SAIST: Segment Any Infrared Small Target Model Guided by Contrastive Language-Image Pretraining
{kind=link}
Abstract
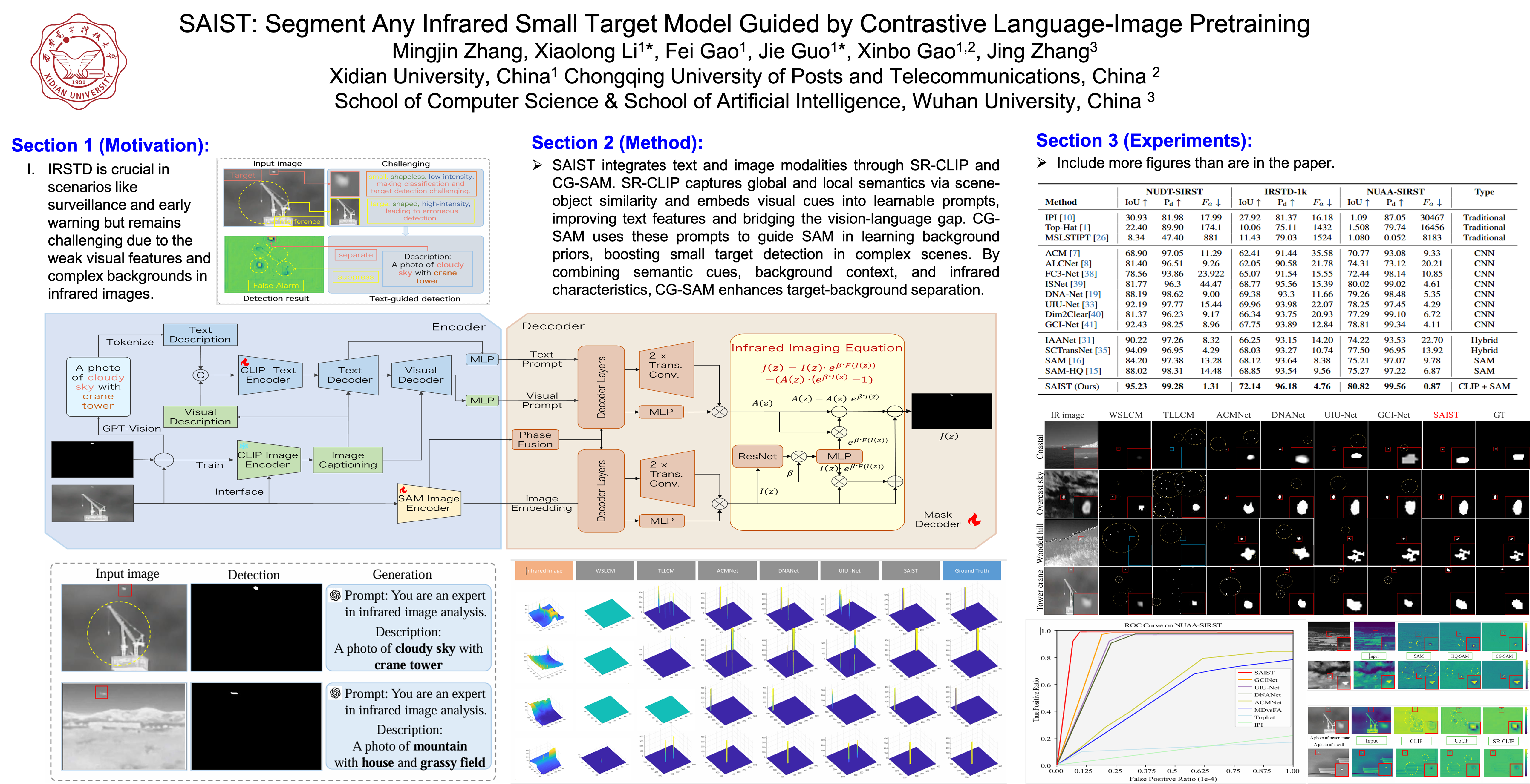
Infrared Small Target Detection (IRSTD) aims to identify low signal-to-noise ratio small targets in infrared images with complex backgrounds, which is crucial for various applications. However, existing IRSTD methods typically rely solely on image modalities for processing, which fail to fully capture contextual information, leading to limited detection accuracy and adaptability in complex environments. Inspired by vision-language models, this paper proposes a novel framework, SAIST, which integrates textual information with image modalities to enhance IRSTD performance. The framework consists of two main components: Scene Recognition Contrastive Language-Image Pretraining (SR-CLIP) and CLIP-guided Segment Anything Model (CG-SAM). SR-CLIP generates a set of visual descriptions through object-object similarity and object-scene relevance, embedding them into learnable prompts to refine the textual description set. This reduces the domain gap between vision and language, generating precise textual and visual prompts. CG-SAM utilizes the prompts generated by SR-CLIP to accurately guide the Mask Decoder in learning prior knowledge of background features, while incorporating infrared imaging equations to improve small target recognition in complex backgrounds and significantly reduce the false alarm rate. Additionally, this paper introduces the first multimodal IRSTD dataset, MIRSTD, which contains abundant image-text pairs. Experimental results demonstrate that the proposed SAIST method outperforms existing state-of-the-art approaches. The dataset and code will be made publicly available.