarios.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Event-based cameras asynchronously detect changes in light intensity with high temporal resolution, making them a promising alternative to RGB camera for low-latency and low-power optical flow estimation. However, state-of-the-art convolutional neural network methods create frames from the event stream, therefore losing the opportunity to exploit events for both sparse computations and low-latency prediction. On the other hand, asynchronous event graph methods could leverage both, but at the cost of avoiding any form of time accumulation, which limits the prediction accuracy. In this paper, we propose to break this accuracy-latency trade-off with a novel architecture combining an asynchronous accumulation-free event branch and a periodic aggregation branch. The periodic branch performs feature aggregations on the event graphs of past data to extract global context information, which improves accuracy without introducing any latency.The solution could predict optical flow per event with a latency of tens of microseconds on asynchronous hardware, which represents a gain of three orders of magnitude with respect to state-of-the-art frame-based methods, with 48x less operations per second. We show that the solution can detect rapid motion changes faster than a periodic output. This work proposes, for the first time, an effective solution for ultra low-latency and low-power optical flow …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Contrastive Language-Image Pre-training (CLIP)~\citep{radford2021learning} has emerged as a pivotal model in computer vision and multimodal learning, achieving state-of-the-art performance at aligning visual and textual representations through contrastive learning.However, CLIP struggles with potential information misalignment in many image-text datasets and suffers from entangled representation. On the one hand, short captions for a single image in datasets like MSCOCO may describe disjoint regions in the image, leaving the model uncertain about which visual features to retain or disregard.On the other hand, directly aligning long captions with images can lead to the retention of entangled details, preventing the model from learning disentangled, atomic concepts -- ultimately limiting its generalization on certain downstream tasks involving short prompts.In this paper, we establish theoretical conditions that enable flexible alignment between textual and visual representations across varying levels of granularity. Specifically, our framework ensures that a model can not only \emph{preserve} cross-modal semantic information in its entirety but also \emph{disentangle} visual representations to capture fine-grained textual concepts. Building on this foundation, we introduce \ours, a novel approach that identifies and aligns the most relevant visual and textual representations in a modular manner. Superior performance across various tasks demonstrates its capability to handle information misalignment and supports our …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Sparse wearable inertial measurement units (IMUs) have gained popularity for estimating 3D human motion. However, challenges such as pose ambiguity, data drift, and limited adaptability to diverse bodies persist. To address these issues, we propose UMotion, an uncertainty-driven, online fusing-all state estimation framework for 3D human shape and pose estimation, supported by six integrated, body-worn ultra-wideband (UWB) distance sensors with IMUs. UWB sensors measure inter-node distances to infer spatial relationships, aiding in resolving pose ambiguities and body shape variations when combined with anthropometric data. Unfortunately, IMUs are prone to drift, and UWB sensors are affected by body occlusions. Consequently, we develop a tightly coupled Unscented Kalman Filter (UKF) framework that fuses uncertainties from sensor data and estimated human motion based on individual body shape. The UKF iteratively refines IMU and UWB measurements by aligning them with uncertain human motion constraints in real-time, producing optimal estimates for each. Experiments on both synthetic and real-world datasets demonstrate the effectiveness of UMotion in stabilizing sensor data and the improvement over state of the art in pose accuracy. The code will be available for research purposes.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
In real-world applications, deep neural networks may encounter constantly changing environments, where the test data originates from continually shifting unlabeled target domains. This problem, known as Unsupervised Continual Domain Shift Learning (UCDSL), poses practical difficulties. Existing methods for UCDSL aim to learn domain-invariant representations for all target domains. However, due to the existence of adaptivity gap, the invariant representation may theoretically lead to large joint errors. To overcome the limitation, we propose a novel UCDSL method, called Multi-Prototype Modeling (MPM). Our model comprises two key components: (1) Multi-Prototype Learning (MPL) for acquiring domain-specific representations using multiple domain-specific prototypes. MPL achieves domain-specific error minimization instead of enforcing feature alignment across different domains. (2) Bi-Level Graph Enhancer (BiGE) for enhancing domain-level and category-level representations, resulting in more accurate predictions. We provide theoretical and empirical analysis to demonstrate the effectiveness of our proposed method. We evaluate our approach on multiple benchmark datasets and show that our model surpasses state-of-the-art methods across all datasets, highlighting its effectiveness and robustness in handling unsupervised continual domain shift learning. Codes will be publicly accessible.