MedUnifier: Unifying Vision-and-Language Pre-training on Medical Data with Vision Generation Task using Discrete Visual Representations
{kind=link}
Abstract
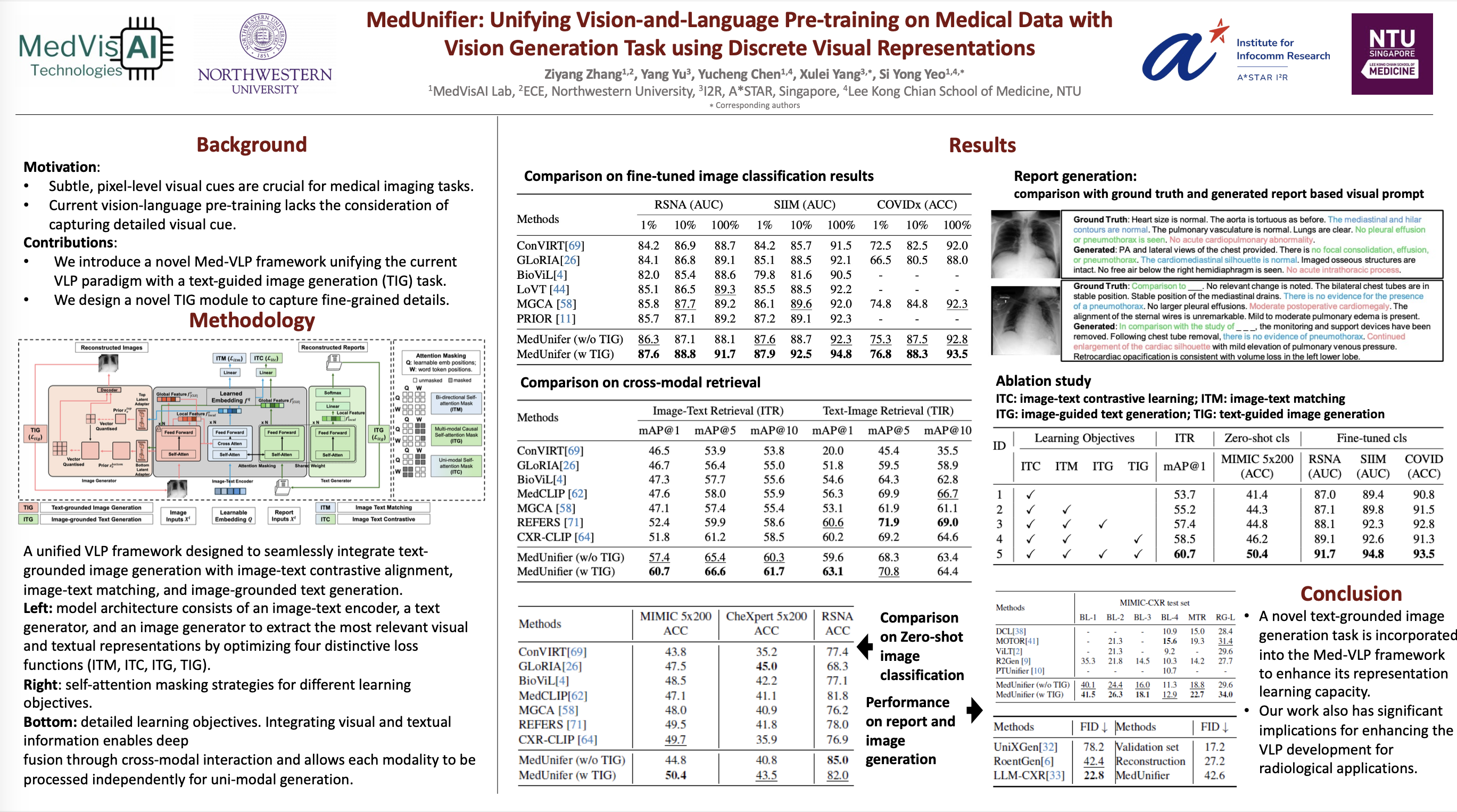
Despite significant progress in Vision-Language Pre-training (VLP), existing VLP approaches predominantly emphasize feature extraction and cross-modal comprehension, with limited attention to generating or transforming visual content. This misalignment constrains the model's ability to synthesize coherent and novel visual representations from textual prompts, thereby reducing the effectiveness of multi-modal learning. In this work, we propose \textbf{MedUnifier}, a unified vision-language pre-training framework tailored for medical data. MedUnifier seamlessly integrates text-grounded image generation capabilities with multi-modal learning strategies, including image-text contrastive alignment, image-text matching and image-grounded text generation. Unlike traditional methods that reply on continuous visual representations, our approach employs visual vector quantization, which not only facilitates a more cohesive learning strategy for cross-modal understanding but also enhances multi-modal generation quality by effectively leveraging discrete representations. Our framework's effectiveness is evidenced by the experiments on established benchmarks, including uni-modal tasks (supervised fine-tuning), cross-modal tasks (image-text retrieval and zero-shot image classification), and multi-modal tasks (medical report generation, image synthesis), where it achieves state-of-the-art performance across various tasks. It also offers a highly adaptable tool designed for a broad spectrum of language and vision tasks in healthcare, marking advancement toward the development of a genuinely generalizable AI model for medical contexts.