MARVEL-40M+: Multi-Level Visual Elaboration for High-Fidelity Text-to-3D Content Creation
Sankalp Sinha ⋅ Mohammad Sadil Khan ⋅ Muhammad Usama ⋅ Shino Sam ⋅ Didier Stricker ⋅ Sk Aziz Ali ⋅ Muhammad Zeshan Afzal
2025 Poster
{kind=link}
Abstract
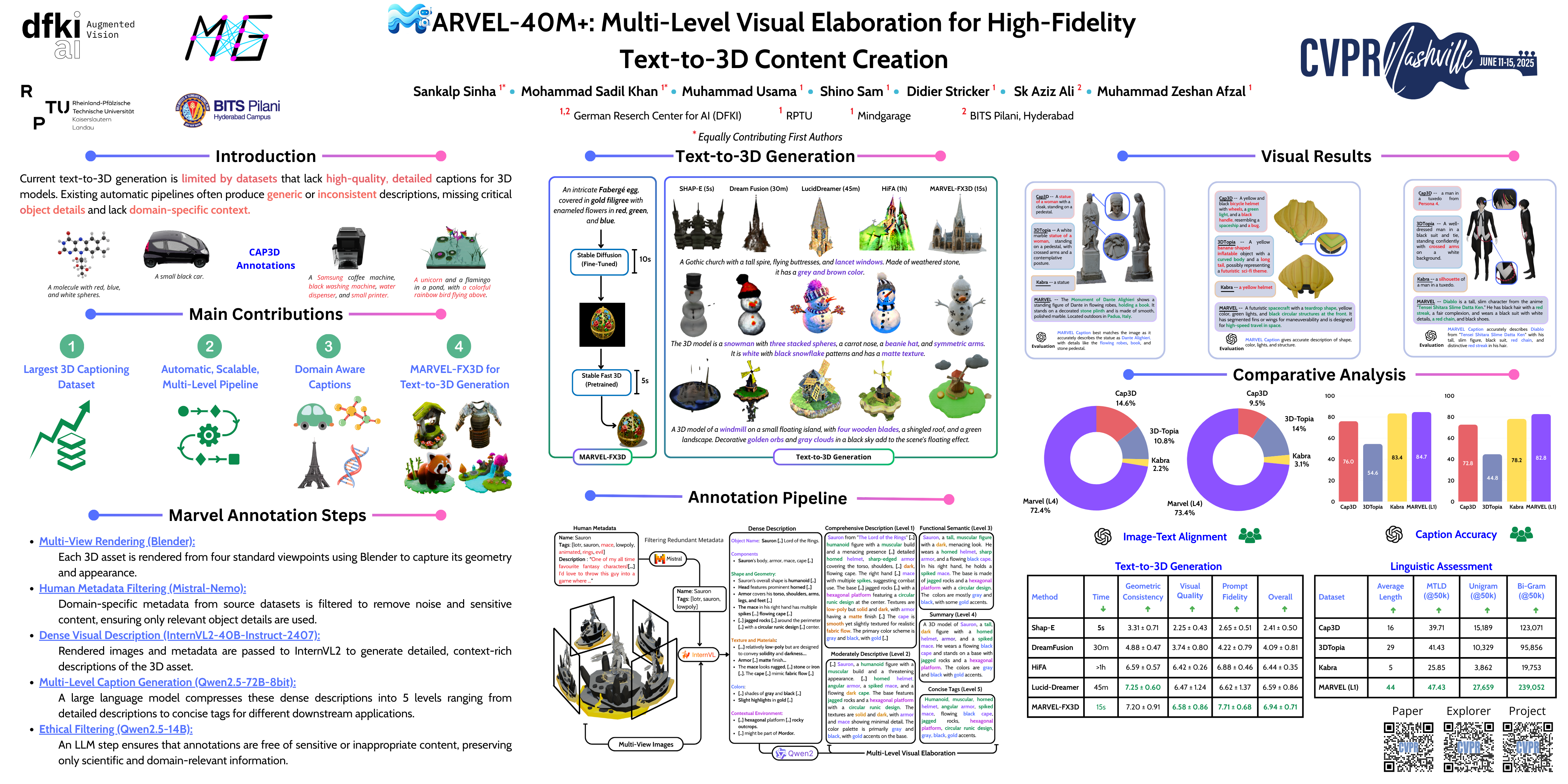
Generating high-fidelity 3D content from text prompts remains a significant challenge in computer vision due to the limited size, diversity, and annotation depth of the existing datasets. To address this, we introduce MARVEL-$40$M+, an extensive dataset with $40$ million text annotations for over $8.9$ million 3D assets aggregated from seven major 3D datasets. Our contribution is a novel multi-stage annotation pipeline that integrates open-source pretrained multi-view VLMs and LLMs to automatically produce multi-level descriptions, ranging from detailed ($150$-$200$ words) to concise semantic tags ($10$-$20$ words). This structure supports both fine-grained 3D reconstruction and rapid prototyping. Furthermore, we incorporate human metadata from source datasets into our annotation pipeline to add domain-specific information in our annotation and reduce VLM hallucinations. Additionally, we develop MARVEL-FX3D, a two-stage text-to-3D pipeline. We fine-tune Stable Diffusion with our annotations and use a pretrained image-to-3D network to generate 3D textured meshes within 15s. Extensive evaluations show that MARVEL-40M+ significantly outperforms existing datasets in annotation quality and linguistic diversity, achieving win rates of $72.41\%$ by GPT-4 and $73.40\%$ by human evaluators.
Chat is not available.
Successful Page Load