Model Poisoning Attacks to Federated Learning via Multi-Round Consistency
{kind=link}
Abstract
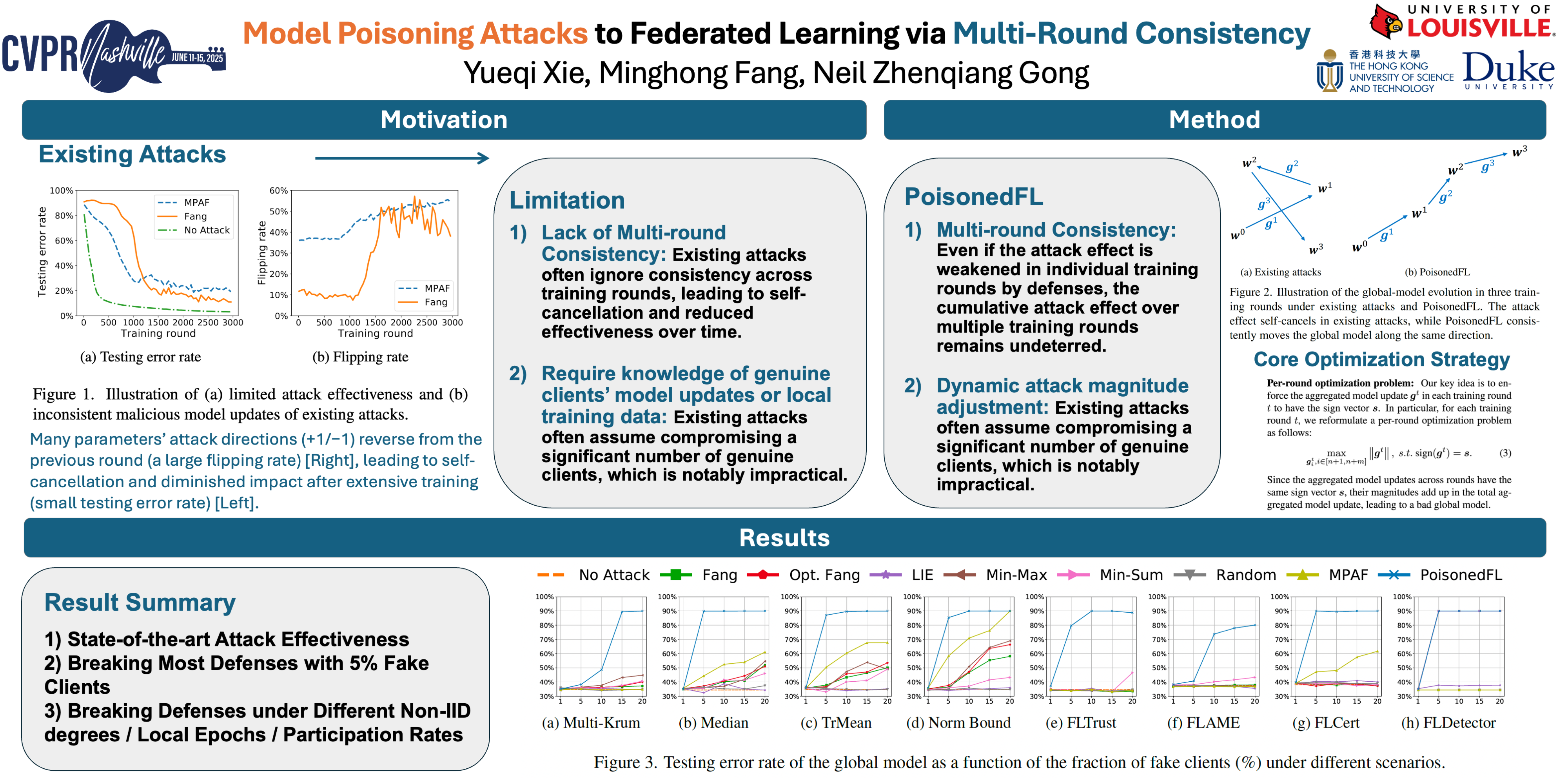
Model poisoning attacks are critical security threats to Federated Learning (FL). Existing model poisoning attacks suffer from two key limitations: 1) they achieve suboptimal effectiveness when defenses are deployed, and/or 2) they require knowledge of the model updates or local training data on genuine clients. In this work, we make a key observation that their suboptimal effectiveness arises from only leveraging model-update consistency among malicious clients within individual training rounds, making the attack effect self-cancel across training rounds. In light of this observation, we propose PoisonedFL, which enforces multi-round consistency among the malicious clients' model updates while not requiring any knowledge about the genuine clients.Our empirical evaluation on five benchmark datasets shows that \ourmodel{} breaks eight state-of-the-art defenses and outperforms seven existing model poisoning attacks. Our study shows that FL systems are considerably less robust than previously thought, underlining the urgency for the development of new defense mechanisms.