Vision-Language Embodiment for Monocular Depth Estimation
{kind=link}
Abstract
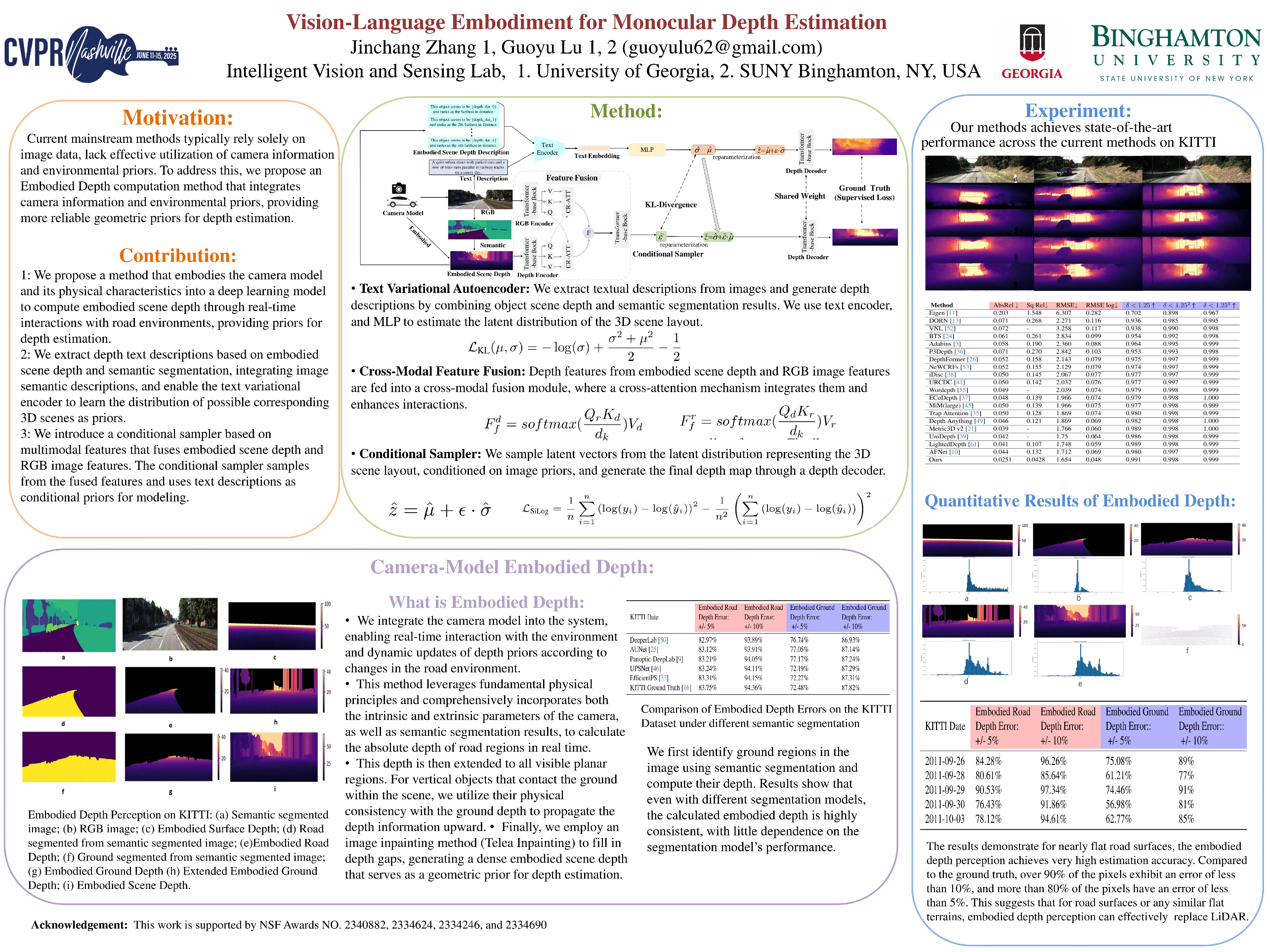
Depth estimation is a core problem in robotic perception and vision tasks, but 3D reconstruction from a single image presents inherent uncertainties. With the development of deep learning, current methods primarily rely on inter-image relationships to train supervised models, often overlooking intrinsic information provided by the camera itself. From the perspective of embodied intelligence, perception and understanding are not only based on external data inputs but are also closely linked to the physical environment in which the model is embedded. Following this concept, we propose a method that embeds the camera model and its physical characteristics into a deep learning model to compute Embodied Scene Depth through interactions with road environments. This approach leverages the intrinsic properties of the camera and provides robust depth priors without the need for additional equipment.By combining Embodied Scene Depth with RGB image features, the model gains a comprehensive perspective of both geometric and visual details. Additionally, we incorporate text descriptions containing environmental content and depth information as another dimension of embodied intelligence, embedding them as scale priors for scene understanding, thus enriching the model’s perception of the scene. This integration of image and language — two inherently ambiguous modalities — leverages their complementary strengths for monocular depth estimation, ensuring a more realistic understanding of scenes in diverse environments. We validated this method on outdoor datasets KITTI and CityScapes, with experimental results demonstrating that this embodied intelligence-based depth estimation method consistently enhances model performance across different scenes.