Enhancing Dance-to-Music Generation via Negative Conditioning Latent Diffusion Model
{kind=link}
Abstract
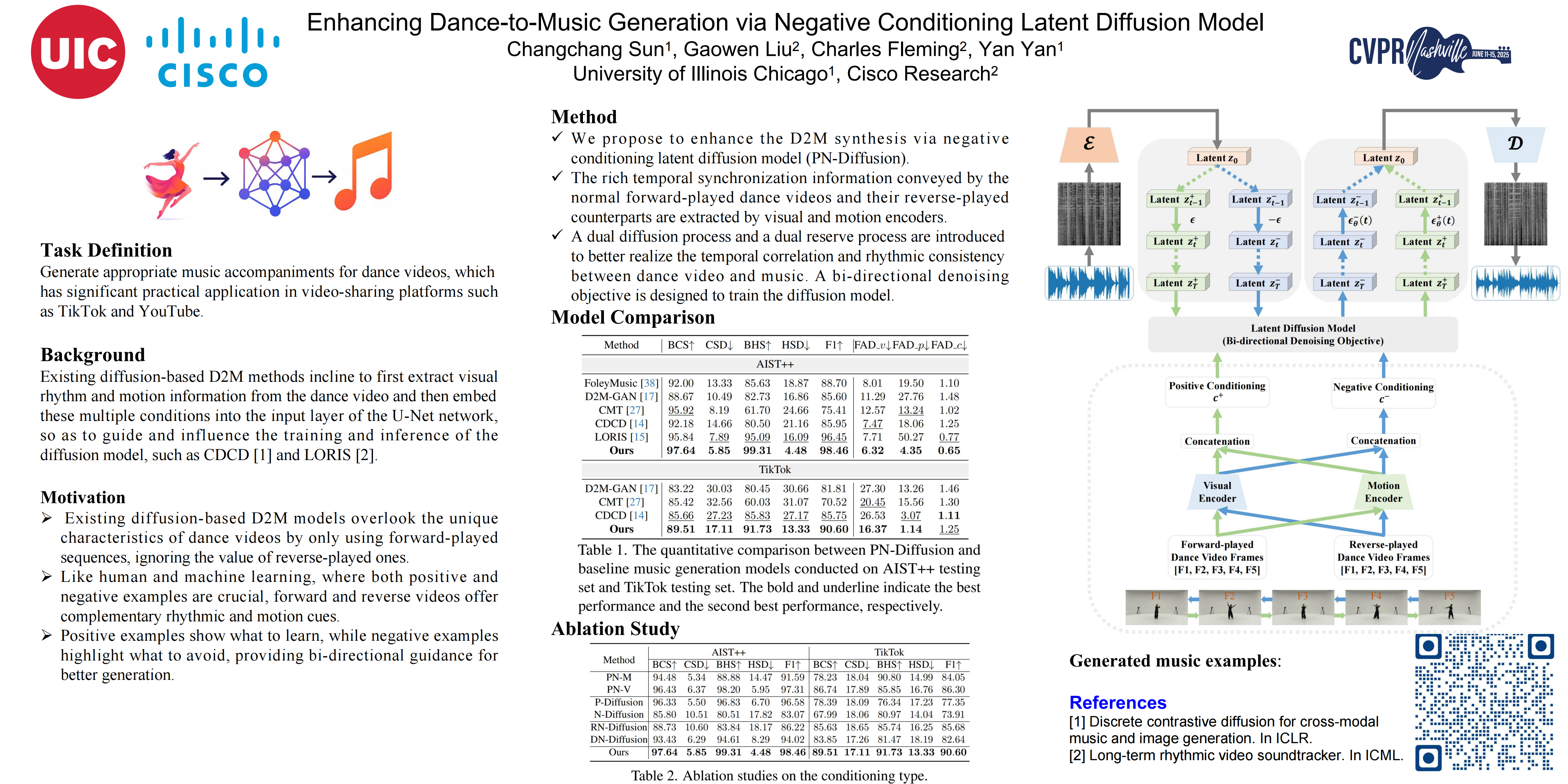
Recently, conditional diffusion models have gained increasing attention due to their impressive results for cross-modal synthesis.Typically, existing methods target at achieving strong alignment between conditioning input and generated output by training a time-conditioned U-Net augmented with cross-attention mechanism. In this paper, we focus on the problem of generating music synchronized with rhythmic visual cues of the given dance video. Considering that bi-directional guidance is more beneficial for training a diffusion model, we propose to improve the quality of generated music and its synchronization with dance videos by adopting both positive rhythmic information and negative ones (PN-Diffusion) as conditions, where a dual diffusion and reverse processes is devised. Different from existing dance-to-music diffusion models, PN-Diffusion consists of a noise prediction objective for positive conditioning and an additional noise prediction objective for negative conditioning to train a sequential multi-modal U-Net structure. To ensure the accurate definition and selection of negative conditioning, we ingeniously leverage temporal correlations between music and dance videos, where positive and negative rhythmic visual cues and motion information are captured by playing dance videos forward and backward, respectively. By subjectively and objectively evaluating input-output correspondence in terms of dance-music beats and the quality of generated music, experimental results on dance video datasets AIST++ and TikTok demonstrate the superiority of our model over SOTA dance-to-music generation models.