Argus: A Compact and Versatile Foundation Model for Vision
{kind=link}
Abstract
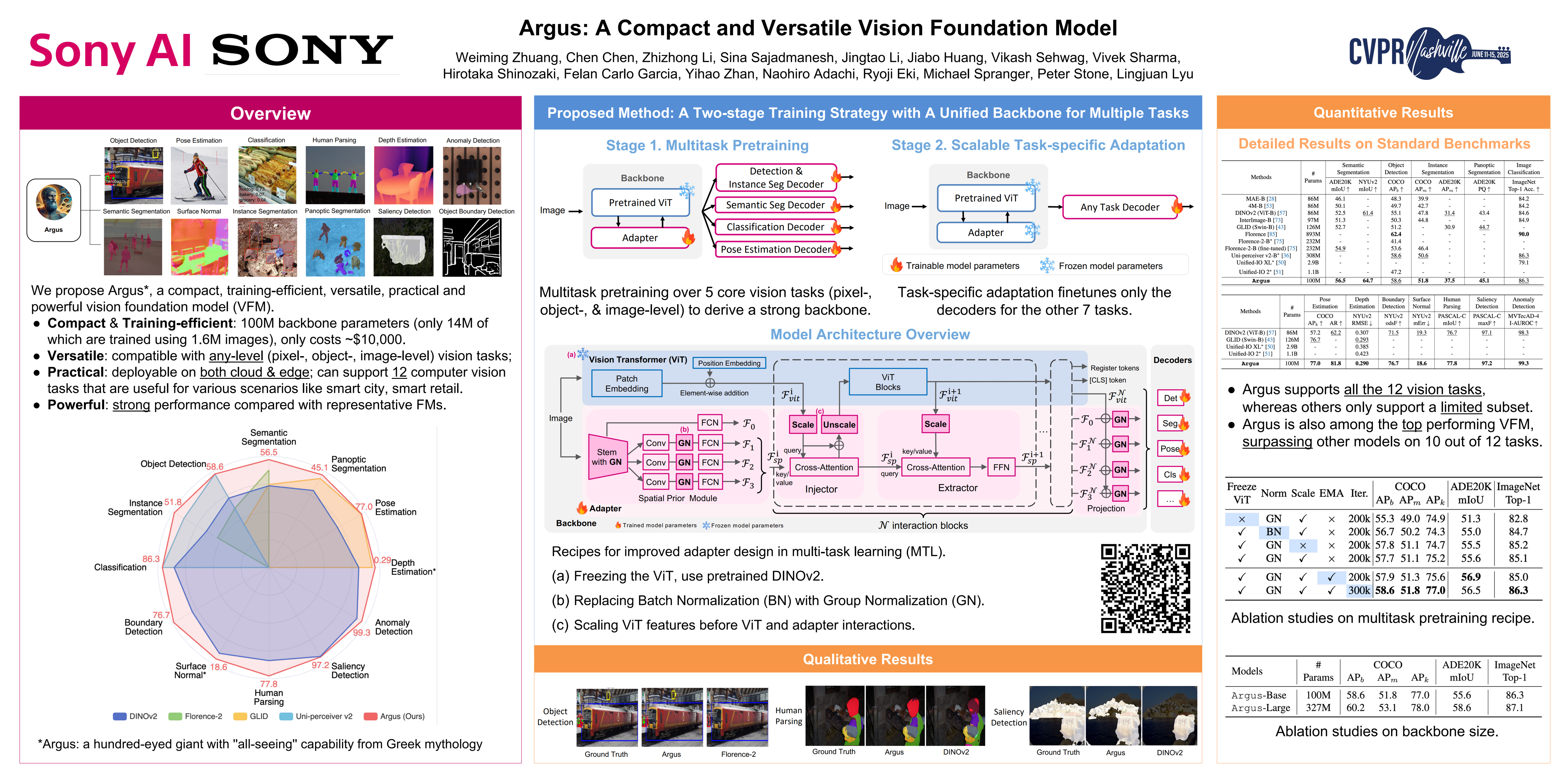
While existing vision and multi-modal foundation models can handle multiple computer vision tasks, they often suffer from significant limitations, including huge demand for data and computational resources during training and inconsistent performance across vision tasks at deployment time. To address these challenges, we introduce Argus (The name comes from Argus Panoptes--a hundred-eyed giant with ''all-seeing'' capability in Greek mythology), a compact and versatile vision foundation model designed to support a wide range of vision tasks through a unified multitask architecture. Argus employs a two-stage training strategy: (i) multitask pretraining over core vision tasks with a shared backbone that includes a lightweight adapter to inject task-specific inductive biases, and (ii) scalable and efficient adaptation to new tasks by fine-tuning only the task-specific decoders. Extensive evaluations demonstrate that Argus, despite its relatively compact and training-efficient design of merely 100M backbone parameters (only 13.6\% of which are trained using 1.6M images), competes with and even surpasses much larger models. Compared to state-of-the-art foundation models, Argus not only covers a broader set of vision tasks but also matches or outperforms the models with similar sizes on 12 tasks. We expect that Argus will accelerate the real-world adoption of vision foundation models in resource-constrained scenarios.