Bootstrap Your Own Views: Masked Ego-Exo Modeling for Fine-grained View-invariant Video Representations
{kind=link}
Abstract
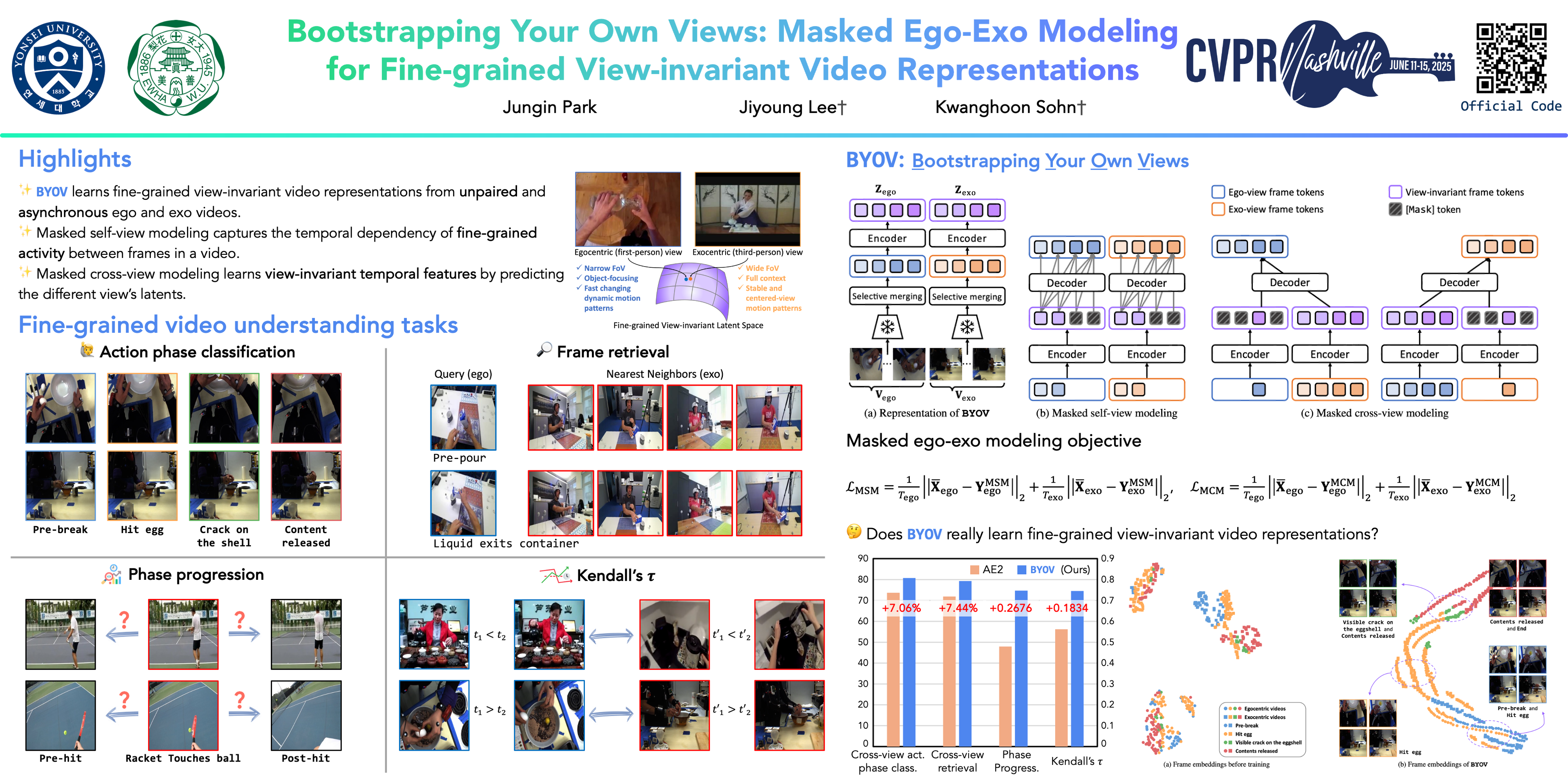
View-invariant representation learning from egocentric (first-person, ego) and exocentric (third-person, exo) videos is a promising approach toward generalizing video understanding systems across multiple perspectives. However, this area has been underexplored due to the substantial differences in perspective, motion patterns, and context between ego and exo views. In this paper, we propose a novel fine-grained view-invariant video representation learning from unpaired ego-exo videos, called Bootstrap Your Own Videos (BYOV). We highlight the importance of capturing the compositional nature of human actions as a basis for robust cross-view understanding. To this end, we introduce a masked ego-exo modeling that promotes both causal temporal dynamics and cross-view alignment. Specifically, self-causal masking and cross-view masking predictions are learned concurrently to facilitate view-invariant and powerful representations across viewpoints. Experimental results demonstrate that our BYOV significantly surpasses existing approaches with notable gains across all metrics in four downstream ego-exo video tasks. The code is available at \url{https://anonymous.4open.science/r/byov-D967.