VL2Lite: Task-Specific Knowledge Distillation from Large Vision-Language Models to Lightweight Networks
{kind=link}
Abstract
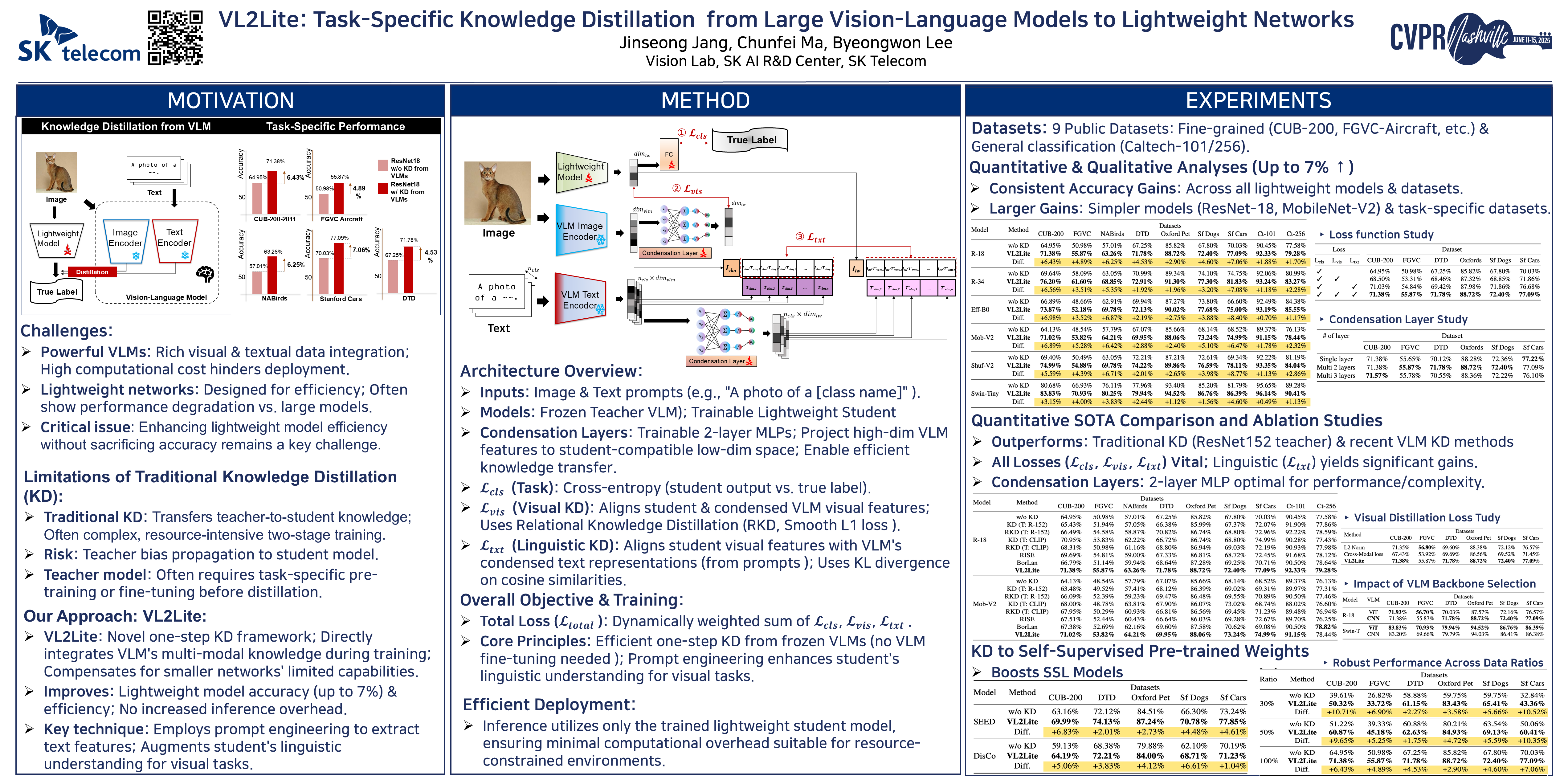
Deploying high-performing neural networks in resource-constrained environments poses a significant challenge due to the computational demands of large-scale models. We introduce VL2Lite, a knowledge distillation framework designed to enhance the performance of lightweight neural networks in image classification tasks by leveraging the rich representational knowledge from Vision-Language Models (VLMs). VL2Lite directly integrates multi-modal knowledge from VLMs into compact models during training, effectively compensating for the limited computational and modeling capabilities of smaller networks. By transferring high-level features and complex data representations, our approach improves the accuracy and efficiency of image classification tasks without increasing computational overhead during inference. Experimental evaluations demonstrate that VL2Lite achieves up to a 7% improvement in classification performance across various datasets. This method addresses the challenge of deploying accurate models in environments with constrained computational resources, offering a balanced solution between model complexity and operational efficiency.