Flexible Frame Selection for Efficient Video Reasoning
{kind=link}
Abstract
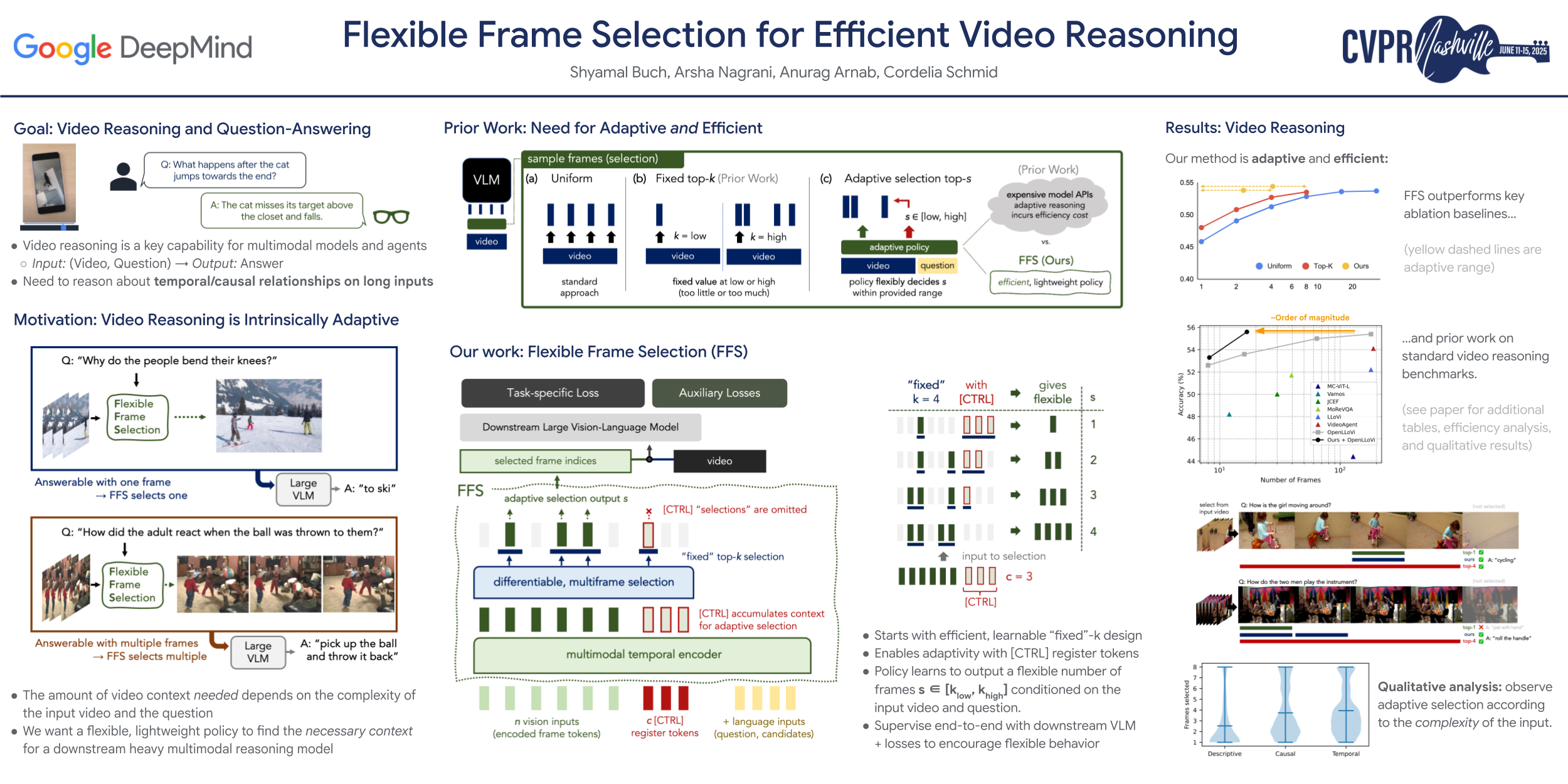
Video-language models have shown promise for addressing a range of multimodal tasks for video understanding, such as video question-answering. However, the inherent computational challenges of processing long video data and increasing model sizes have led to standard approaches that are limited by the number of frames they can process. In this work, we propose the Flexible Frame Selector (FFS), a learnable policy model with a new flexible selection operation, that helps alleviate input context restrictions by enabling video-language models to focus on the most informative frames for the downstream multimodal task, without adding undue processing cost. Our method differentiates from prior work due to its learnability, efficiency, and flexibility. We verify the efficacy of our method on standard video-question answering and reasoning benchmarks, and observe that our model can improve base video-language model accuracy while reducing the number of downstream processed frames.