Shading Meets Motion: Self-supervised Indoor 3D Reconstruction Via Simultaneous Shape-from-Shading and Structure-from-Motion
{kind=link}
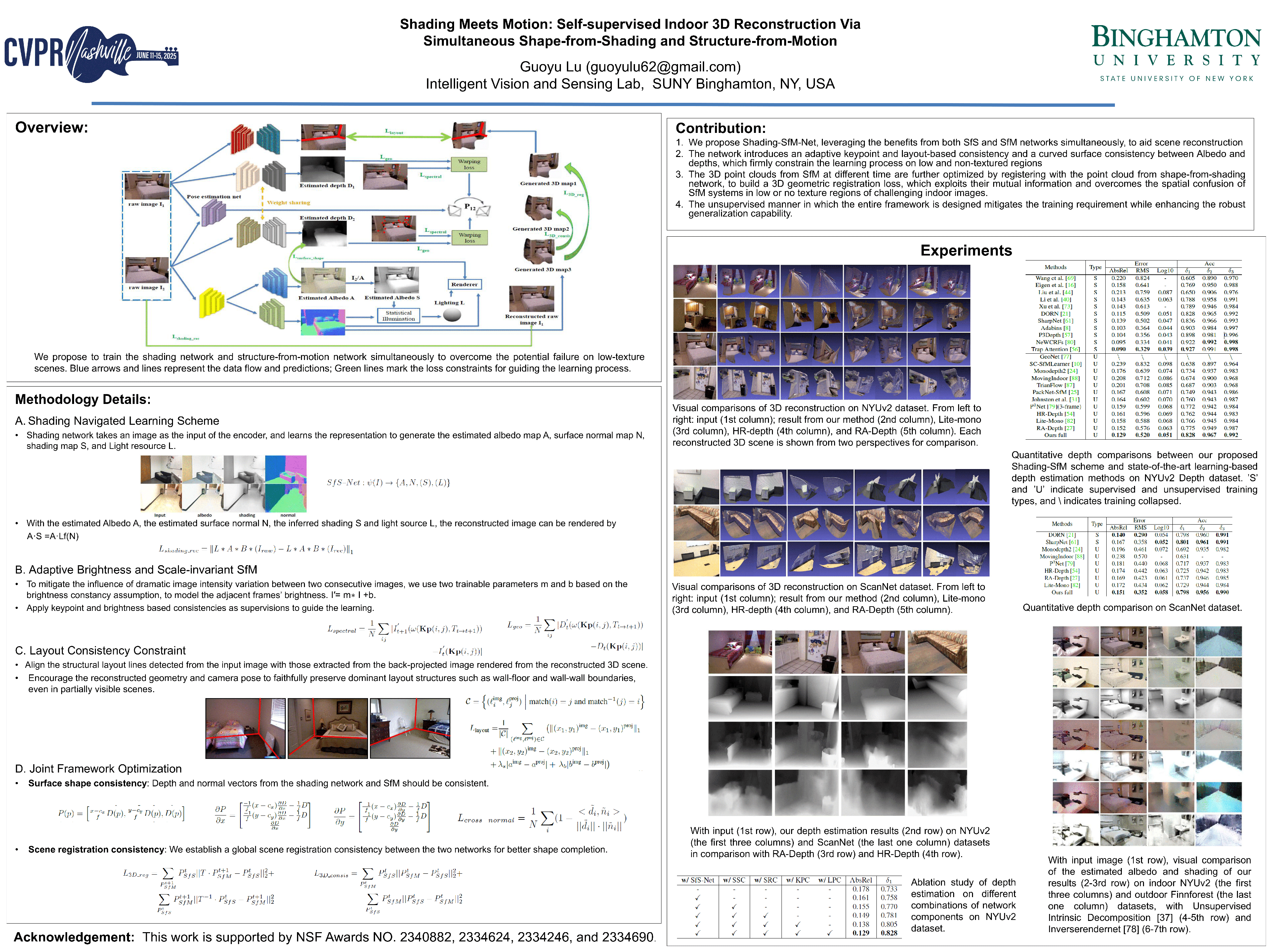
Abstract
Scene reconstruction has a wide range of applications in computer vision and robotics. To build practical constraints and feature correspondences, rich textures and distinguished gradient variations are particularly required in classic and learning-based SfM. When building low-texture regions with repeated patterns, especially mostly white indoor rooms, there is a significant drop in the performance. Inthis work, we propose Shading-SfM-Net (Shading & structure-from motion network), a novel framework for simultaneously learninga shape-from-shading network based on the inverse rendering constraint and a structure-from-motion framework based on warped keypoint and geometric consistency, to improve structure-from-motion and surface reconstruction for low-texture indoor scenes. Shading-SfM-Net tightly incorporates the surface shape consistency and 3D geometric registration loss in order to dig into their mutual informationand further overcome the instability on flat regions. We evaluate the proposed framework on texture-less indoor scenes (NYU v2and ScanNet), and show that for each individual network without simultaneous training, our method is able to achieve comparableresult to the state of the art methods. By simultaneously learning shape and motion from the two networks, our pipeline is able toachieve state-of-the-art performance with superior generalization capability for unseen texture-less datasets.