Logits DeConfusion with CLIP for Few-Shot Learning
{kind=link}
Abstract
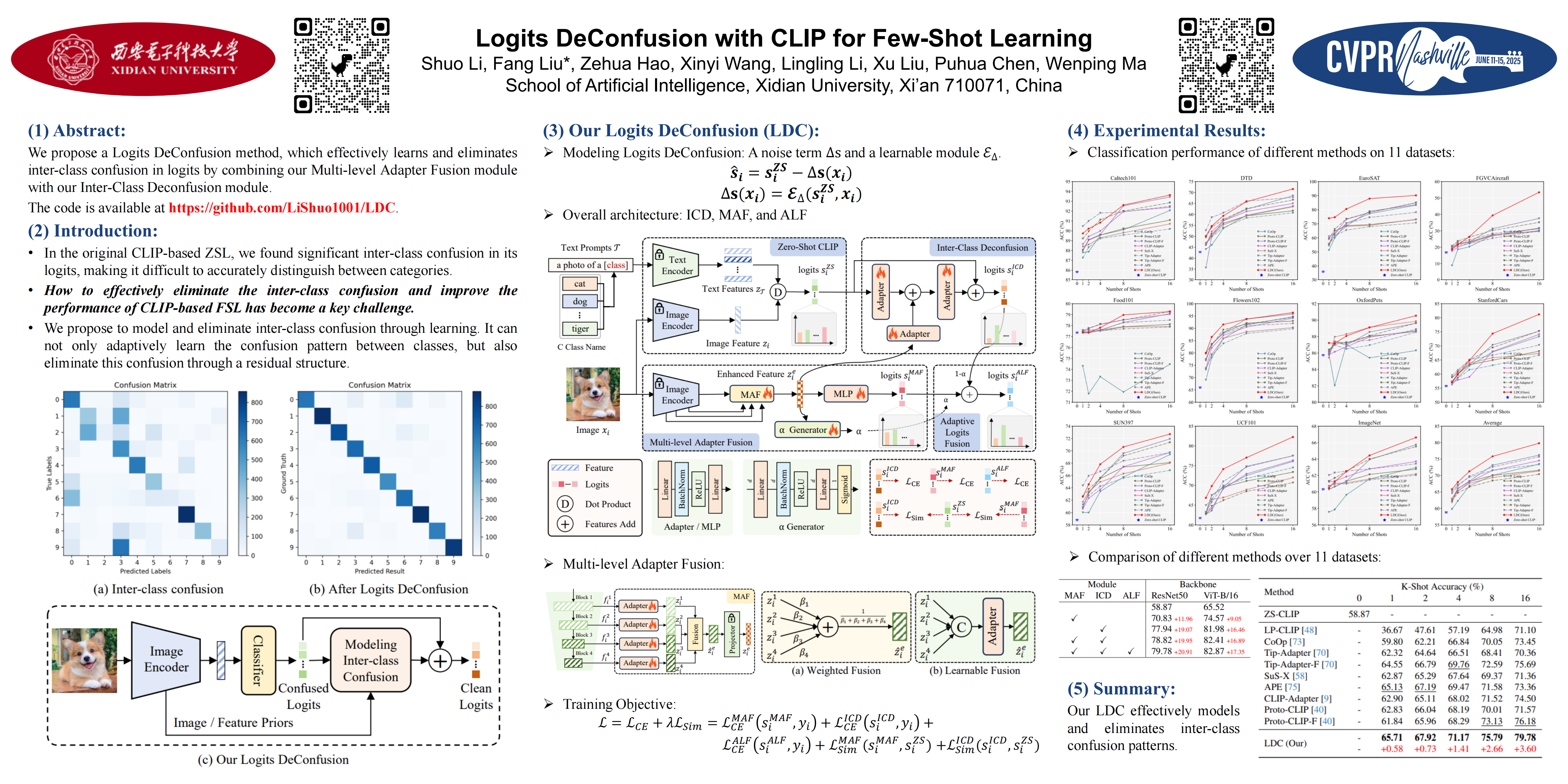
With its powerful visual-language alignment capability, CLIP performs well in zero-shot and few-shot learning tasks. However, we found in experiments that CLIP's logits suffer from serious inter-class confusion problems in downstream tasks, and the ambiguity between categories seriously affects the accuracy. To address this challenge, we propose a novel method called Logits DeConfusion, which effectively learns and eliminates inter-class confusion in logits by combining our Multi-level Adapter Fusion (MAF) module with our Inter-Class Deconfusion (ICD) module. First, MAF extracts features from different levels of the CLIP image encoder and fuses them uniformly to enhance feature representation. Second, ICD learnably eliminates inter-class confusion in logits with a residual structure. Experimental results on multiple benchmarks show that our method can significantly improve the classification performance and alleviate the category confusion problem.