NVILA: Efficient Frontier Visual Language Models
{kind=link}
Abstract
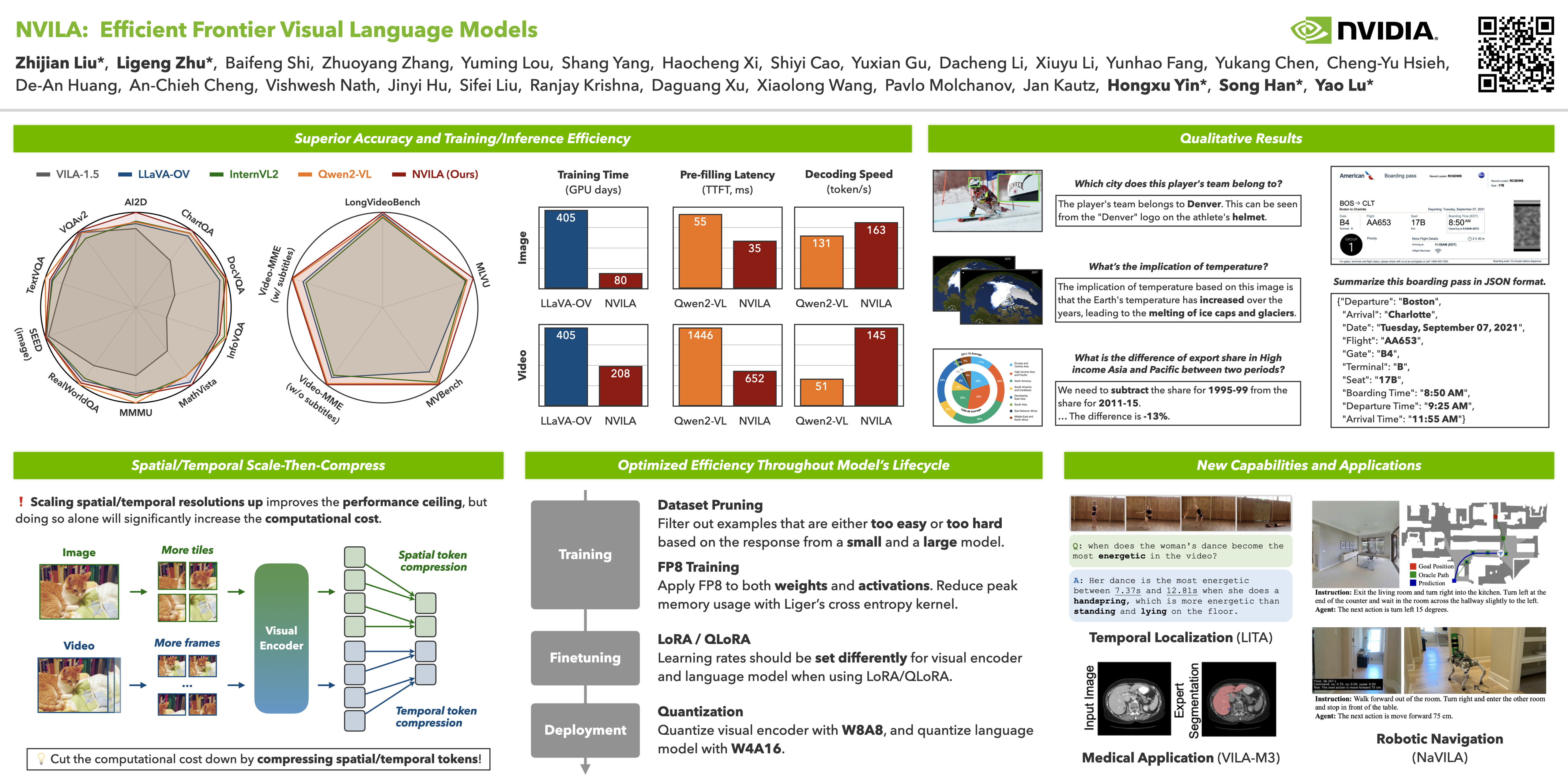
Visual language models (VLMs) have made significant strides in accuracy in recent years, but their efficiency has often been overlooked. This paper presents NVILA, a family of open frontier VLMs designed to optimize both efficiency and accuracy. Building upon VILA, we improve its model architecture by first scaling up spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach allows NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic study to improve NVILA's efficiency throughout its entire lifecycle—from training and fine-tuning to deployment. NVILA is both efficient and accurate, reducing training costs by 4.5×, fine-tuning memory usage by 3.4×, prefilling latency by 1.8× and decoding throughput by 1.2×. It also achieves state-of-the-art results across diverse image and video benchmarks. We will release our implementation and trained models to support full reproducibility.