On Denoising Walking Videos for Gait Recognition
{kind=link}
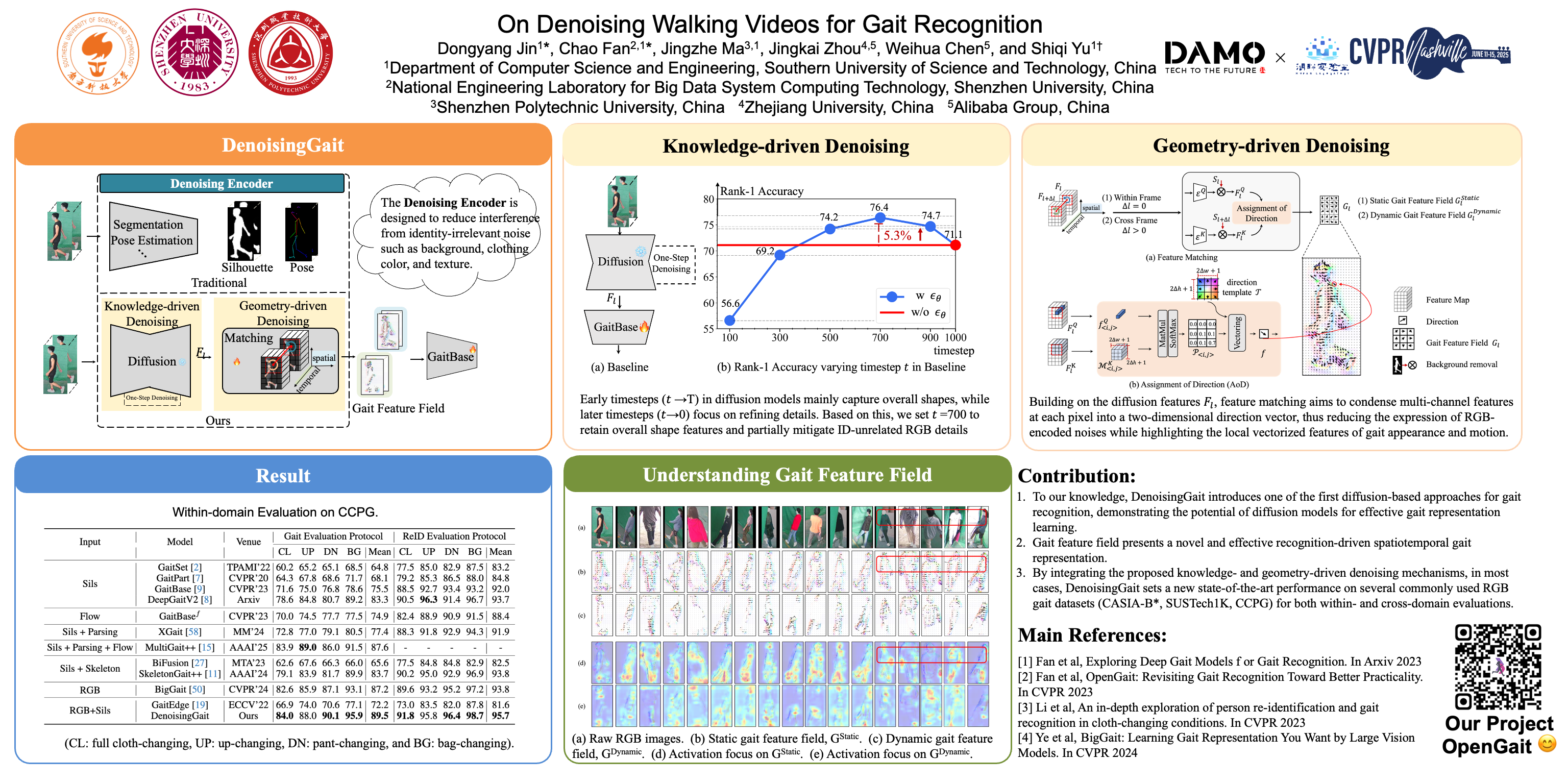
Abstract
To capture individual gait patterns, excluding identity-irrelevant cues in walking videos, such as clothing texture and color, remains a persistent challenge for vision-based gait recognition. Traditional silhouette and pose-based methods, though theoretically effective at removing such distractions, often fall short of high accuracy due to their sparse and less informative inputs. To address this, emerging end-to-end methods focus on directly denoising RGB videos using global optimization and human-defined priors. Building on this trend, we propose a novel gait denoising method, DenosingGait. Inspired by the philosophy that “what I cannot create, I do not understand”, we turn to generative diffusion models, uncovering how these models can partially filter out irrelevant factors for improved gait understanding. Based on this generation-driven denoising, we introduce feature matching, a kind of popular geometrical constraint in optical flow and depth estimation, to compact multi-channel float-encoded RGB information into two-channel direction vectors that represent local structural features, where within-frame matching captures spatial details and cross-frame matching conveys temporal dynamics. Experiments on the CCPG, CAISA-B*, and SUSTech1K datasets demonstrate that DenoisingGait achieves a new SoTA performance in most cases for both within-domain and cross-domain evaluations.All the code will be released.