Revisiting Audio-Visual Segmentation with Vision-Centric Transformer
{kind=link}
Abstract
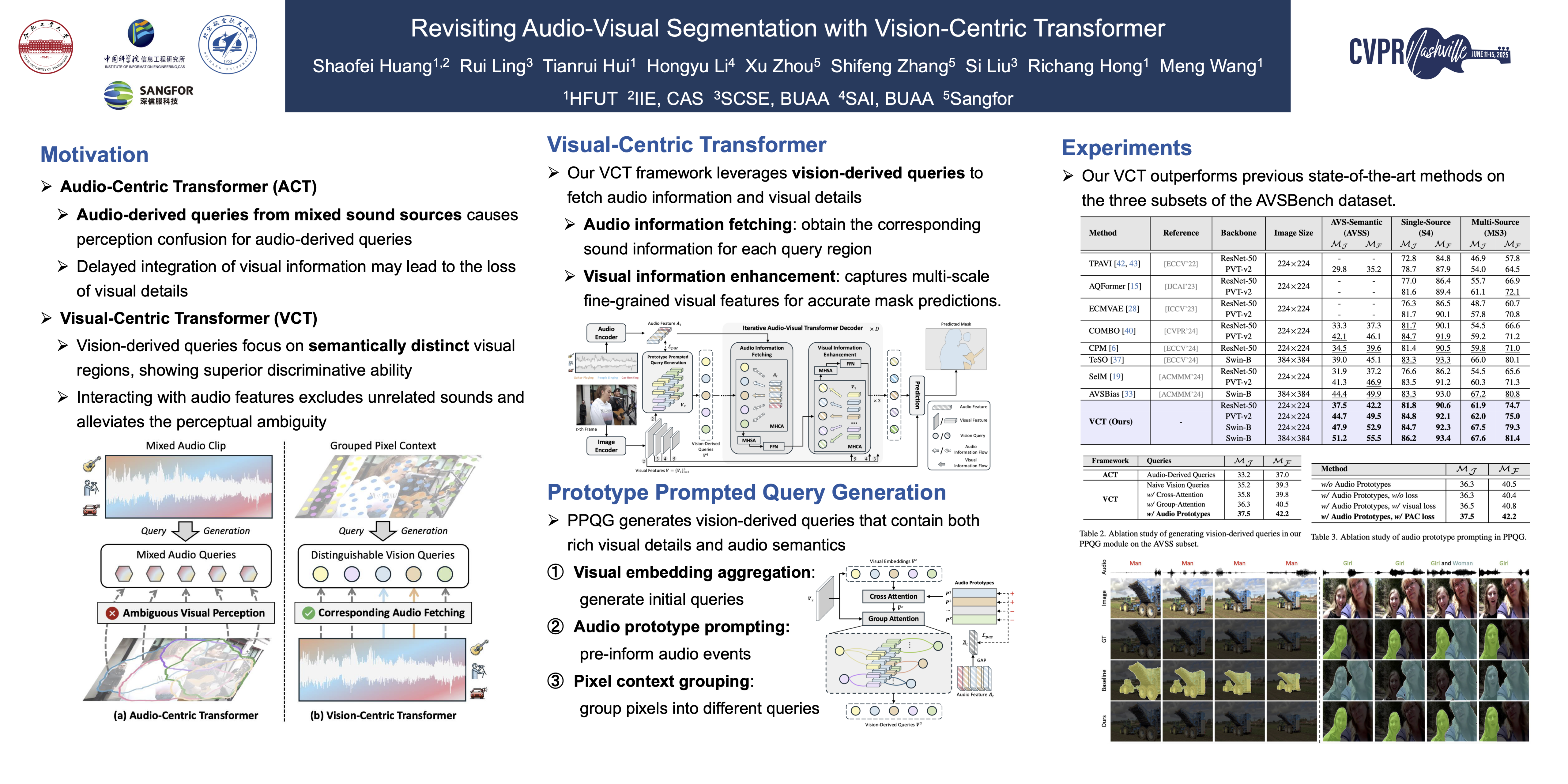
Audio-Visual Segmentation (AVS) aims to segment sound-producing objects in video frames based on the associated audio signal. Prevailing AVS methods typically adopt an audio-centric Transformer architecture, where object queries are derived from audio features. However, audio-centric Transformers suffer from two limitations: perception ambiguity caused by the mixed nature of audio, and weakened dense prediction ability due to visual detail loss. To address these limitations, we propose a new Vision-Centric Transformer (VCT) framework that leverages vision-derived queries to iteratively fetch corresponding audio and visual information, enabling queries to better distinguish between different sounding objects from mixed audio and accurately delineate their contours. Additionally, we also introduce a Prototype Prompted Query Generation (PPQG) module within our VCT framework to generate vision-derived queries that are both semantically aware and visually rich through audio prototype prompting and pixel context grouping, facilitating audio-visual information aggregation. Extensive experiments demonstrate that our VCT framework achieves new state-of-the-art performances on three subsets of the AVSBench dataset.