Cross-Modal Distillation for 2D/3D Multi-Object Discovery from 2D Motion
Saad Lahlali ⋅ Sandra Kara ⋅ Hejer AMMAR ⋅ Florian Chabot ⋅ Nicolas Granger ⋅ Hervé Le Borgne ⋅ Quoc Cuong PHAM
2025 Poster
{kind=link}
Abstract
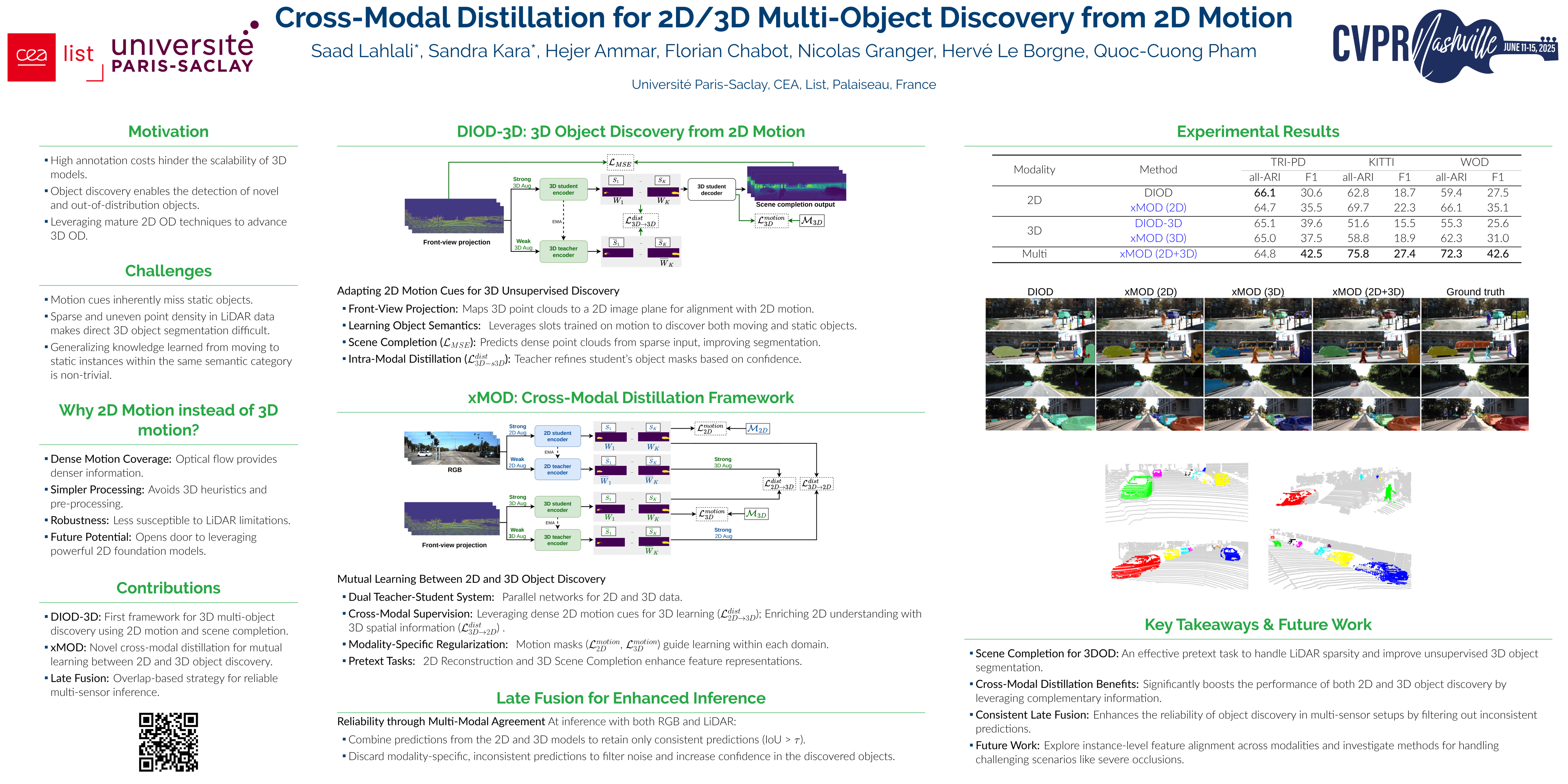
Object discovery, which refers to the process of localizing objects without human annotations, has gained significant attention in recent years. Despite the growing interest in this task for 2D images, it remains under-explored in 3D data, where it is typically restricted to localizing a single object. Our work leverages the latest advances in 2D object discovery and proposes a novel framework to bridge the gap between 2D and 3D modalities. Our primary contributions are twofold: (i) we propose DIOD-3D, the first method for multi-object discovery in 3D data, using scene completion as a supporting task to enable dense object discovery from sparse inputs; (ii) we develop xMOD, a cross-modal training framework that integrates both 2D and 3D data, using objective functions tailored to accommodate the sparse nature of 3D data. xMOD uses a teacher-student training across the two modalities to reduce confirmation bias by leveraging the domain gap. During inference, the model supports RGB-only, point cloud-only and multi-modal inputs. We validate the approach in the three settings, on synthetic photo-realistic and real-world datasets. Notably, our approach yields a substantial improvement in $F1@50$ score compared with the state of the art by $8.7$ points in real-world scenarios, demonstrating the potential of cross-modal learning in enhancing object discovery systems without additional annotations\footnote{Code available upon acceptance}.
Chat is not available.
Successful Page Load