Yo’Chameleon: Personalized Vision and Language Generation
{kind=link}
Abstract
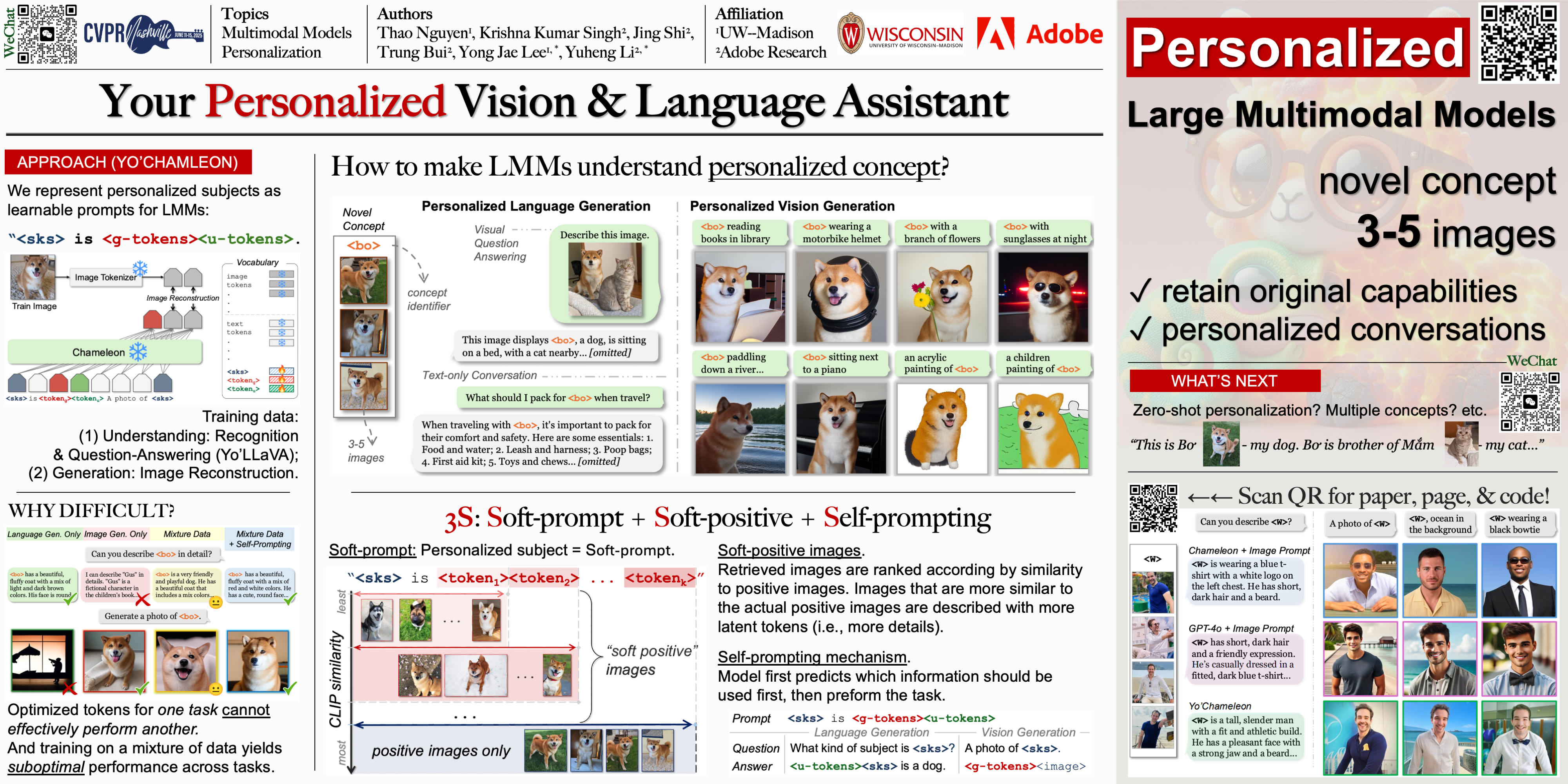
Large Multimodal Models (e.g., GPT-4, Gemini, Chameleon) have evolved into powerful tools with millions of users.However, they remain generic models and lack personalized knowledge of specific user concepts.Previous work has explored personalization for text generation, yet it remains unclear how these methods can be adapted to new modalities, such as image generation.In this paper, we introduce Yo'Chameleon, the first attempt to study personalization for large multimodal models.Given 3-5 images of a particular concept, Yo'Chameleon leverages soft-prompt tuning to embed subject-specific information to (i) answer questions about the subject and (ii) recreate pixel-level details to produce images of the subject in new contexts. Yo'Chameleon is trained with (i) a self-prompting optimization mechanism to balance performance across multiple modalities, and (ii) a ``soft-positive" image generation approach to enhance image quality in a few-shot setting.