ShowUI: One Vision-Language-Action Model for GUI Visual Agent
{kind=link}
Abstract
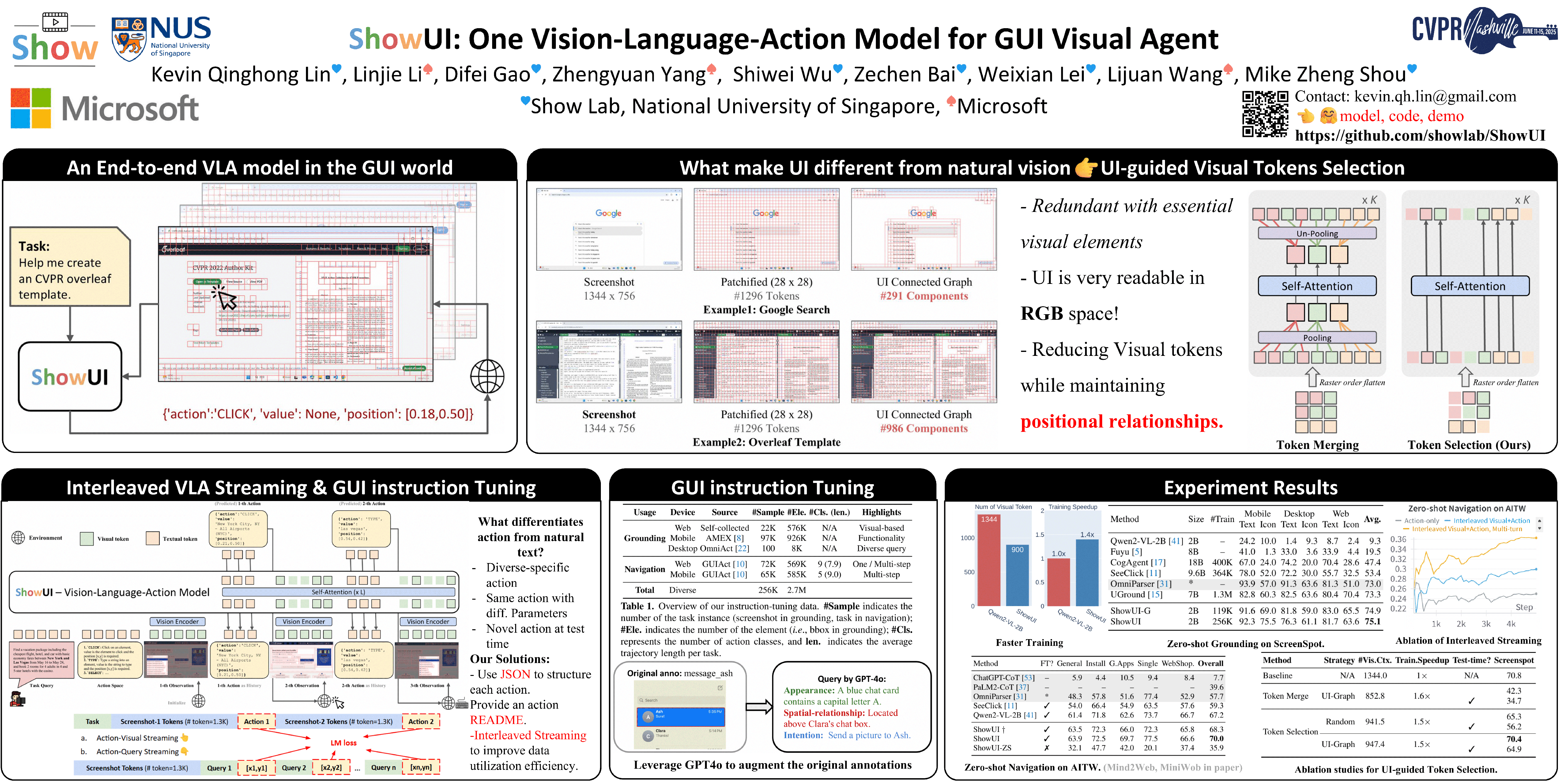
Building Graphical User Interface (GUI) assistants holds significant promise for enhancing human workflow productivity. While most agents are language-based, relying on closed-source API with text-rich meta-information (e.g., HTML or accessibility tree), they show limitations in perceiving UI visuals as humans do, highlighting the need for GUI visual agents.In this work, we develop a vision-language-action model in the digital world, namely "Our Model," which features the following innovations:1. UI-Guided Visual Token Selection to reduce computational costs by formulating screenshots as a UI-connected graph, adaptively identifying their redundant relationships and serving as the criteria for token selection during self-attention blocks. 2. Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency. 3. Small-Scale High-Quality GUI Instruction-Following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances. With the above components, our model, a lightweight 2B model using 256K data, achieves a strong 75.1% accuracy in zero-shot screenshot grounding. Its UI-guided token selection further reduces 33% of redundant visual tokens during training and speeds up performance by 1.4×. Navigation experiments across web, mobile, and online environments further underscore the effectiveness and potential of our model in advancing GUI visual agents.