Cross-Modal 3D Representation with Multi-View Images and Point Clouds
{kind=link}
Abstract
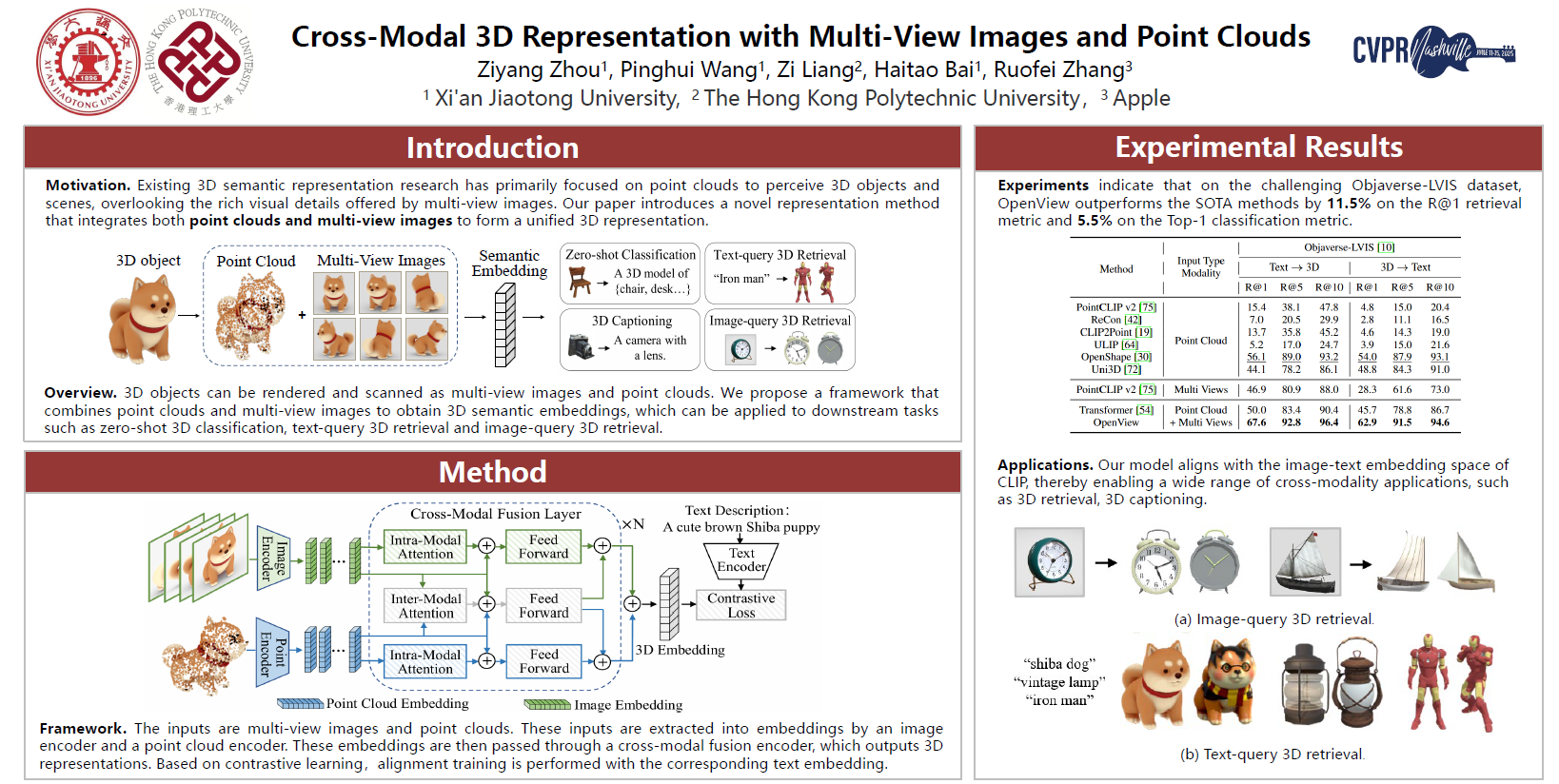
The advancement of 3D understanding and representation is a crucial step for the next phase of autonomous driving, robotics, augmented and virtual reality, 3D gaming and 3D e-commerce products. However, existing research has primarily focused on point clouds to perceive 3D objects and scenes, overlooking the rich visual details offered by multi-view images, thereby limiting the potential of 3D semantic representation. This paper introduces OpenView, a novel representation method that integrates both point clouds and multi-view images to form a unified 3D representation. OpenView comprises a unique fusion framework, sequence-independent modeling, a cross-modal fusion encoder, and a progressive hard learning strategy. Our experiments demonstrate that OpenView outperforms the state-of-the-art by 11.5% and 5.5% on the R@1 metric for cross-modal retrieval and the Top-1 metric for zero-shot classification tasks, respectively. Furthermore, we showcase some applications of OpenView: 3D retrieval, 3D captioning and hierarchical data clustering, highlighting its generality in the field of 3D representation learning.