Separation of Powers: On Segregating Knowledge from Observation in LLM-enabled Knowledge-based Visual Question Answering
{kind=link}
Abstract
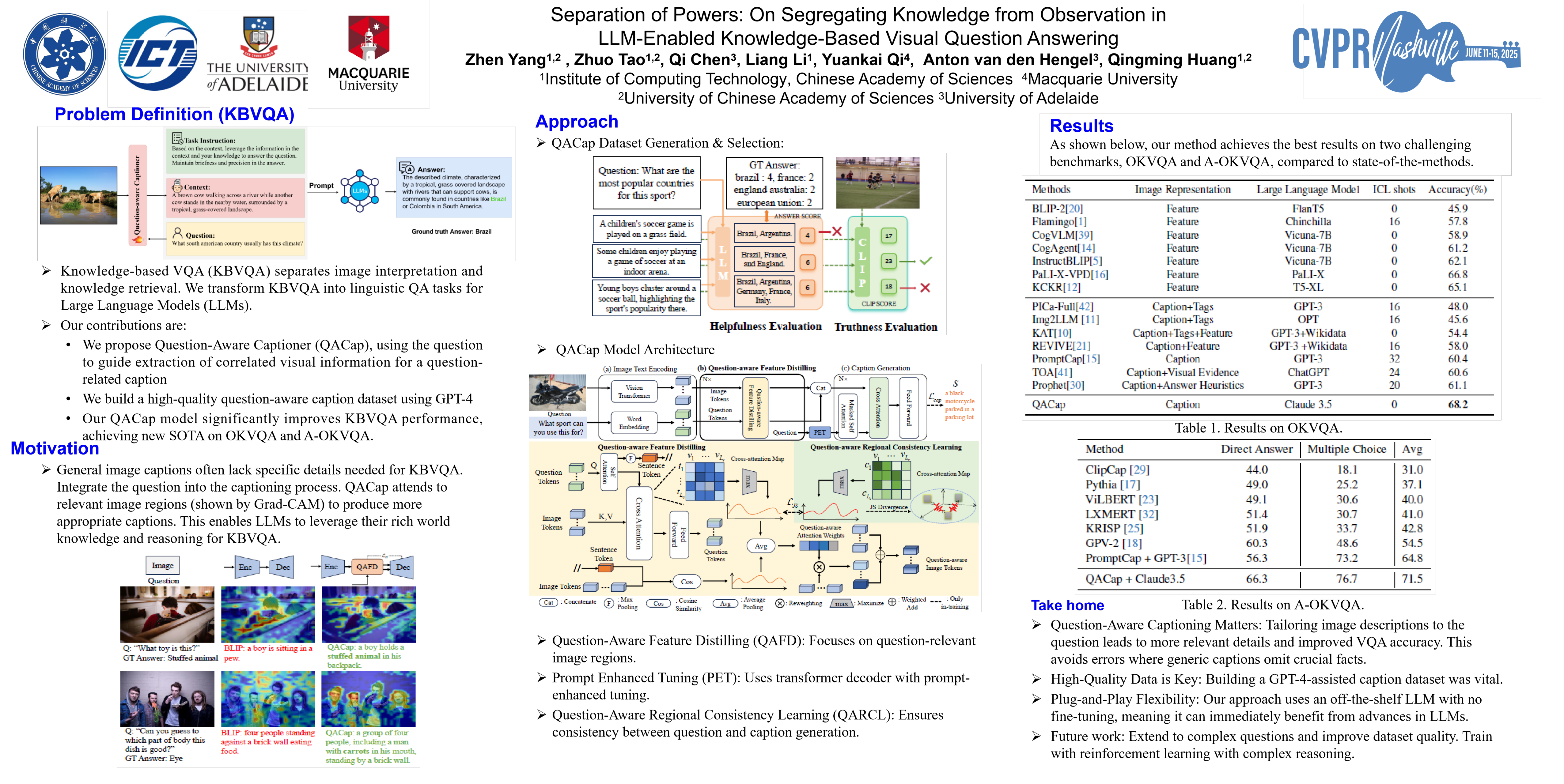
Knowledge-based visual question answering (KBVQA) separates image interpretation and knowledge retrieval into separate processes, motivated in part by the fact that they are very different tasks. In this paper, we transform the KBVQA into linguistic question-answering tasks so that we can leverage the rich world knowledge and strong reasoning abilities of Large Language Models (LLMs). The caption-then-question approach to KBVQA has been effective but relies on the captioning method to describe the detail required to answer every possible question. We propose instead a Question-Aware Captioner (QACap), which uses the question as guidance to extract correlated visual information from the image and generate a question-related caption. To train such a model, we utilize GPT-4 to build a corresponding high-quality question-aware caption dataset on top of existing KBVQA datasets. Extensive experiments demonstrate that our QACap model and dataset significantly improve KBVQA performance. Our method, QACap, achieves 68.2\% accuracy on the OKVQA validation set, 73.4\% on the direct-answer part of the A-OKVQA validation set, and 74.8\% on the multiple-choice part, all setting new SOTA benchmarks.