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We introduce the first method for generating Vector Displacement Maps (VDMs): parameterized, detailed geometric stamps commonly used in 3D modeling. Given a single input image, our method first generates multi-view normal maps and then reconstructs a VDM from the normals via a novel reconstruction pipeline. We also propose an efficient algorithm for extracting VDMs from 3D objects, and present the first academic VDM dataset. Compared to existing 3D generative models focusing on complete shapes, we focus on generating parts that can be seamlessly attached to shape surfaces. The method gives artists rich control over adding geometric details to a 3D shape. Experiments demonstrate that our approach outperforms existing baselines. Generating VDMs offers additional benefits, such as using 2D image editing to customize and refine 3D details.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Problems in differentiable rendering often involve optimizing scene parameters that cause motion in image space. The gradients for such parameters tend to be sparse, leading to poor convergence. While existing methods address this sparsity through proxy gradients such as topological derivatives or lagrangian derivatives, they make simplifying assumptions about rendering. Multi-resolution image pyramids offer an alternative approach but prove unreliable in practice. We introduce a method that uses locally orderless images --- where each pixel maps to a histogram of intensities that preserves local variations in appearance. Using an inverse rendering objective that minimizes histogram distance, our method extends support for sparsely defined image gradients and recovers optimal parameters. We validate our method on various inverse problems using both synthetic and real data.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Generative Adversarial Networks (GANs) have emerged as powerful tools for high-quality image generation and real image editing by manipulating their latent spaces. Recent advancements in GANs include 3D-aware models such as EG3D, which feature efficient triplane-based architectures capable of reconstructing 3D geometry from single images. However, limited attention has been given to providing an integrated framework for 3D-aware, high-quality, reference-based image editing. This study addresses this gap by exploring and demonstrating the effectiveness of the triplane space for advanced reference-based edits. Our novel approach integrates encoding, automatic localization, spatial disentanglement of triplane features, and fusion learning to achieve the desired edits. Additionally, our framework demonstrates versatility and robustness across various domains, extending its effectiveness to animal face edits, partially stylized edits like cartoon faces, full-body clothing edits, and 360-degree head edits. Our method shows state-of-the-art performance over relevant latent direction, text, and image-guided 2D and 3D-aware diffusion and GAN methods, both qualitatively and quantitatively.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Recent improvements in visual synthesis have significantly enhanced the depiction of generated human photos, which are pivotal due to their wide applicability and demand. Nonetheless, the existing text-to-image or text-to-video models often generate low-quality human photos that might differ considerably from real-world body structures, referred to as ``abnormal human bodies''. Such abnormalities, typically deemed unacceptable, pose considerable challenges in the detection and repair of them within human photos. These challenges require precise abnormality recognition capabilities, which entail pinpointing both the location and the abnormality type. Intuitively, Visual Language Models (VLMs) that have obtained remarkable performance on various visual tasks are quite suitable for this task. However, their performance on abnormality detection in human photos is quite poor.Hence, it is quite important to highlight this task for the research community. In this paper, we first introduce a simple yet challenging task, i.e., \textbf{F}ine-grained \textbf{H}uman-body \textbf{A}bnormality \textbf{D}etection \textbf{(FHAD)}, and construct two high-quality datasets for evaluation. Then, we propose a meticulous framework, named HumanCalibrator, which identifies and repairs abnormalities in human body structures while preserving the other content. Experiments indicate that our HumanCalibrator achieves high accuracy in abnormality detection and accomplishes an increase in visual comparisons while preserving the other visual content.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Video restoration poses non-trivial challenges in maintaining fidelity while recovering temporally consistent details from unknown degradations in the wild. Despite recent advances in diffusion-based restoration, these methods often face limitations in generation capability and sampling efficiency. In this work, we present $\text{SeedVR}$, a diffusion transformer designed to handle real-world video restoration with arbitrary length and resolution. The core design of SeedVR lies in the shifted window attention that facilitates effective restoration on long video sequences. SeedVR further supports variable-sized windows near the boundary of both spatial and temporal dimensions, overcoming the resolution constraints of traditional window attention. Equipped with contemporary practices, including causal video autoencoder, mixed image and video training, and progressive training, SeedVR achieves highly-competitive performance on both synthetic and real-world benchmarks, as well as AI-generated videos. Extensive experiments demonstrate SeedVR's superiority over existing methods for generic video restoration.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
