Unlocking the Potential of Unlabeled Data in Semi-Supervised Domain Generalization
{kind=link}
Abstract
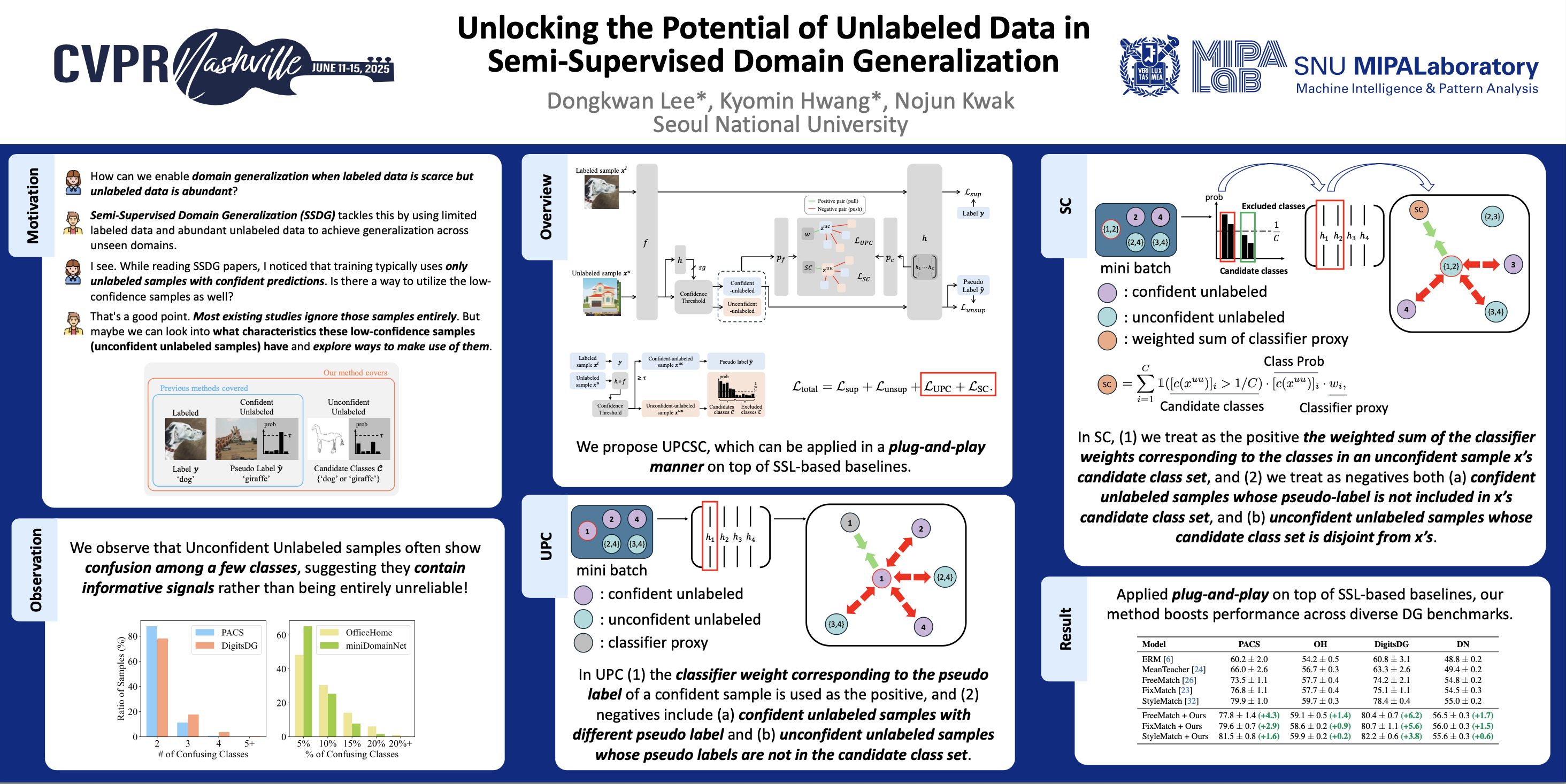
We address the problem of semi-supervised domain generalization (SSDG), where the distributions of train and test data differ, and only a small amount of labeled data along with a larger amount of unlabeled data are available during training. Existing SSDG methods that leverage only the unlabeled samples for which the model's predictions are highly confident (confident-unlabeled samples), limit the full utilization of the available unlabeled data. To the best of our knowledge, we are the first to explore a method for incorporating the unconfident-unlabeled samples that were previously disregarded in SSDG setting. To this end, we propose UPCSC to utilize these unconfident-unlabeled samples in SSDG that consists of two modules: 1) Unlabeled Proxy-based Contrastive learning (UPC) module, treating unconfident-unlabeled samples as additional negative pairs and 2) Surrogate Class learning (SC) module, generating positive pairs for unconfident-unlabeled samples using their confusing class set. These modules are plug-and-play and do not require any domain labels, which can be easily integrated into existing approaches. Experiments on four widely used SSDG benchmarks demonstrate that our approach consistently improves performance when attached to baselines and outperforms competing plug-and-play methods. We also analyze the role of our method in SSDG, showing that it enhances class-level discriminability and mitigates domain gaps.