CoE: Chain-of-Explanation via Automatic Visual Concept Circuit Description and Polysemanticity Quantification
{kind=link}
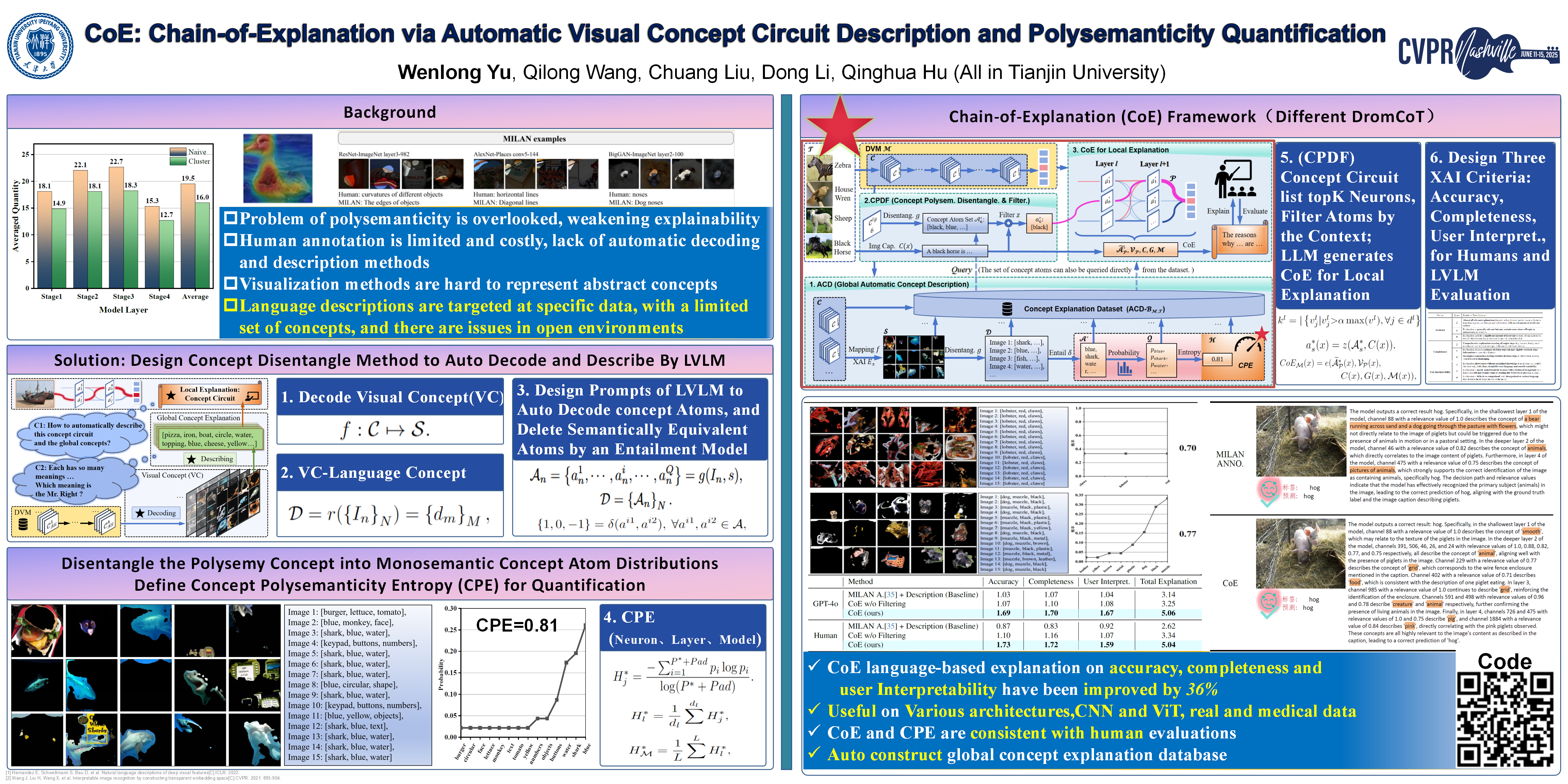
Abstract
Explainability is a critical factor influencing the wide deployment of deep vision models (DVMs). Concept-based post-hoc explanation methods can provide both global and local insights into model decisions. However, current methods in this field face challenges in that they are inflexible to automatically construct accurate and sufficient linguistic explanations for global concepts and local circuits. Particularly, the intrinsic polysemanticity in semantic Visual Concepts (VCs) impedes the interpretability of concepts and DVMs, which is underestimated severely. In this paper, we propose a Chain-of-Explanation (CoE) approach to address these issues. Specifically, CoE automates the decoding and description of VCs to construct global concept explanation datasets. Further, to alleviate the effect of polysemanticity on model explainability, we design a concept polysemanticity disentanglement and filtering mechanism to distinguish the most contextually relevant concept atoms. Besides, a Concept Polysemanticity Entropy (CPE), as a measure of model interpretability, is formulated to quantify the degree of concept uncertainty. The modeling of deterministic concepts is upgraded to uncertain concept atom distributions. Ultimately, CoE automatically enables linguistic local explanations of the decision-making process of DVMs by tracing the concept circuit. GPT-4o and human-based experiments demonstrate the effectiveness of CPE and the superiority of CoE, achieving an average absolute improvement of 36% in terms of explainability scores.