A dexterous hand capable of grasping any object is essential for the development of general-purpose embodied intelligent robots. However, due to the high degree of freedom in dexterous hands and the vast diversity of objects, generating high-quality, usable grasping poses in a robust manner is a significant challenge. In this paper, we introduce DexGrasp Anything, a method that effectively integrates physical constraints into both the training and sampling phases of a diffusion-based generative model, achieving state-of-the-art performance across nearly all open datasets. Additionally, we present a new dexterous grasping dataset containing over 3.4 million diverse grasping poses for more than 15k different objects, demonstrating its potential to advance universal dexterous grasping. The code of our method and our dataset will be publicly released soon.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We present EgoAllo, a system for human motion estimation from a head-mounted device. Using only egocentric SLAM poses and images, EgoAllo guides sampling from a conditional diffusion model to estimate 3D body pose, height, and hand parameters that capture a device wearer's actions in the allocentric coordinate frame of the scene. To achieve this, our key insight is in representation: we propose spatial and temporal invariance criteria for improving model performance, from which we derive a head motion conditioning parameterization that improves estimation by up to 18%. We also show how the bodies estimated by our system can improve hand estimation: the resulting kinematic and temporal constraints can reduce world-frame errors in single-frame estimates by 40%.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Existing object detection methods often consider sRGB input, which was compressed from RAW data using ISP originally designed for visualization. However, such compression might lose crucial information for detection, especially under complex light and weather conditions. We introduce the AODRaw dataset, which offers 7,785 high-resolution real RAW images with 135,601 annotated instances spanning 62 categories, capturing a broad range of indoor and outdoor scenes under 9 distinct light and weather conditions. Based on AODRaw that supports RAW and sRGB object detection, we provide a comprehensive benchmark for evaluating current detection methods. We find that sRGB pre-training constrains the potential of RAW object detection due to the domain gap between sRGB and RAW, prompting us to directly pre-train on the RAW domain. However, it is harder for RAW pre-training to learn rich representations than sRGB pre-training due to the camera noise. To assist RAW pre-training, we distill the knowledge from an off-the-shelf model pre-trained on the sRGB domain. As a result, we achieve substantial improvements under diverse and adverse conditions without relying on extra pre-processing modules. The code and dataset will be made publicly available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Many works have succeeded in reconstructing Gaussian human avatars from multi-view videos. However, they either struggle to capture pose-dependent appearance details with a single MLP, or rely on a computationally intensive neural network to reconstruct high-fidelity appearance but with rendering performance degraded to non-real-time. We propose a novel Gaussian human avatar representation that can reconstruct high-fidelity pose-dependence appearance with details and meanwhile can be rendered in real time. Our Gaussian avatar is empowered by spatially distributed MLPs which are explicitly located on different positions on human body. The parameters stored in each Gaussian are obtained by interpolating from the outputs of its nearby MLPs based on their distances. To avoid undesired smooth Gaussian property changing during interpolation, for each Gaussian we define a set of Gaussian offset basis, and a linear combination of basis represents the Gaussian property offsets relative to the neutral properties. Then we propose to let the MLPs output a set of coefficients corresponding to the basis. In this way, although Gaussian coefficients are derived from interpolation and change smoothly, the Gaussian offset basis is learned freely without constraints. The smoothly varying coefficients combined with freely learned basis can still produce distinctly different Gaussian property offsets, allowing …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The inherent ambiguity in the definition of visual concepts poses significant challenges for modern generative models, like the Text-to-Image (T2I) models based on diffusion models, in accurately learning concepts from the input images. Existing methods lack a systematic framework and interpretative mechanisms, hindering reliable extraction of the underlying intrinsic concepts. To address this challenge, we present ICE, short for Intrinsic Concept Extraction, a novel framework to automatically and systematically extract intrinsic concepts from a single image leveraging a T2I model. ICE consists of two pivotal stages. In the first stage, ICE devises an automatic concept localization module that pinpoints relevant text-based concepts and their corresponding masks within a given image. This critical phase not only streamlines concept initialization but also offers precise guidance for the subsequent analysis. The second stage delves deeper into each identified mask, decomposing concepts into intrinsic components, capturing specific visual characteristics and general components representing broader categories. This decomposition facilitates a more granular understanding by further dissecting concepts into detailed intrinsic attributes such as colour and material. Extensive experiments validate that ICE achieves superior performance on intrinsic concept extraction, enabling reliable and flexible application to downstream tasks like personalized image generation, image editing, and so on. …
