Navigating the Unseen: Zero-shot Scene Graph Generation via Capsule-Based Equivariant Features
Wenhuan Huang ⋅ Yi JI ⋅ guiqian zhu ⋅ Ying Li ⋅ chunping Liu
2025 Poster
{kind=link}
Abstract
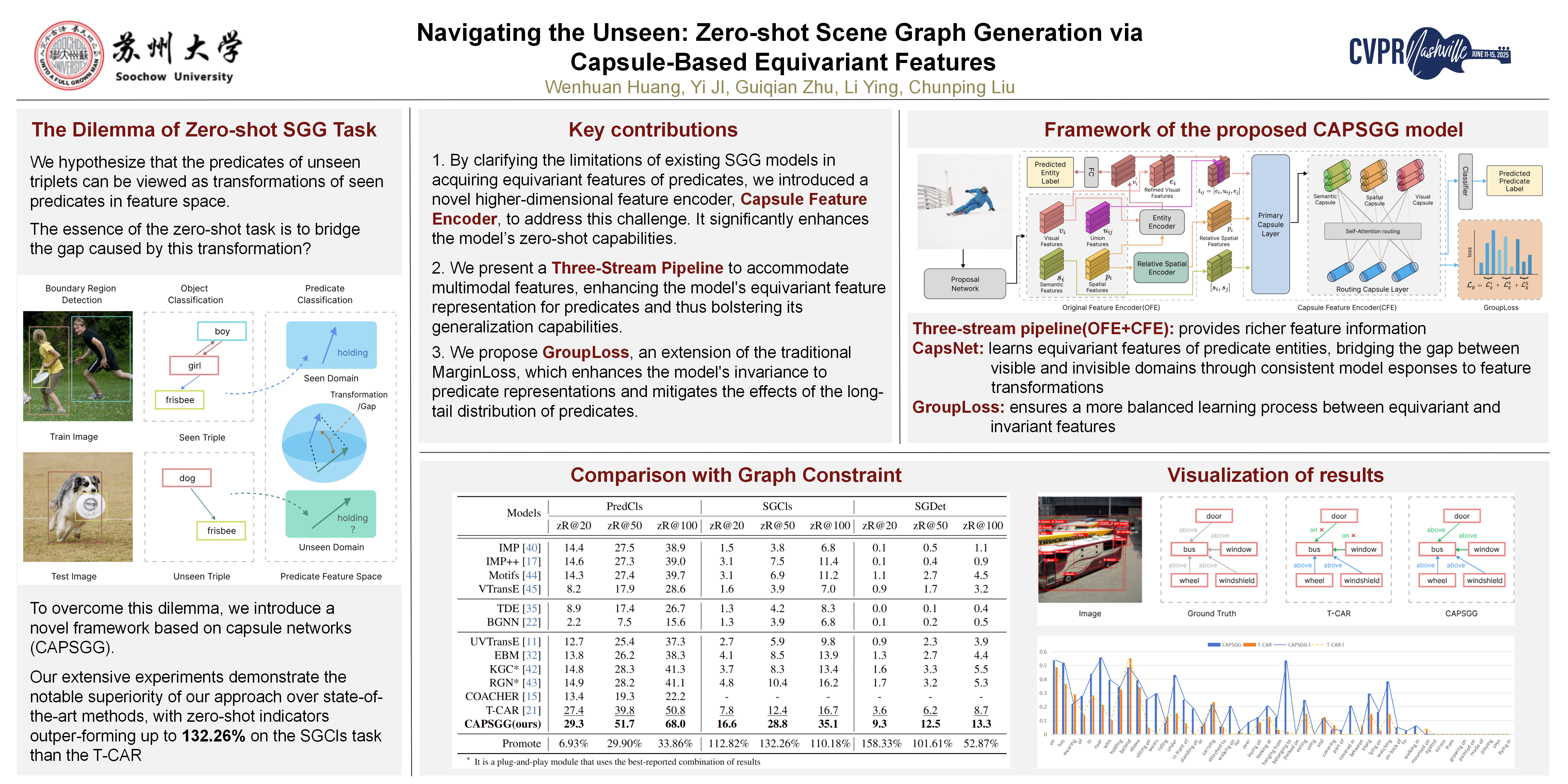
In scene graph generation (SGG), the accurate prediction of unseen triples is essential for its effectiveness in downstream vision-language tasks. We hypothesize that the predicates of unseen triples can be viewed as transformations of seen predicates in feature space, and the essence of the zero-shot task is to bridge the gap caused by this transformation. Traditional models, however, have difficulty addressing this challenge, which we attribute to their inability to model the predicates equivariant. To overcome this limitation, we introduce a novel framework based on capsule networks (CAPSGG). We propose a $\textbf{Three-Stream Pipeline}$ that generates modality-specific representations for predicates, while building low-level predicate capsules of these modalities. Then these capsules are aggregated into high-level predicate capsules using a $\textbf{Routing Capsule Layer}$. In addition, we introduce $\textbf{GroupLoss}$ to aggregate capsules with the same predicate label into groups. This replaces the global loss with the intra-group loss, effectively balancing the learning of predicate invariance and equivariant features, while mitigating the impact of the severe long-tail distribution of the predicate categories. Our extensive experiments demonstrate the notable superiority of our approach over state-of-the-art methods, with zero-shot indicators outperforming up to $\textbf{132.26\\%}$ on SGCls task than the T-CAR [21]. Our code will be available upon publication.
Chat is not available.
Successful Page Load