Navigation World Models
{kind=link}
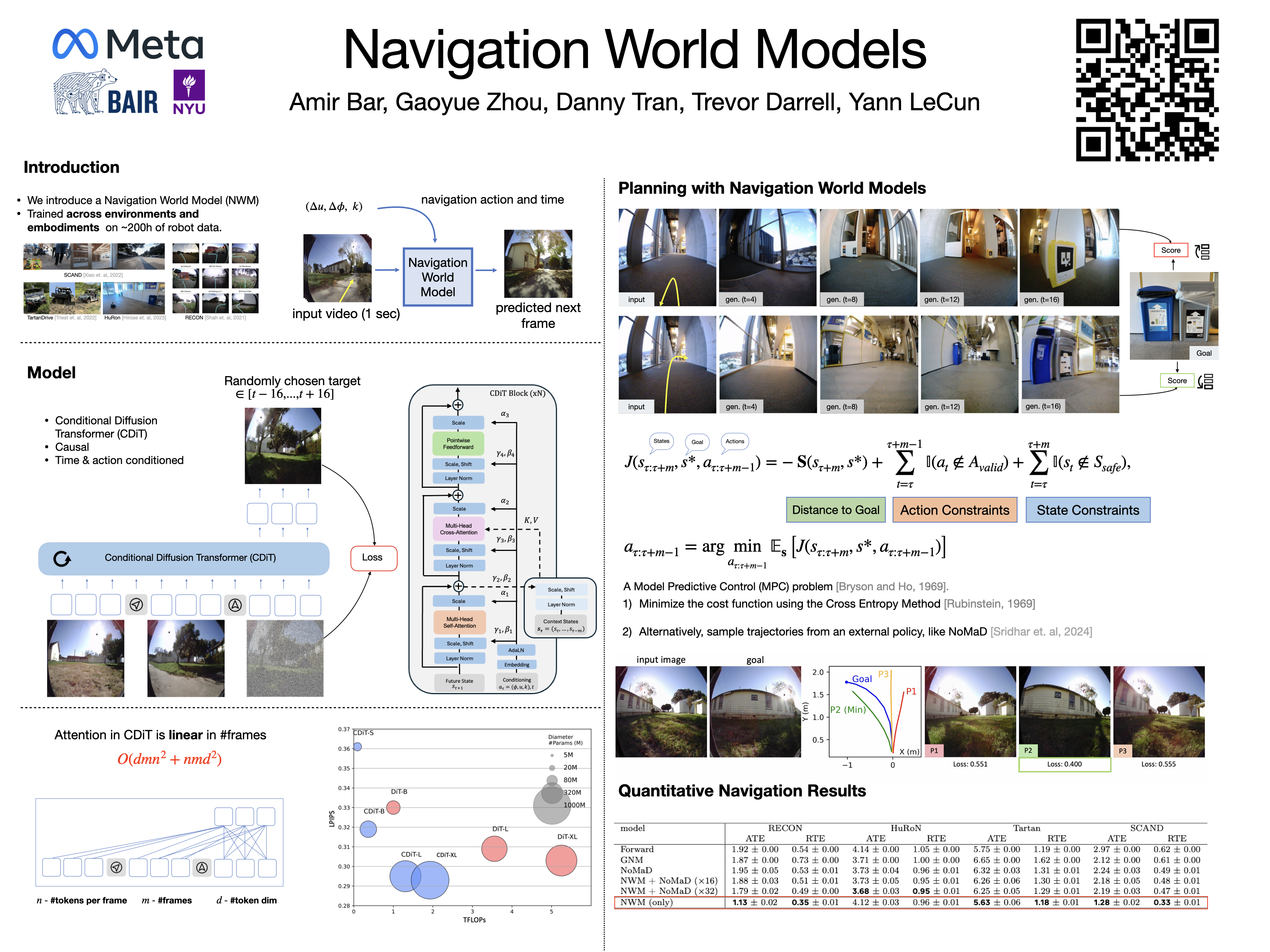
Abstract
Navigation is a fundamental skill of agents with visual-motor capabilities. We propose a Navigation World Model (NWM), a controllable video generation model that predicts the future visual observation given the past observations and navigation actions. NWM is a Conditional Diffusion Transformer (CDiT) trained on the video footage of robots as well as unlabeled egocentric video data. We scale the model up to 1B parameters and train it over human and robot agents data from numerous environments and embodiments. Our model scales favorably on known and unknown environments and can leverage unlabeled egocentric video data. NWM exhibits improved navigation planning skills either by planning from scratch or by ranking proposals from an external navigation policy. Compared to existing supervised navigation models which are ``hard coded'', NWM can incorporate new constraints when planning trajectories. NWM learns visual priors that enable it to imagine navigation trajectories based on just a single input image.