SAM-I2V: Upgrading SAM to Support Promptable Video Segmentation with Less than 0.2% Training Cost
{kind=link}
Abstract
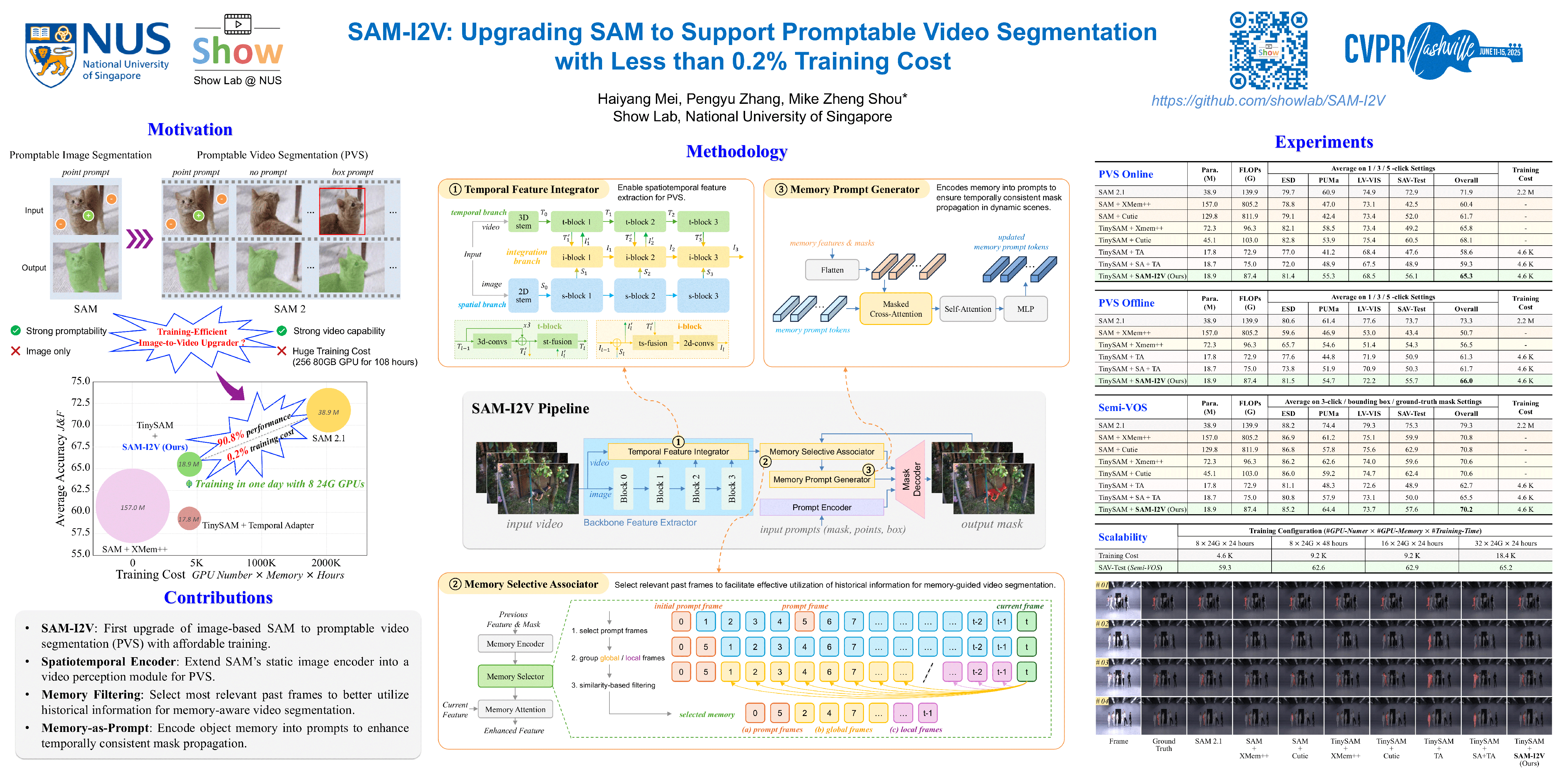
Foundation models like the Segment Anything Model (SAM) have significantly advanced promptable image segmentation in computer vision. However, extending these capabilities to videos presents substantial challenges, particularly in ensuring precise and temporally consistent mask propagation in dynamic scenes. SAM 2 attempts to address this by training a model on massive image and video data from scratch to learn complex spatiotemporal associations, resulting in huge training costs that hinder research and practical deployment. In this paper, we introduce SAM-I2V, an effective image-to-video upgradation method for cultivating a promptable video segmentation (PVS) model. Our approach strategically upgrades the pre-trained SAM to support PVS, significantly reducing training complexity and resource requirements. To achieve this, we introduce two key innovations: (i) a novel memory-as-prompt mechanism that leverages object memory to ensure segmentation consistency across dynamic scenes; and (ii) a new memory filtering mechanism designed to select the most informative historical information, thereby avoiding errors and noise interference and enhancing the stability of segmentation. Comprehensive experiments demonstrate that our method achieves over 90\% of SAM 2's performance while using only 0.2\% of its training cost. Our work presents a resource-efficient pathway to PVS, lowering barriers for further research in PVS model design and enabling broader applications and advancements in the field.