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
The zero-shot capabilities of Vision-Language Models (VLMs) have been widely leveraged to improve predictive performance. However, previous works on transductive or test-time adaptation (TTA) often make strong assumptions about the data distribution, such as the presence of all classes. Our work challenges these favorable deployment scenarios, and introduces a more realistic evaluation framework, including: (i) a variable number of effective classes for adaptation within a single batch, and (ii) non-i.i.d. batches of test samples in online adaptation settings. We provide comprehensive evaluations, comparisons, and ablation studies that demonstrate how current transductive or TTA methods for VLMs systematically compromise the models’ initial zero-shot robustness across various realistic scenarios, favoring performance gains under advantageous assumptions about the test samples' distributions. Furthermore, we introduce Stat${\cal A}$, a versatile method that could handle a wide range of deployment scenarios, including those with a variable number of effective classes at test time. Our approach incorporates a novel regularization term designed specifically for VLMs, which acts as a statistical anchor preserving the initial text-encoder knowledge, particularly in low-data regimes. Code will be made available.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Text-guided image manipulation has experienced notable advancement in recent years. In order to mitigate linguistic ambiguity, few-shot learning with visual examples has been applied for instructions that are underrepresented in the training set, or difficult to describe purely in language. However, learning from visual prompts requires strong reasoning capability, which diffusion models are struggling with. To address this issue, we introduce a novel multi-modal autoregressive model, dubbed InstaManip, that can instantly learn a new image manipulation operation from textual and visual guidance via in-context learning, and apply it to new query images. Specifically, we propose an innovative group self-attention mechanism to break down the in-context learning process into two separate stages -- learning and applying, which simplifies the complex problem into two easier tasks. We also introduce a relation regularization method to further disentangle image transformation features from irrelevant contents in exemplar images. Extensive experiments suggest that our method surpasses previous few-shot image manipulation models by a notable margin (>=19% in human evaluation). We also find our model can be further boosted by increasing the number or diversity of exemplar images.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Referring Video Object Segmentation (RVOS) relies on natural language expressions to segment an object in a video clip.Existing methods restrict reasoning either to independent short clips, losing global context, or process the entire video offline, impairing their application in a streaming fashion. In this work, we aim to surpass these limitations and design an RVOS method capable of effectively operating in streaming-like scenarios while retaining contextual information from past frames. We build upon the Segment-Anything 2 (SAM2) model, that provides robust segmentation and tracking capabilities and is naturally suited for streaming processing. We make SAM2 wiser, by empowering it with natural language understanding and explicit temporal modeling at the feature extraction stage, without fine-tuning its weights, and without outsourcing modality interaction to external models. To this end, we introduce a novel adapter module that injects temporal information and multi-modal cues in the feature extraction process. We further reveal the phenomenon of tracking bias in SAM2 and propose a learnable module to adjust its tracking focus when the current frame features suggest a new object more aligned with the caption. Our proposed method, \ours, achieves state-of-the-art across various benchmarks, by adding a negligible overhead of just 4.2 M parameters.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Many machine learning (ML) classifiers are claimed to outperform humans, but they still make mistakes that humans do not. The most notorious examples of such mistakes are adversarial visual metamers. This paper aims to define and investigate the phenomenon of adversarial Doppelgängers (AD), which includes adversarial visual metamers, and to compare the performance and robustness of ML classifiers to human performance.We find that AD are inputs that are close to each other with respect to a perceptual metric defined in this paper, and show that AD are qualitatively different from the usual adversarial examples. The vast majority of classifiers are vulnerable to AD and robustness-accuracy trade-offs may not improve them. Some classification problems may not admit any AD robust classifiers because the underlying classes are ambiguous. We provide criteria that can be used to determine whether a classification problem is well defined or not; describe of an AD robust classifiers’ structure and attributes; introduce and explore the notions of conceptual entropy and regions of conceptual ambiguity for classifiers that are vulnerable to AD attacks, along with methods to bound the AD fooling rate of an attack. We define the notion of classifiers that exhibit hyper-sensitive behavior, that is, classifiers whose …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
