MaSS13K: A Matting-level Semantic Segmentation Benchmark
{kind=link}
Abstract
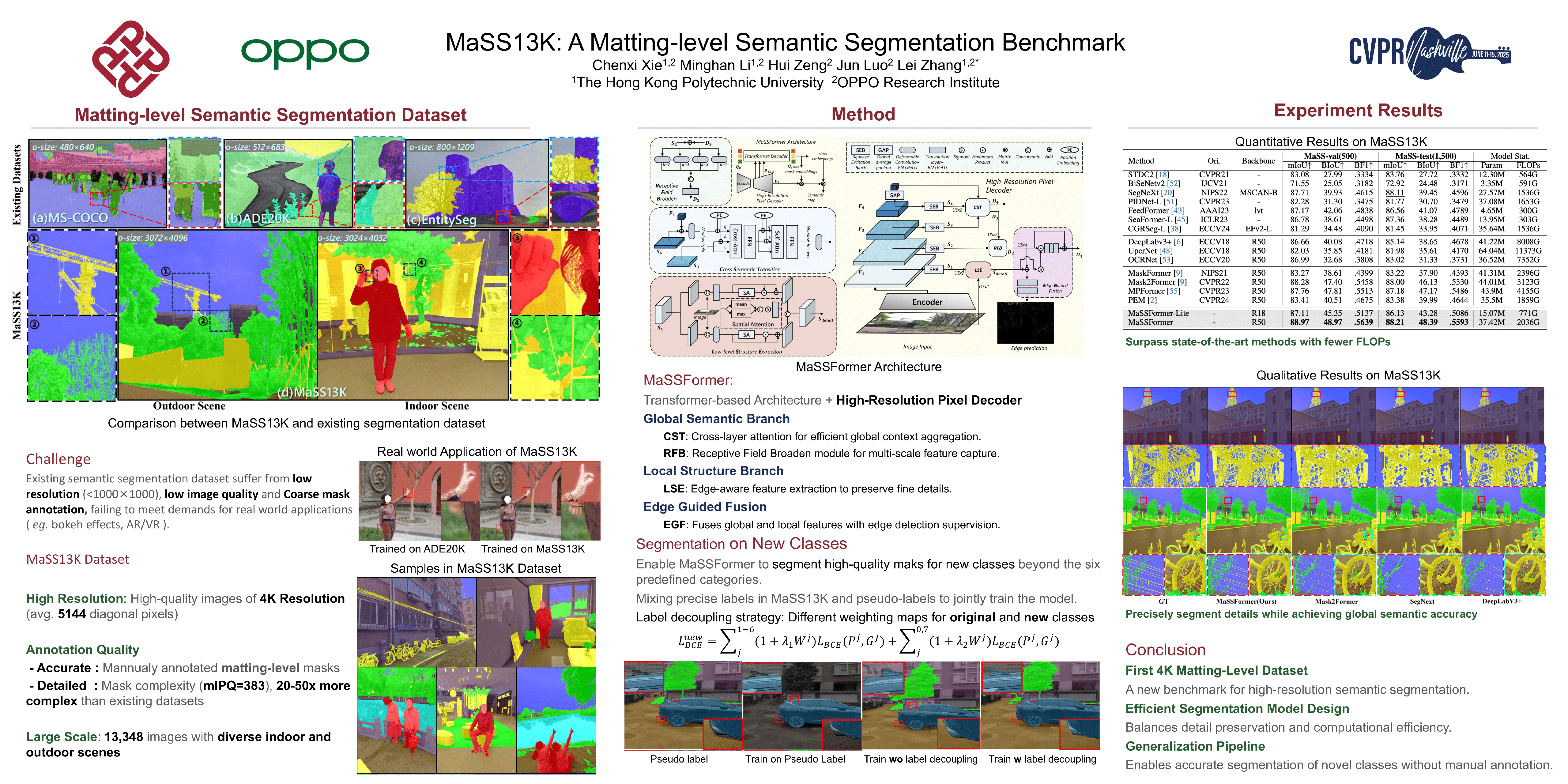
High-resolution semantic segmentation is essential for applications like image editing, bokeh imaging, and AR/VR, etc. Unfortunately, existing datasets often have limited resolution and lack precise mask details and boundaries. In this work, we build a large-scale, matting-level semantic segmentation dataset, named MaSS13K, which consists of 13,348 real-world images, all at 4K resolution. MaSS13K provides high-quality mask annotations of a number of objects, which are categorized into seven categories: human, vegetation, ground, sky, water, building, and others. MaSS13K features with precise masks, with an average mask complexity 20-50 times higher than existing semantic segmentation datasets. We consequently present a method specifically designed for high-resolution semantic segmentation, namely MaSSFormer, which employs an efficient pixel decoder that aggregates high-level semantic features and low-level texture features across three stages, aiming to produce high-resolution masks with minimal computational cost. Finally, we propose a new learning paradigm, which integrates the high-quality masks of the seven given categories with pseudo labels form new classes, enabling MaSSFormer to transfer its accurate segmentation capability to other classes of objects. Our proposed MaSSFormer is comprehensively evaluated on the MaSS13K benchmark together with 14 representative segmentation models. We expect that our meticulously annotated MaSS13K dataset and the MaSSFormer model can facilitate the research of high-resolution and high-quality semantic segmentation. Datasets and codes will be released.