Improving Visual and Downstream Performance of Low-Light Enhancer with Vision Foundation Models Collaboration
{kind=link}
Abstract
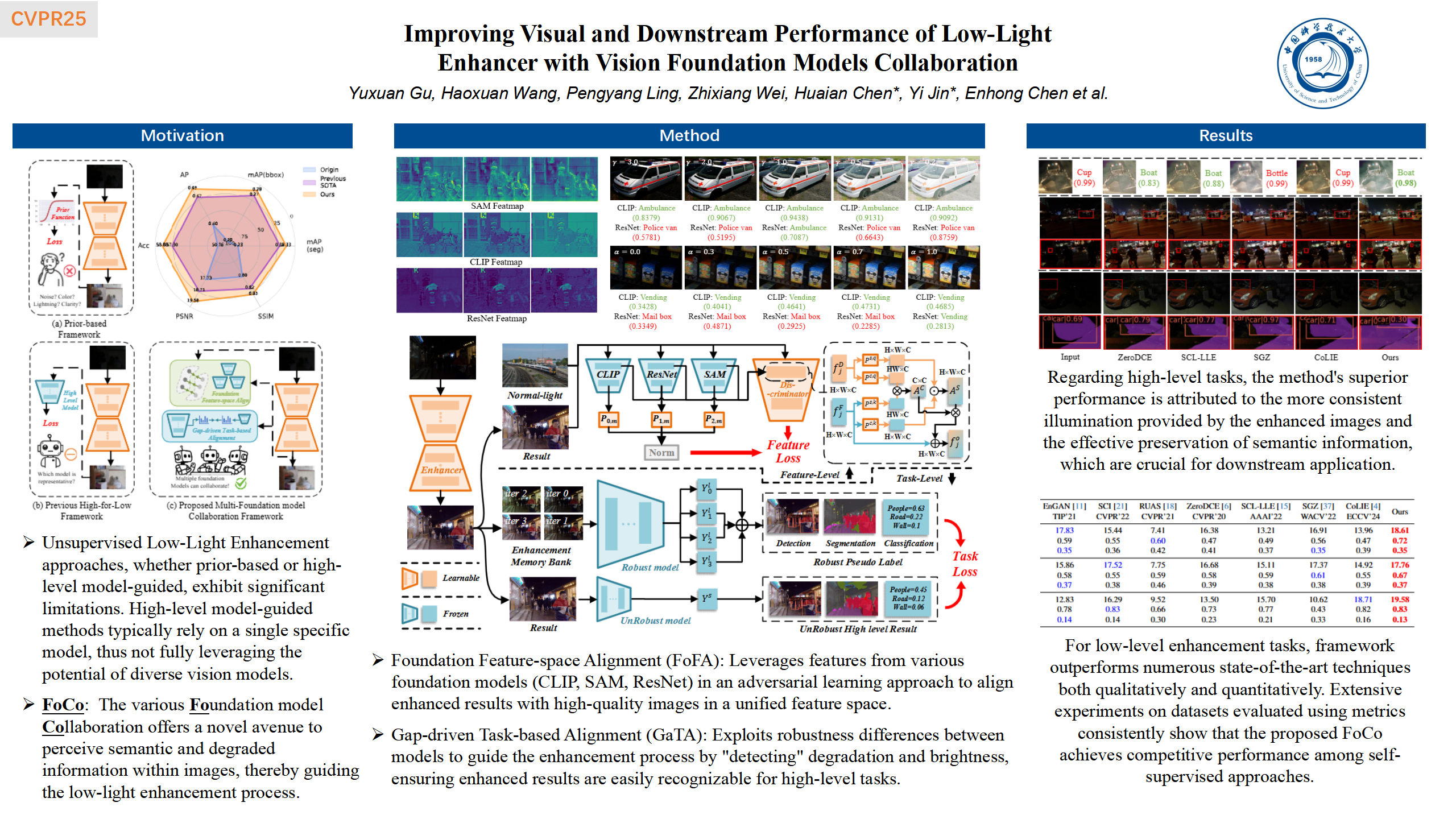
In this paper, we observe that the collaboration of various foundation models can perceive semantic and degraded information within images, thereby guiding the low-light enhancement process. Specifically, we propose a self-supervised low-light enhancement framework based on the multiple foundation models collaboration (dubbed FoCo), aimed at improving both the visual quality of enhanced images and the performance in high-level applications. At the feature level, FoCo leverages the rich features from various foundation models to enhance the model's semantic perception during training, thereby reducing the gap between enhanced results and high-quality images from a high-level perspective. At the task level, we exploit the robustness-gap between strong foundation models and weak models, applying high-level task guidance to the low-light enhancement training process. Through the collaboration of multiple foundation models, the proposed framework shows better enhancement performance and adapts better to high-level tasks. Extensive experiments across various enhancement and application benchmarks demonstrate the qualitative and quantitative superiority of the proposed method over numerous state-of-the-art techniques.