Modern deep neural networks have now reached human-level performance across a variety of tasks. However, unlike humans they lack the ability to explain their decisions by showing where and telling what concepts guided them. In this work, we present a unified framework for transforming any vision neural network into a spatially and conceptually interpretable model. We introduce a spatially-aware concept bottleneck layer that projects “black-box” features of pre-trained backbone models into interpretable concept maps, without requiring human labels. By training a classification layer over this bottleneck, we obtain a self-explaining model that articulates which concepts most influenced its prediction, along with heatmaps that ground them in the input image. Accordingly, we name this method “Spatially-Aware and Label-Free Concept Bottleneck Model” (SALF-CBM). Our results show that the proposed SALF-CBM: (1) Outperforms non-spatial CBM methods, as well as the original backbone, on a variety of classification tasks; (2) Produces high-quality spatial explanations, outperforming widely used heatmap-based methods on a zero-shot segmentation task; (3) Facilitates model exploration and debugging, enabling users to query specific image regions and refine the model's decisions by locally editing its concept maps.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Learning to use tools or objects in common scenes, particularly handling them in various ways as instructed, is a key challenge for developing interactive robots. Training models to generate such manipulation trajectories requires a large and diverse collection of detailed manipulation demonstrations for various objects, which is nearly unfeasible to gather at scale. In this paper, we propose a framework that leverages large-scale ego- and exo-centric video datasets --- constructed globally with substantial effort --- of Exo-Ego4D to extract diverse manipulation trajectories at scale. From these extracted trajectories with the associated textual action description, we develop trajectory generation models based on visual and point cloud-based language models. In the recently proposed egocentric vision-based in-a-quality trajectory dataset of HOT3D, we confirmed that our models successfully generate valid object trajectories, establishing a training dataset and baseline models for the novel task of generating 6DoF manipulation trajectories from action descriptions in egocentric vision. Our dataset and code is available upon acceptance.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
We propose a novel unsupervised cross-modal homography estimation learning framework, named Split Supervised Homography estimation Network (SSHNet). SSHNet redefines the unsupervised cross-modal homography estimation into two supervised sub-problems, each addressed by its specialized network: a homography estimation network and a modality transfer network. To realize stable training, we introduce an effective split optimization strategy to train each network separately within its respective sub-problem. We also formulate an extra homography feature space supervision to enhance feature consistency, further boosting the estimation accuracy. Moreover, we employ a simple yet effective distillation training technique to reduce model parameters and improve cross-domain generalization ability while maintaining comparable performance. The training stability of SSHNet enables its cooperation with various homography estimation architectures. Experiments reveal that the SSHNet using IHN as homography estimation network, namely SSHNet-IHN, outperforms previous unsupervised approaches by a significant margin. Even compared to supervised approaches MHN and LocalTrans, SSHNet-IHN achieves 47.4\% and 85.8\% mean average corner errors (MACEs) reduction on the challenging OPT-SAR dataset. The source code is provided in the supplementary material.
|
|
Highlight
|
Poster
[ ExHall D ] 
Abstract
Image-to-point cloud registration aims to estimate the camera pose of a given image within a 3D scene point cloud. In this area, matching-based methods have achieved leading performance by first detecting the overlapping region, then matching point and pixel features learned by neural networks and finally using the PnP-RANSAC algorithm to estimate camera pose. However, achieving accurate image-to-point cloud registration remains challenging because the overlapping region detection is unreliable merely relying on point-wise classification, direct alignment of cross-modal data is difficult and indirect optimization objective leads to unstable registration results. To address these challenges, we propose a novel implicit correspondence learning method, including a Geometric Prior-guided overlapping region Detection Module (GPDM), an Implicit Correspondence Learning Module (ICLM), and a Pose Regression Module (PRM). The proposed method enjoys several merits. First, the proposed GPDM can precisely detect the overlapping region. Second, the ICLM can generate robust cross-modality correspondences. Third, the PRM can enable end-to-end optimization. Extensive experimental results on KITTI and nuScenes datasets demonstrate that the proposed model sets a new state-of-the-art performance in registration accuracy.
