DKDM: Data-Free Knowledge Distillation for Diffusion Models with Any Architecture
{kind=link}
Abstract
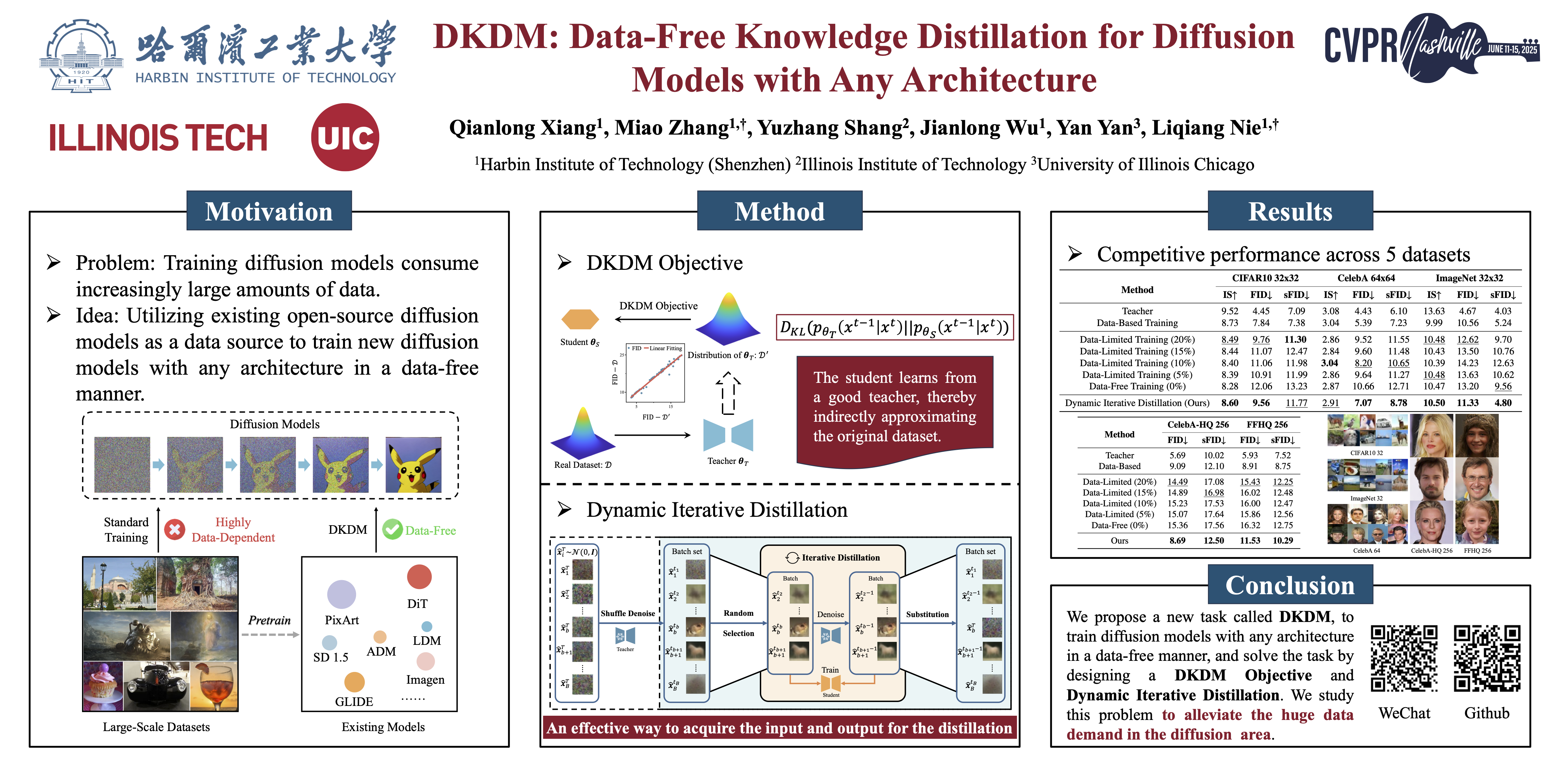
Diffusion models (DMs) have demonstrated exceptional generative capabilities across various domains, including image, video, and so on. A key factor contributing to their effectiveness is the high quantity and quality of data used during training. However, mainstream DMs now consume increasingly large amounts of data. For example, training a Stable Diffusion model requires billions of image-text pairs. This enormous data requirement poses significant challenges for training large DMs due to high data acquisition costs and storage expenses. To alleviate this data burden, we propose a novel scenario: using existing DMs as data sources to train new DMs with any architecture. We refer to this scenario as Data-Free Knowledge Distillation for Diffusion Models (DKDM), where the generative ability of DMs is transferred to new ones in a data-free manner. To tackle this challenge, we make two main contributions. First, we introduce a DKDM objective that enables the training of new DMs via distillation, without requiring access to the data. Second, we develop a dynamic iterative distillation method that efficiently extracts time-domain knowledge from existing DMs, enabling direct retrieval of training data without the need for a prolonged generative process. To the best of our knowledge, we are the first to explore this scenario. Experimental results demonstrate that our data-free approach not only achieves competitive generative performance but also, in some instances, outperforms models trained with the entire dataset.