DeepCompress-ViT: Rethinking Model Compression to Enhance Efficiency of Vision Transformers at the Edge
Sabbir Ahmed ⋅ Abdullah Al Arafat ⋅ Deniz Najafi ⋅ Akhlak Mahmood ⋅ Mamshad Nayeem Rizve ⋅ Mohaiminul Al Nahian ⋅ RANYANG ZHOU ⋅ Shaahin Angizi ⋅ Adnan Rakin Rakin
2025 Poster
{kind=link}
Abstract
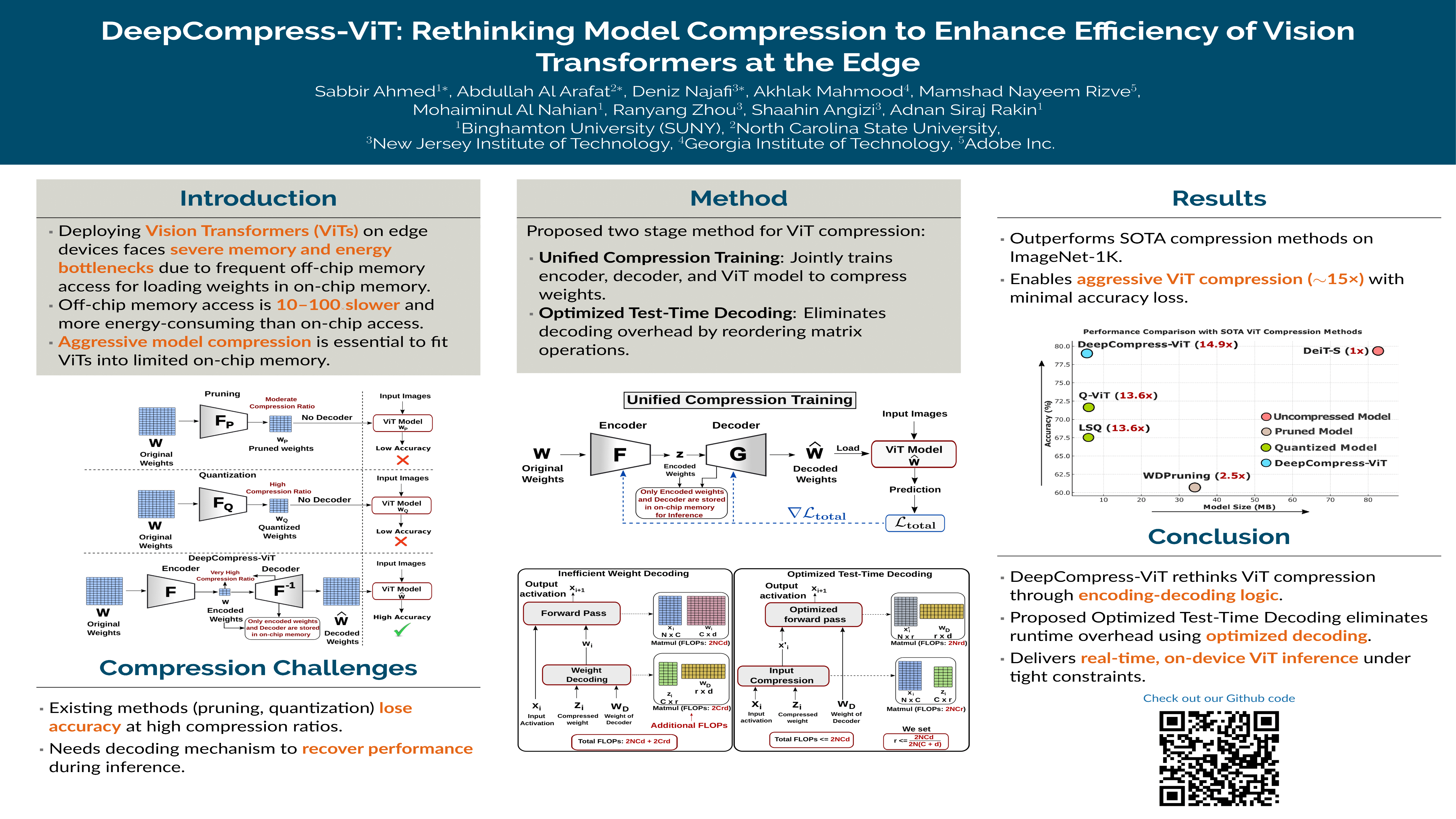
Vision Transformers (ViTs) excel in tackling complex vision tasks, yet their substantial size poses significant challenges for applications on resource-constrained edge devices. The increased size of these models leads to higher overhead (e.g., energy, latency) when transmitting model weights between the edge device and the server. Hence, ViTs are not ideal for edge devices where the entire model may not fit on the device. Current model compression techniques often achieve high compression ratios at the expense of performance degradation, particularly for ViTs. To overcome the limitations of existing works, we rethink model compression strategy for ViTs from first principle approach and develop an orthogonal strategy called DeepCompress-ViT. The objective of the DeepCompress-ViT is to encode the model weights to a highly compressed encoded representation using a novel training method, denoted as Unified Compression Training (UCT). Proposed UCT is accompanied by a decoding mechanism during inference, which helps to gain any loss of accuracy due to high compression ratio. We further optimize this decoding step by re-ordering the decoding operation using associative property of matrix multiplication, ensuring that the compressed weights can be decoded during inference without incurring any computational overhead. Our extensive experiments across multiple ViT models on modern edge devices show that DeepCompress-ViT can successfully compress ViTs at high compression ratios ($>14\times$). DeepCompress-ViT enables the entire model to be stored on the edge device, resulting in unprecedented reductions in energy consumption ($>1500\times$) and latency ($>200\times$) for edge ViT inference.
Chat is not available.
Successful Page Load