Audio-Visual Semantic Graph Network for Audio-Visual Event Localization
{kind=link}
Abstract
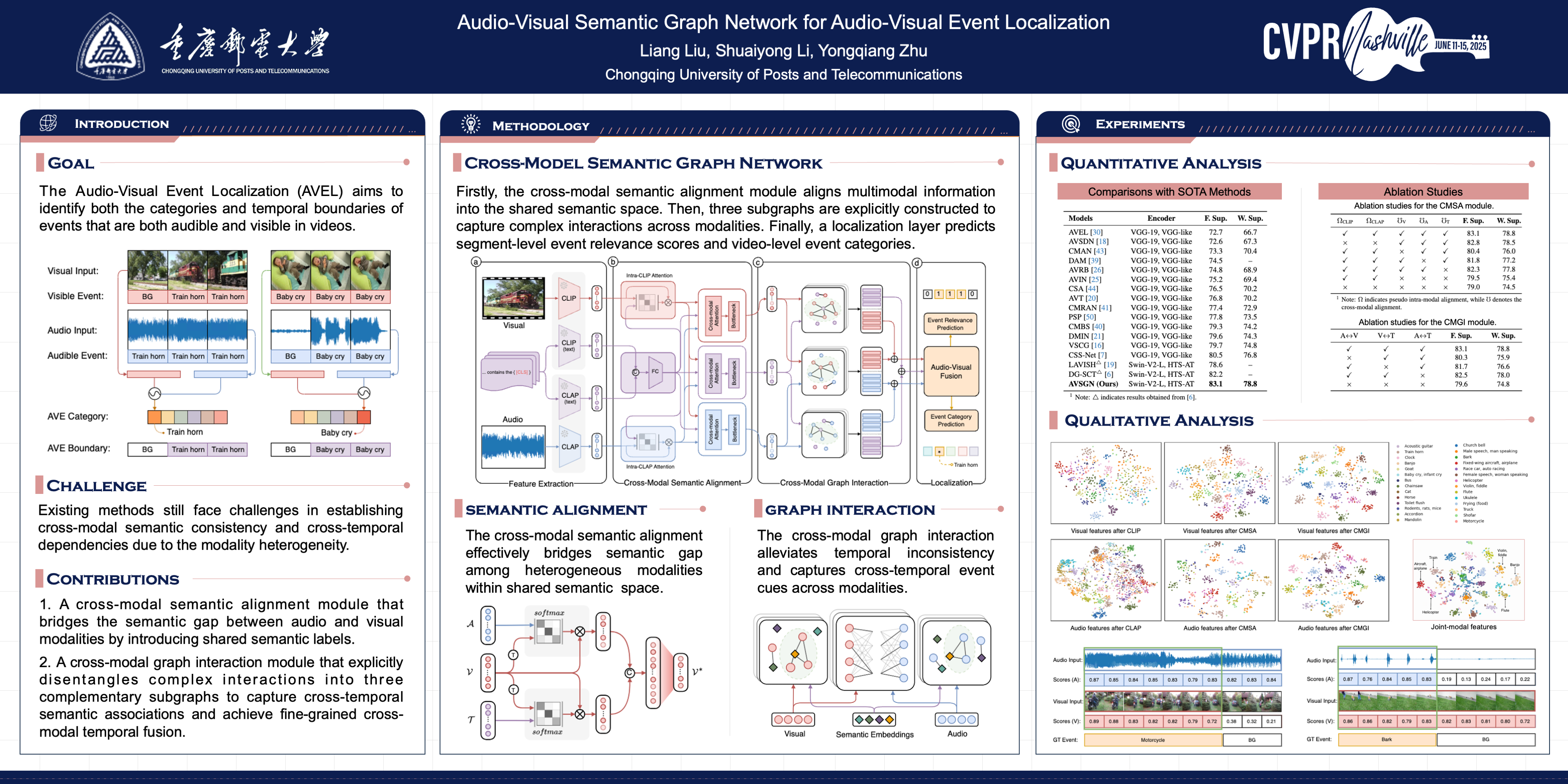
Audio-visual event localization (AVEL) involves identifying the category and the corresponding temporal boundary of an event that is both audible and visible in unconstrained videos. However, the semantic gap between heterogeneous modalities often leads to audio-visual semantic inconsistency. In this paper, we propose a novel Audio-Visual Semantic Graph Network (AVSGN) to facilitate cross-modal alignment and cross-temporal interaction. Unlike previous methods (e.g., audio-guided, visual-guided, or both), we introduce shared semantic textual labels to bridge the semantic gap between audio and visual modalities. Specifically, we present a cross-modal semantic alignment (CMSA) module to explore the cross-modal complementary relationships across heterogeneous modalities (i.e., visual, audio and text), promoting the convergence of multimodal distributions into a common semantic space. Additionally, in order to capture cross-temporal associations sufficiently, we devise a cross-modal graph interaction (CMGI) module, which disentangles complicated interactions across modalities into three complementary subgraphs. Extensive experiments on the AVE dataset comprehensively demonstrate the superiority and effectiveness of the proposed model in both fully- and weakly-supervised AVE settings.