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
We introduce Digital Twin Catalog (DTC), a new large-scale photorealistic 3D object digital twin dataset. A digital twin of a 3D object is a highly detailed, virtually indistinguishable representation of a physical object, accurately capturing its shape, appearance, physical properties, and other attributes. Recent advances in neural-based 3D reconstruction and inverse rendering have significantly improved the quality of 3D object reconstruction. Despite these advancements, there remains a lack of a large-scale, digital twin quality real-world dataset and benchmark that can quantitatively assess and compare the performance of different reconstruction methods, as well as improve reconstruction quality through training or fine-tuning. Moreover, to democratize 3D digital twin creation, it is essential to integrate creation techniques with next-generation egocentric computing platforms, such as AR glasses. Currently, there is no dataset available to evaluate 3D object reconstruction using egocentric captured images. To address these gaps, the DTC dataset features 2,000 scanned digital twin-quality 3D objects, along with image sequences captured under different lighting conditions using DSLR cameras and egocentric AR glasses. This dataset establishes the first comprehensive real-world evaluation benchmark for 3D digital twin creation tasks, offering a robust foundation for comparing and improving existing reconstruction methods. We will make the full dataset …
|
|
Highlight
|
Poster
[ ExHall D ] Abstract
High-resolution perception of visual details is crucial for daily tasks. Current vision pre-training, however, is still limited to low resolutions (e.g., 384x384) due to the quadratic cost of processing larger images. We introduce PS3, for Pre-training with Scale-Selective Scaling, that scales CLIP-style vision pre-training to 4K resolution with a near-constant cost. Instead of processing entire global images, PS3 is pre-trained to selectively process local regions and contrast them with local detailed captions, allowing it to learn detailed representation at high resolution with greatly reduced computational overhead. The pre-trained PS3 is able to both encode the global low-resolution image and select local high-resolution regions to process based on their saliency or relevance to a text prompt. When applied to multi-modal LLMs (MLLMs), PS3 demonstrates performance that effectively scales with the pre-training resolution and significantly improves over baselines without high-resolution pre-training. We also find current benchmarks do not require recognizing details at 4K resolution, which motivates us to propose 4KPro, a new benchmark that evaluates visual perception at 4K resolution, on which PS3 outperforms state-of-the-art MLLMs, including a 13% improvement over GPT-4o.
|
|
Highlight
|
Poster
[ ExHall D ] 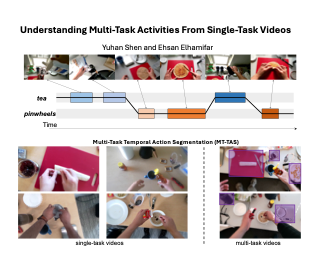
Abstract
We introduce and develop a framework for Multi-Task Temporal Action Segmentation (MT-TAS), a novel paradigm that addresses the challenges of interleaved actions when performing multiple tasks simultaneously. Traditional action segmentation models, trained on single-task videos, struggle to handle task switches and complex scenes inherent in multi-task scenarios. To overcome these challenges, our MT-TAS approach synthesizes multi-task video data from single-task sources using our Multi-task Sequence Blending and Segment Boundary Learning modules. Additionally, we propose to dynamically isolate foreground and background elements within video frames, addressing the intricacies of object layouts in multi-task scenarios and enabling a new two-stage temporal action segmentation framework with Foreground-Aware Action Refinement. Also, we introduce the Multi-task Egocentric Kitchen Activities (MEKA) dataset, containing 12 hours of egocentric multi-task videos, to rigorously benchmark MT-TAS models. Extensive experiments demonstrate that our framework effectively bridges the gap between single-task training and multi-task testing, advancing temporal action segmentation with state-of-the-art performance in complex environments.
|
|
Highlight
|
Poster
[ ExHall D ] 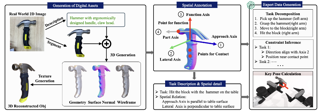
Abstract
In the rapidly advancing field of robotics, dual-arm coordination and complex object manipulation are essential capabilities for developing advanced autonomous systems. However, the scarcity of diverse, high-quality demonstration data and real-world-aligned evaluation benchmarks severely limits such development. To address this, we introduce RoboTwin, a generative digital twin framework that uses 3D generative foundation models and large language models to produce diverse expert datasets and provide a real-world-aligned evaluation platform for dual-arm robotic tasks. Specifically, RoboTwin creates varied digital twins of objects from single 2D images, generating realistic and interactive scenarios. It also introduces a spatial relation-aware code generation framework that combines object annotations with large language models to break down tasks, determine spatial constraints, and generate precise robotic movement code. Our framework offers a comprehensive benchmark with both simulated and real-world data, enabling standardized evaluation and better alignment between simulated training and real-world performance. We validated our approach using the open-source COBOT Magic Robot platform. Policies pre-trained on RoboTwin-generated data and fine-tuned with limited real-world samples improve the success rate of over 70\% for single-arm tasks and over 40\% for dual-arm tasks compared to models trained solely on real-world data. This significant improvement demonstrates RoboTwin's potential to enhance the development …
|