GaussTR: Foundation Model-Aligned Gaussian Transformer for Self-Supervised 3D Spatial Understanding
{kind=link}
Abstract
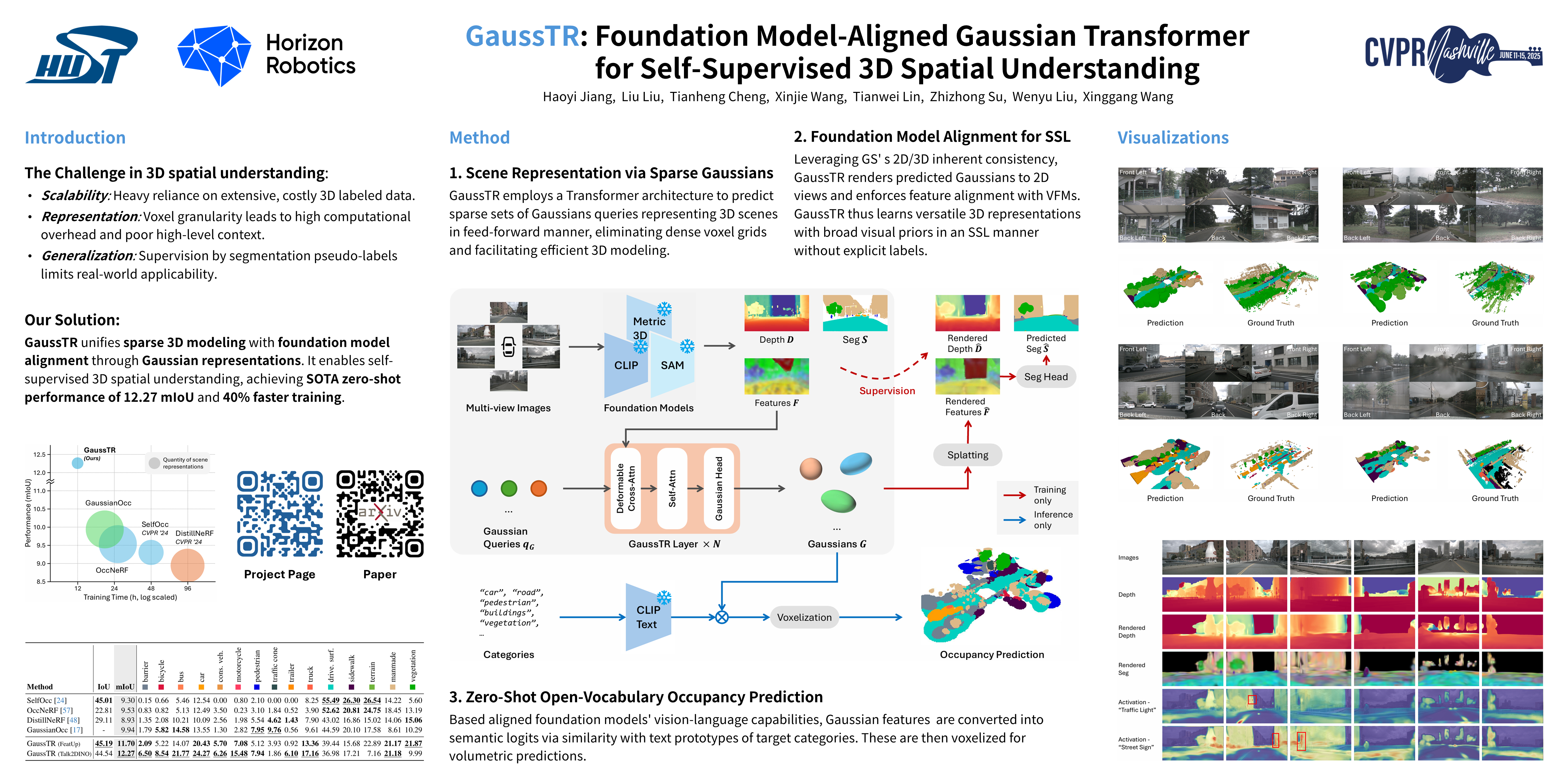
3D Semantic Occupancy Prediction is pivotal for spatial understanding as it provides a comprehensive semantic cognition of surrounding environments. However, prevalent approaches primarily rely on extensive labeled data and computationally intensive voxel-based modeling, restricting the scalability and generalizability of 3D representation learning. In this paper, we introduce GaussTR, a novel Gaussian Transformer that aligns with foundation models to enhance self-supervised 3D spatial understanding. GaussTR adopts a Transformer architecture to predict sparse sets of 3D Gaussians representing scenes in a feed-forward manner. Through the alignment of rendered Gaussian features with diverse knowledge from pre-trained foundation models, GaussTR facilitates the learning of versatile 3D representations, thereby enabling open-vocabulary occupancy prediction without explicit annotations. Empirical evaluations on the Occ3D-nuScenes dataset demonstrate GaussTR's state-of-the-art zero-shot performance, achieving 11.70 mIoU while reducing training duration by approximately 50\%. These results highlight the significant potential of GaussTR for advancing scalable and holistic 3D spatial understanding, with promising implications for autonomous driving and embodied agents. The code will be made publicly available in due course.