DIFFER: Disentangling Identity Features via Semantic Cues for Clothes-Changing Person Re-ID
{kind=link}
Abstract
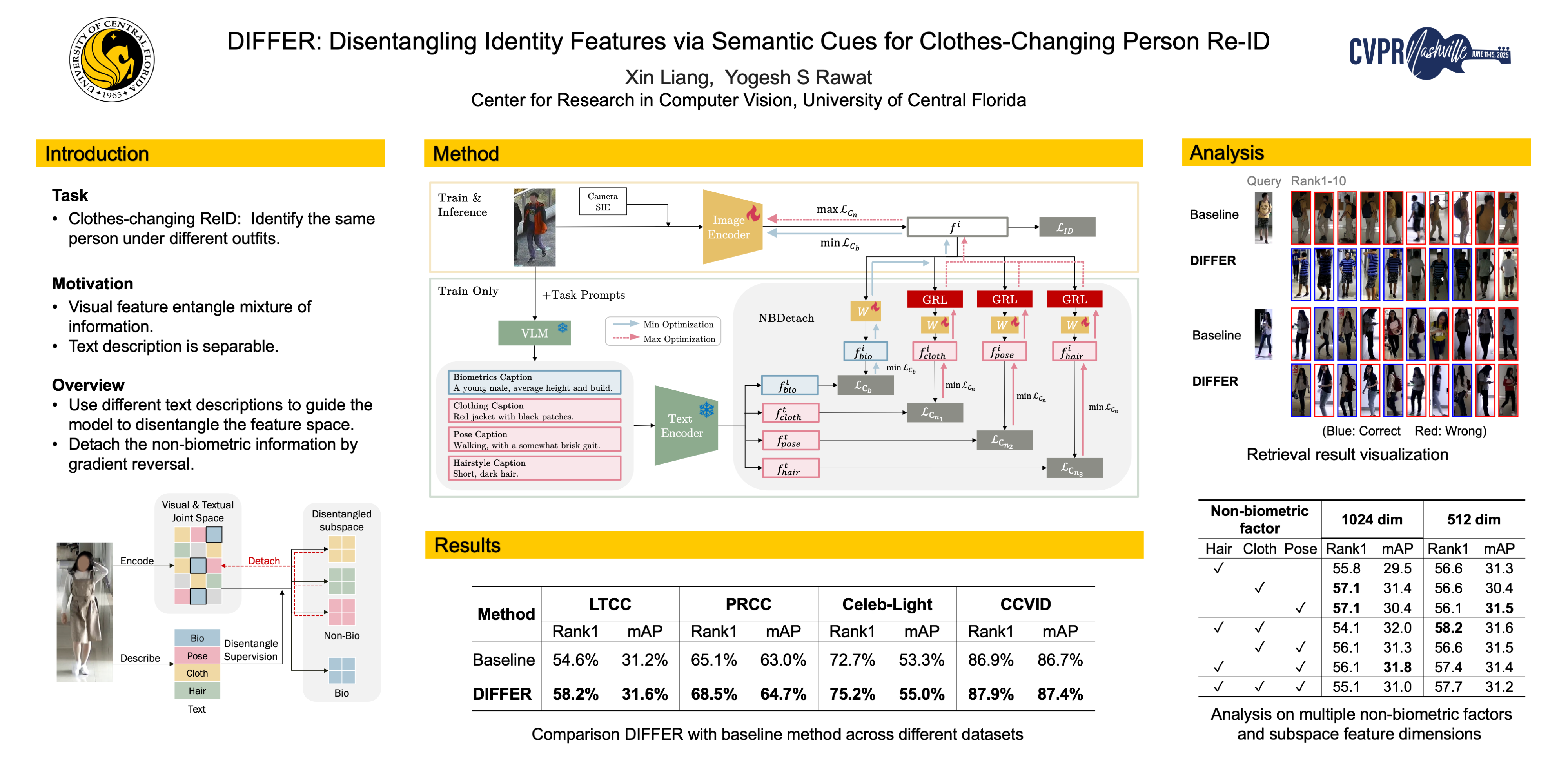
In this work, we focus on clothes-changing person re-identification (CC-ReID), which aims to recognize individuals under different clothing scenarios. Current CC-ReID approaches either concentrate on modeling body shape using additional modalities including silhouette, pose, and body mesh, potentially causing the model to overlook other critical biometric traits such as gender, age, and style, or they incorporate supervision through additional labels that the model tries to disregard or emphasize, such as clothing or personal attributes. However, these annotations are discrete in nature and do not capture comprehensive descriptions.In this work, we propose DIFFER: Disentangle Identity Features From Entangled Representations, a novel adversarial learning method that leverages textual descriptions to disentangle identity features. Recognizing that image features inherently mix inseparable information, DIFFER introduces NBDetach, a mechanism that utilizes the separable nature of text descriptions as disentanglement supervision to partition the feature space into distinct subspaces, enabling the effective separation of identity-related features from non-biometric features through gradient reversal. We evaluate DIFFER on 4 different benchmark datasets (LTCC, PRCC, CelebreID-Light, and CCVID) to demonstrate its effectiveness and provide state-of-the-art performance across all the benchmarks. DIFFER consistently outperforms the baseline method, with improvements in top-1 accuracy of 3.6\% on LTCC, 3.4\% on PRCC, 2.5\% on CelebReID-Light, and 1\% on CCVID. The code will be made publicly available.