Learning Partonomic 3D Reconstruction from Image Collections
{kind=link}
Abstract
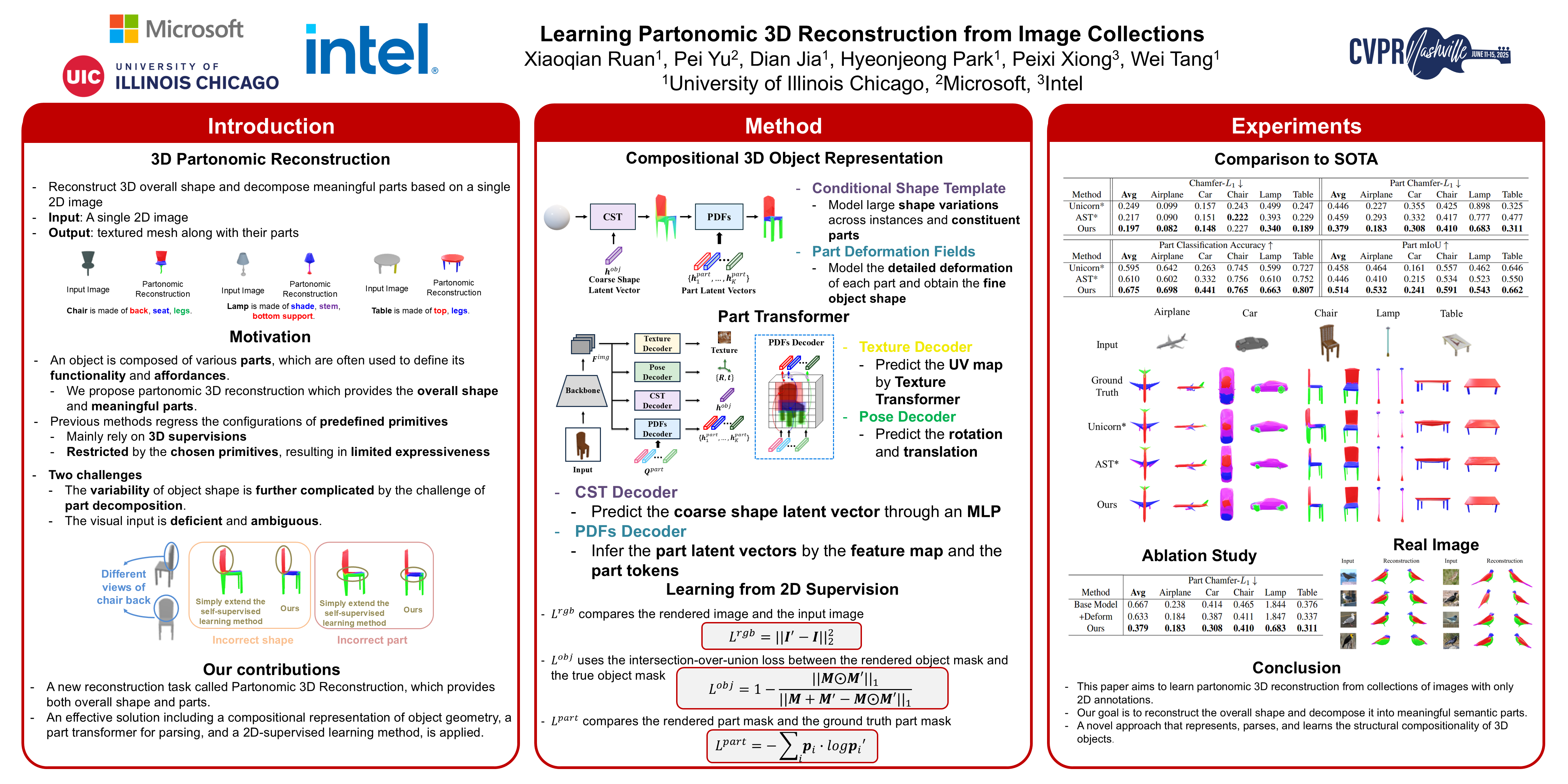
Reconstructing the 3D shape of an object from a single-view image is a fundamental task in computer vision. Recent advances in differentiable rendering have enabled 3D reconstruction from image collections using only 2D annotations. However, these methods mainly focus on whole-object reconstruction and overlook object partonomy, which is essential for intelligent agents interacting with physical environments. This paper aims at learning partonomic 3D reconstruction from collections of images with only 2D annotations. Our goal is not only to reconstruct the shape of an object from a single-view image but also to decompose the shape into meaningful semantic parts. To handle the expanded solution space and frequent part occlusions in single-view images, we introduce a novel approach that represents, parses, and learns the structural compositionality of 3D objects. This approach comprises: (1) a compact and expressive compositional representation of object geometry, achieved through disentangled modeling of large shape variations, constituent parts, and detailed part deformations as multi-granularity neural fields; (2) a part transformer that recovers precise partonomic geometry and handles occlusions, through effective part-to-pixel grounding and part-to-part relational modeling; and (3) a self-supervised method that jointly learns the compositional representation and part transformer, by bridging object shape and parts, image synthesis, and differentiable rendering. Extensive experiments on ShapeNetPart, PartNet, and CUB-200-2011 demonstrate the effectiveness of our approach on both overall and partonomic reconstruction. We will make our code and data publicly available.