GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
{kind=link}
Abstract
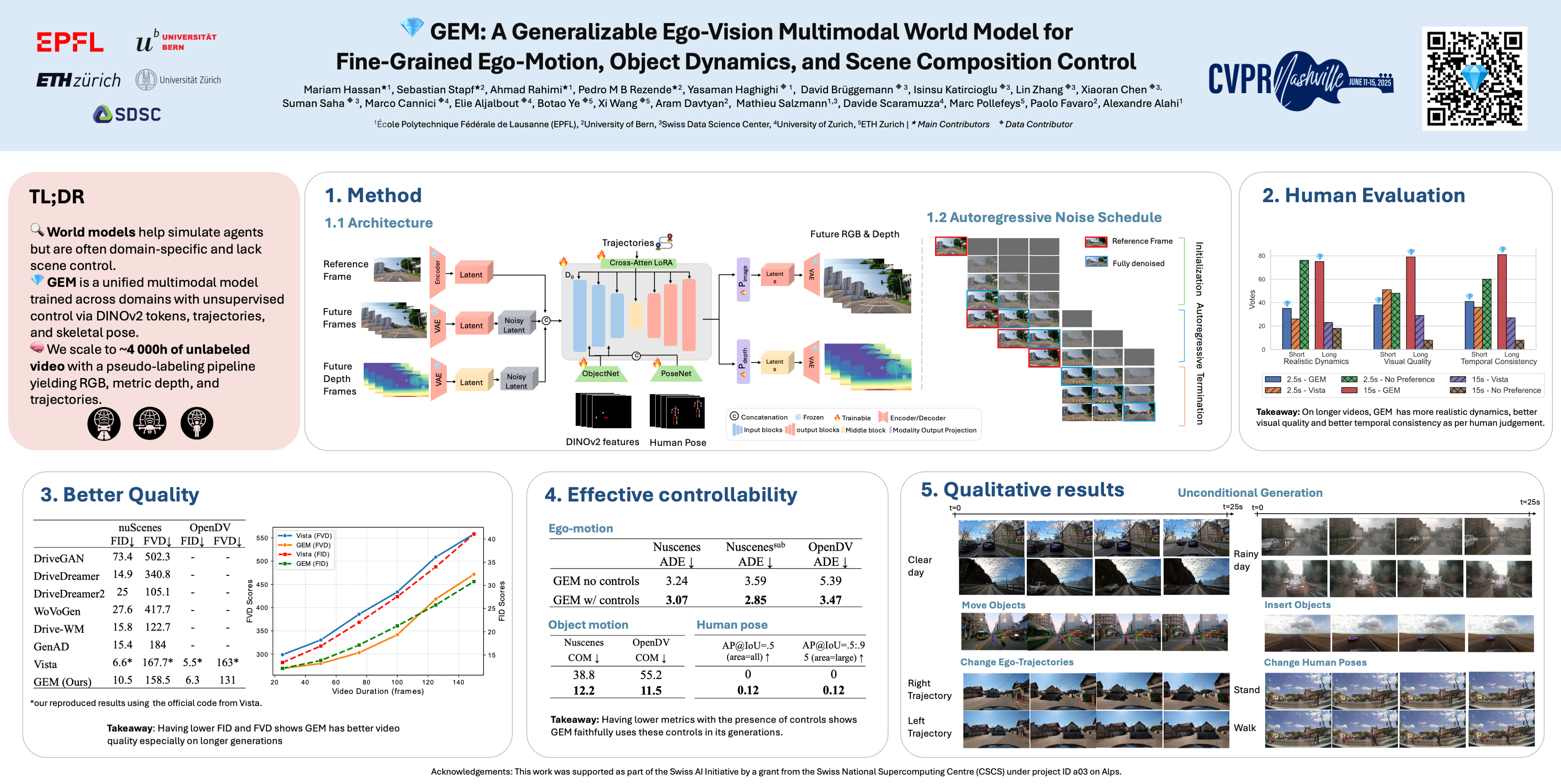
World models predict future frames from past observations and actions, making them powerful simulators for ego-vision tasks with complex dynamics, such as autonomous driving. Nonetheless, existing world models for ego-vision mainly focus on the driving domain and the ego-vehicle's actions limiting the complexity and diversity of the generated scenes. In this work, we propose \textit{GEM}, a diffusion-based world model with generalized control strategy. By leveraging ego-trajectories and general image features, GEM not only allows for fine-grained control over the ego-motion, but also enables to control the motion of other objects in the scene and supports scene composition, by inserting new objects. GEM is multimodal, capable of generating both videos and future depth sequences, providing rich semantic and spatial output contexts. Although our primary focus remains on the domain of autonomous driving, we explore the adaptability of GEM to other ego-vision domain such as human activity and drone navigation. To evaluate GEM’s controllability, we propose a comprehensive evaluation framework. The results show the effectiveness of GEM in controlling the motion of objects within the scene, with conditional generation outperforming unconditional generation by 68% and 79% on Nuscenes and OpenDV respectively.