MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
{kind=link}
Abstract
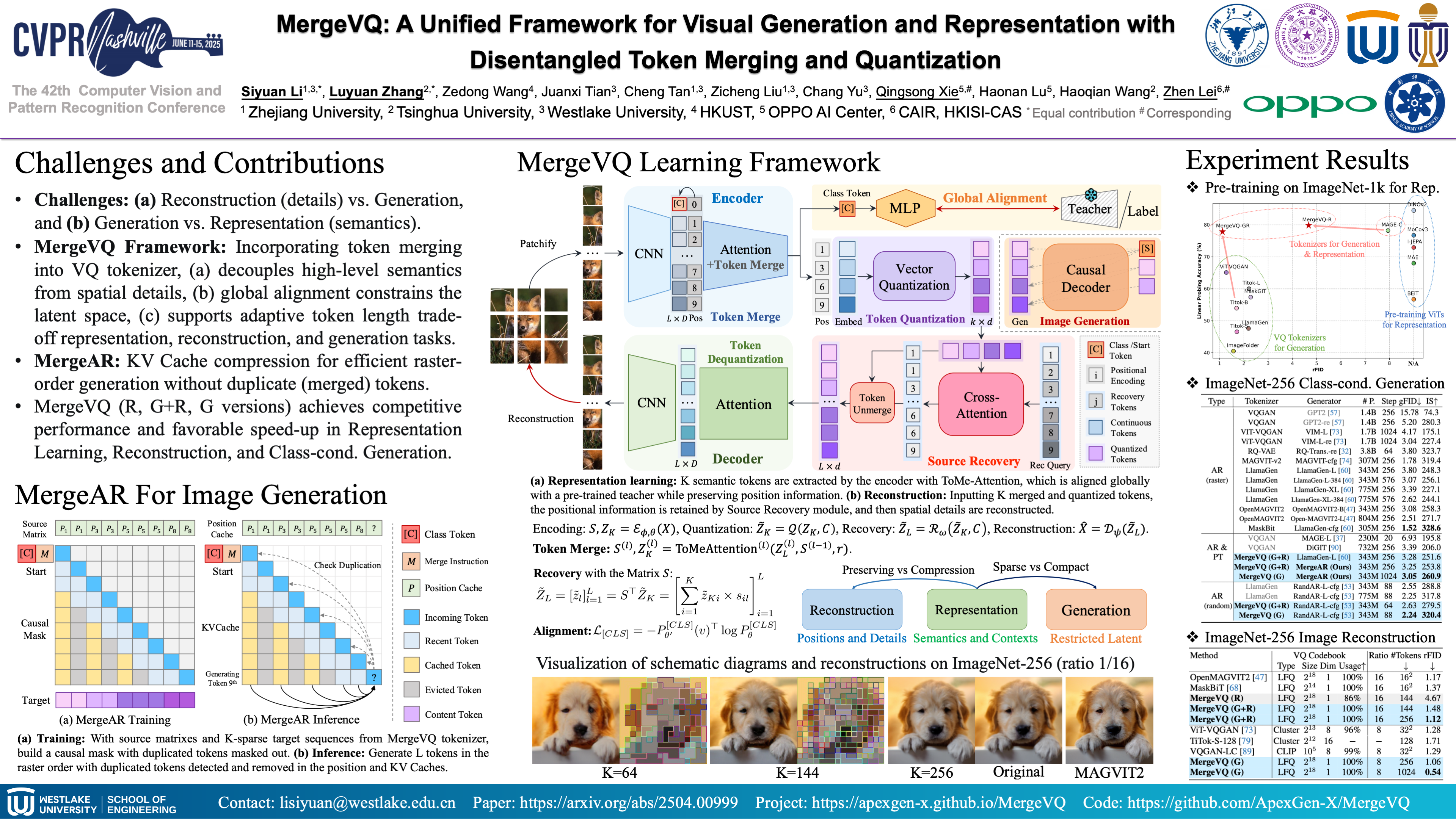
Masked Image Modeling (MIM) with Vector Quantization (VQ) have achieved great success in self-supervised pre-training and image generation. However, the most methods could not solve two technical challenges simultaneously: (1) The gradient approximation in classical VQ (e.g., VQGAN) sets a optimization bottleneck for the codebook and encoder; (2) Trade-off in the kept token lengths for generation quality vs. representation learning and efficiency. To unveil the full power of this learning paradigm, this paper introduces a unified framework that achieves both visual representation learning and generation in an auto-encoding way with token merging and vector quantization, called MergeVQ. As for pre-training, we merge the full spatial tokens into top-k semantic ones with the token merge module after self-attention blocks in the encoder and recovery the positions of the merged tokens with cross-attention blocks in the decoder. As for generation, we quantize the selected top-k tokens with Look-up Free Quantization (LFQ) with no training bottleneck and trade-off the computational overheads and qualities for generation. Extensive experiments on ImageNet verify that our MergeVQ achieves both performance gains and speeding up across image generation and self-supervised pre-training scenarios.