Learning from Streaming Video with Orthogonal Gradients
{kind=link}
Abstract
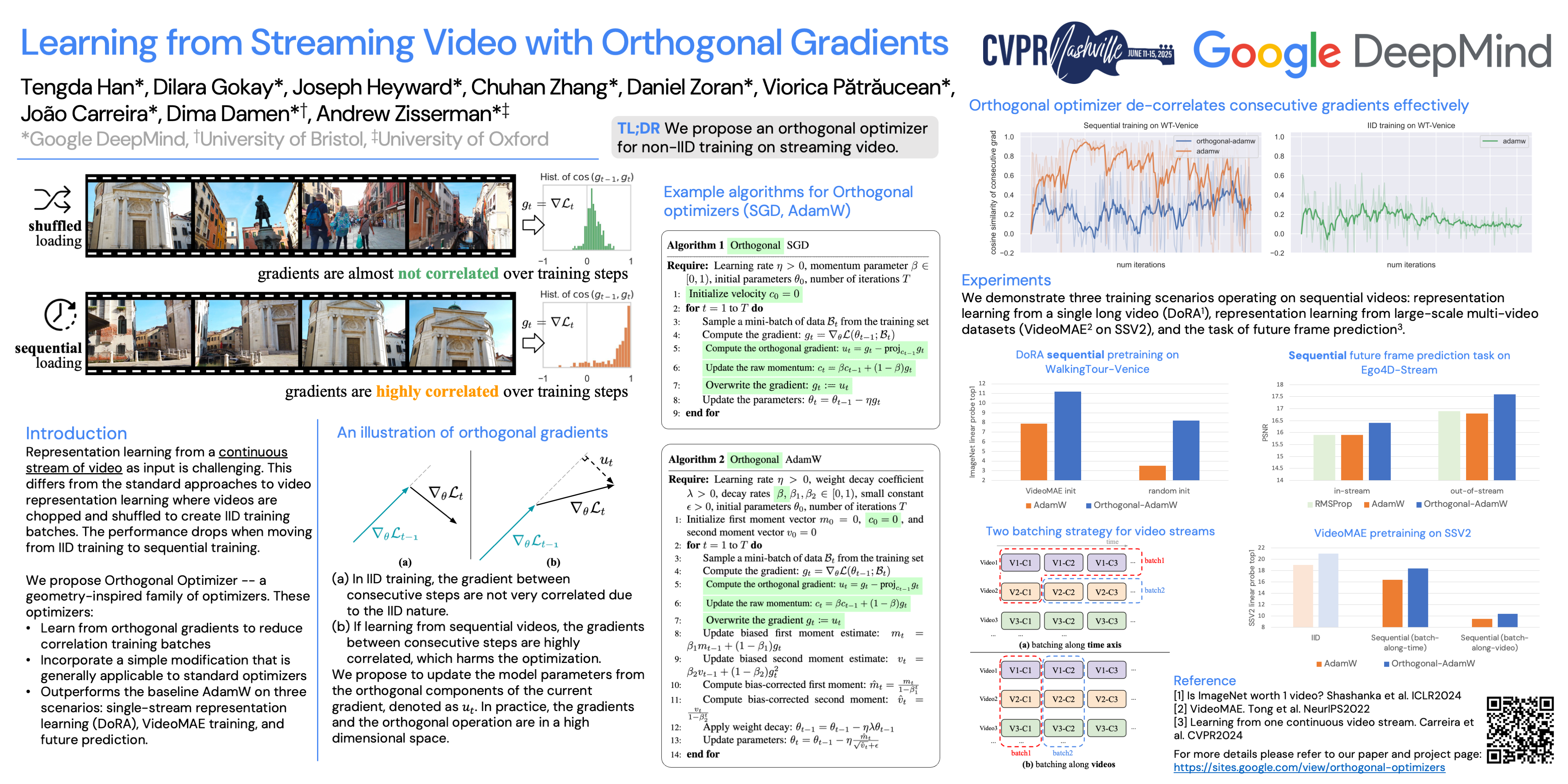
We address the challenge of representation learning from a continuous stream of video as input, in a self-supervised manner.This differs from the standard approaches to video learning where videos are chopped and shuffled during training in order to create a non-redundant batch that satisfies the independently and identically distributed (IID) sample assumption expected by conventional training paradigms.When videos are only available as a continuous stream of input, the IID assumption is evidently broken, leading to poor performance.We demonstrate the drop in performance when moving from shuffled to sequential learning on three systems: the one-video representation learning method DoRA, standard VideoMAE, and the task of future video prediction.To address this drop, we propose a geometric modification to standard optimizers, to decorrelate batches by utilising orthogonal gradients during training.The proposed modification can be applied to any optimizer -- we demonstrate it with Stochastic Gradient Descent (SGD) and AdamW.Our proposed orthogonal optimizer allows models trained from streaming videos to alleviate the drop in representation learning performance, as evaluated on downstream tasks.On three scenarios (DoRA, VideoMAE, future prediction),we show our orthogonal optimizer outperforms the strong AdamW all three cases.