Towards Efficient Foundation Model for Zero-shot Amodal Segmentation
{kind=link}
Abstract
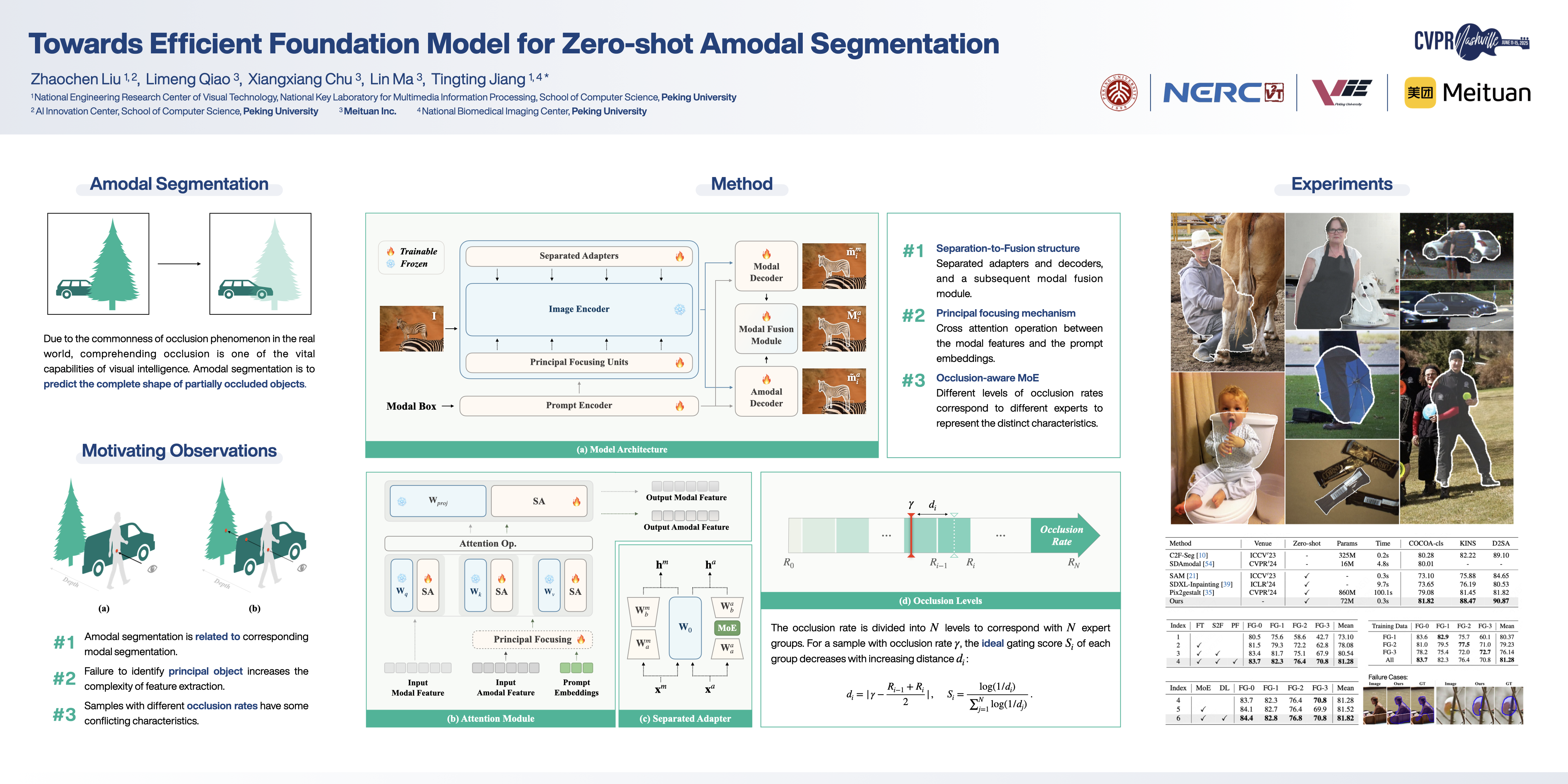
Aiming to predict the complete shape of partially occluded objects, amodal segmentation is an important capacity towards visual intelligence. In order to promote the practicability, zero-shot foundation model competent for the open world gains growing attention in this field. Nevertheless, prior models exhibit deficiencies in efficiency and stability. To address this problem, utilizing the implicit prior knowledge, we propose the first SAM-based amodal segmentation foundation model, SAMBA. Methodologically, a novel framework with multilevel facilitation is designed to better adapt the task characteristics and unleash the potential capabilities of SAM. In the modality level, a separation-to-fusion structure is employed that jointly learns modal and amodal segmentation to enhance mutual coordination. In the instance level, to ease the complexity of amodal feature extraction, we introduce a principal focusing mechanism to indicate objects of interest. In the pixel level, mixture-of-experts is incorporated with a specialized distribution loss, by which distinct occlusion rates correspond to different experts to improve the accuracy. Experiments are conducted on several eminent datasets, and the results show that the performance of SAMBA is superior to existing zero-shot and even supervised approaches. Furthermore, our proposed model has notable advantages in terms of speed and size. The model and code will be made publicly available.