Do We Always Need the Simplicity Bias? Looking for Optimal Inductive Biases in the Wild
{kind=link}
Abstract
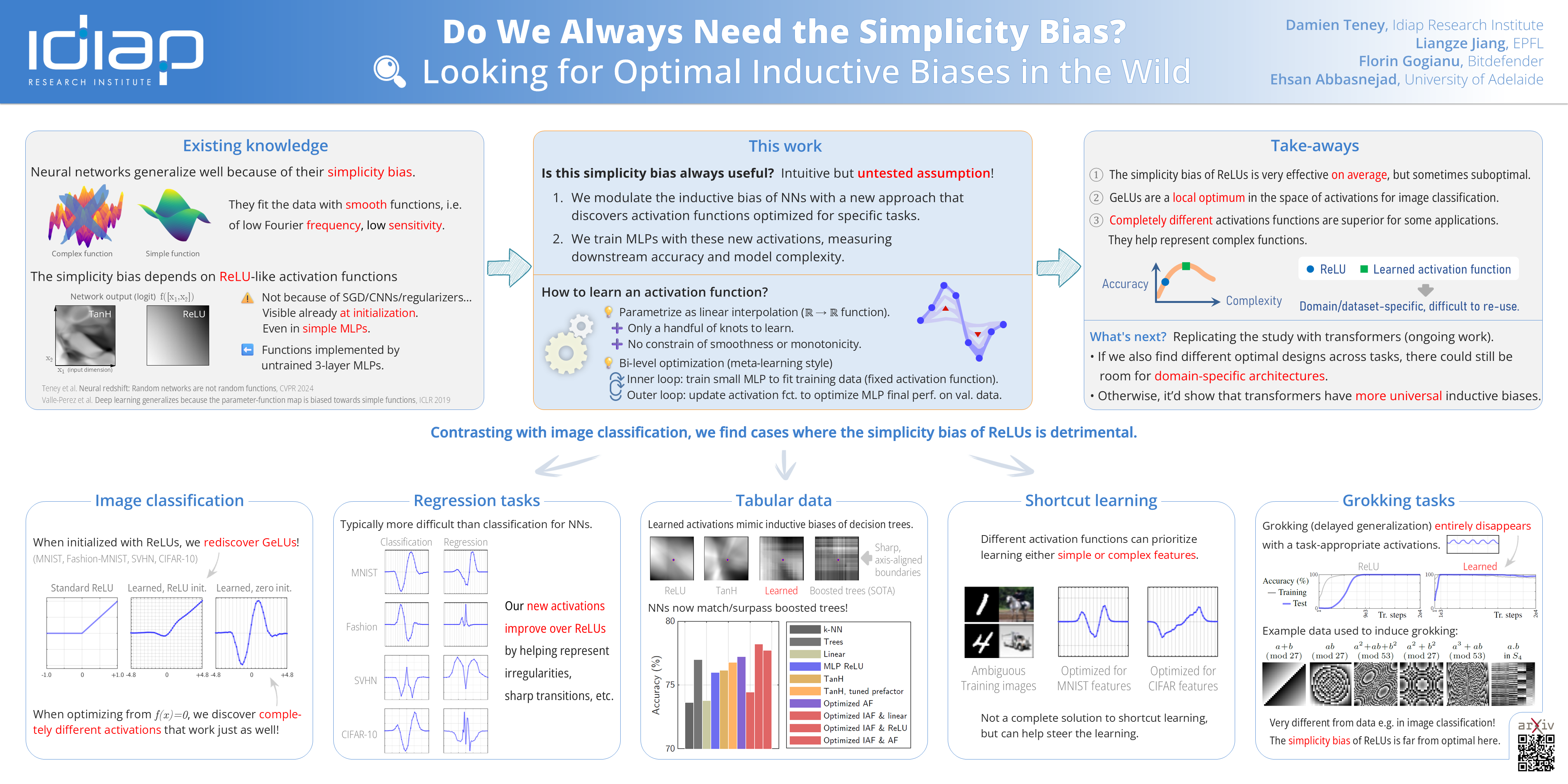
Common choices of architecture give neural networks a preference for fitting data with simple functions. This simplicity bias is known as key to their success. This paper explores the limits of this assumption. Building on recent work that showed that activation functions are the origin of the simplicity bias (Teney, 2024), we introduce a method to meta-learn activation functions to modulate this bias.Findings. We discover multiple tasks where the assumption of simplicity is inadequate, and standard ReLU architectures are therefore suboptimal. In these cases, we find activation functions that perform better by inducing a prior of higher complexity. Interestingly, these cases correspond to domains where neural networks have historically struggled: tabular data, regression tasks, cases of shortcut learning, and algorithmic grokking tasks. In comparison, the simplicity bias proves adequate on image tasks, where learned activations are nearly identical to ReLUs and GeLUs.Implications. (1) Contrary to common belief, the simplicity bias is not universally useful. There exist real tasks where it is suboptimal. (2) The suitability of ReLU models for image classification is not accidental. (3) The success of ML ultimately depends on the adequacy between data and architectures, and there may be benefits for architectures tailored to specific distributions of tasks.