ROD-MLLM: Towards More Reliable Object Detection in Multimodal Large Language Models
{kind=link}
Abstract
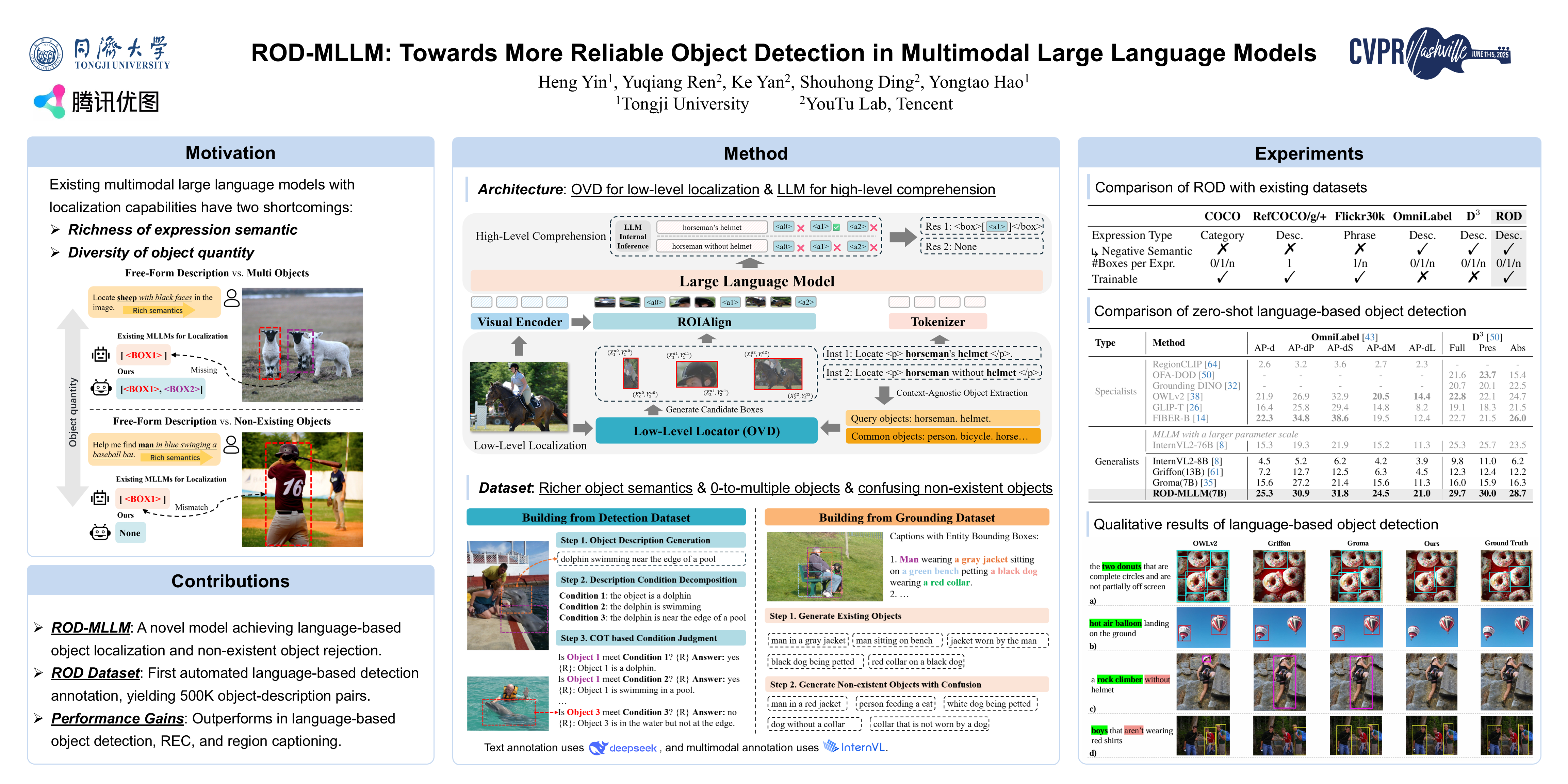
Multimodal large language models (MLLMs) have demonstrated strong language understanding and generation capabilities, excelling in visual tasks like referring and grounding. However, due to task type limitations and dataset scarcity, existing MLLMs only ground objects present in images and cannot reject non-existent objects effectively, resulting in unreliable predictions. In this paper, we introduce ROD-MLLM, a novel MLLM for Reliable Object Detection using free-form language. We propose a query-based localization mechanism to extract low-level object features. By aligning global and object-level visual information with text space, we leverage the large language model (LLM) for high-level comprehension and final localization decisions, overcoming the language understanding limitations of normal detectors. To enhance language-based object detection, we design an automated data annotation pipeline and construct the dataset ROD. This pipeline uses the referring capabilities of existing MLLMs and chain-of-thought techniques to generate diverse expressions corresponding to zero or multiple objects, addressing the shortage of training data. Experiments across various tasks, including referring, grounding, and language-based object detection, show that ROD-MLLM achieves state-of-the-art performance among MLLMs. Notably, in language-based object detection, our model achieves a +13.7 mAP improvement over existing MLLMs and surpasses most specialized detection models, especially in scenarios requiring advanced complex language understanding.