SALAD: Skeleton-aware Latent Diffusion for Text-driven Motion Generation and Editing
{kind=link}
Abstract
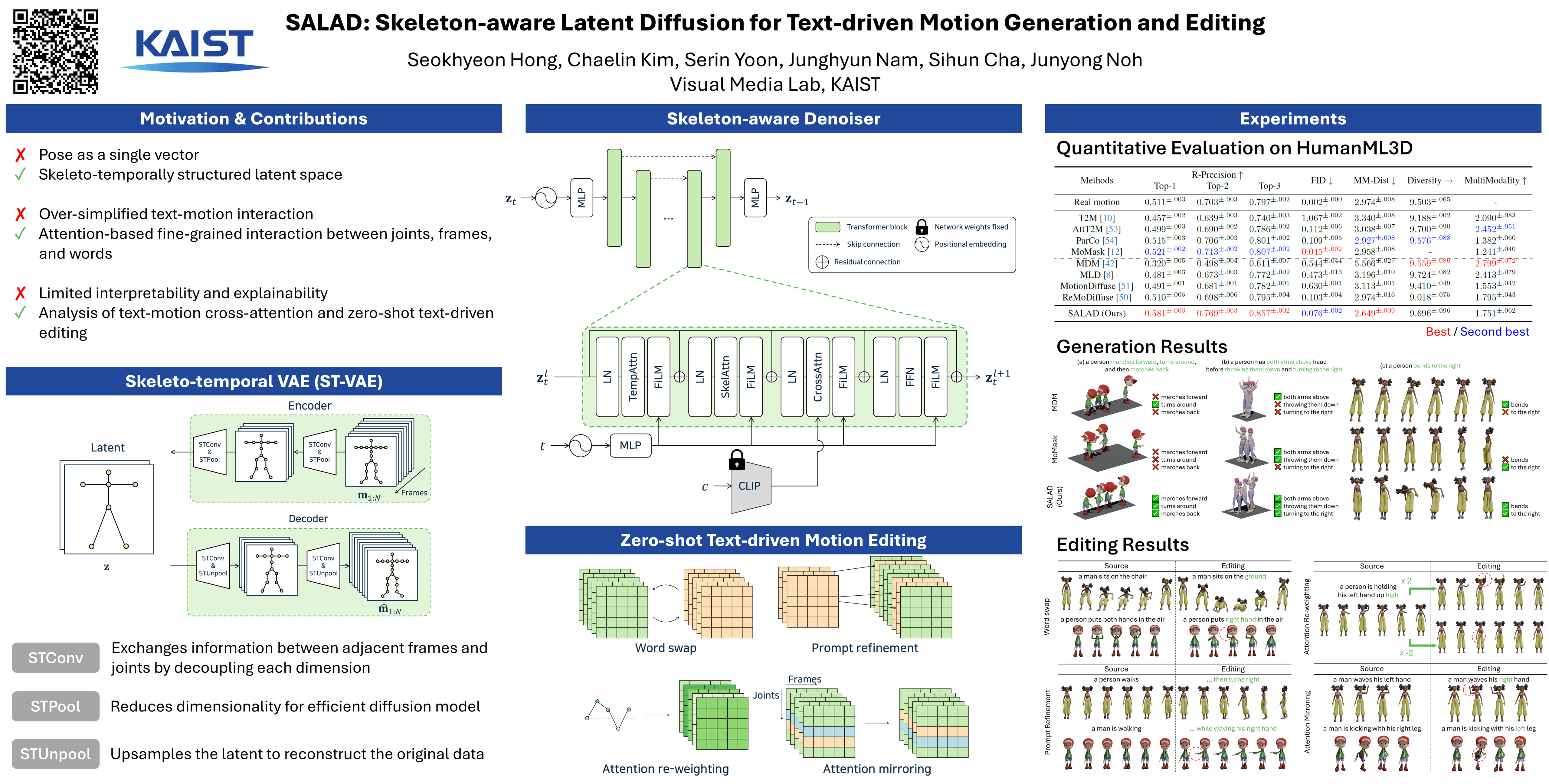
Text-driven motion generation has been significantly advanced with the rise of denoising diffusion models.However, previous methods often oversimplify representations for the skeletal joints, temporal frames, and textual words, limiting their ability to fully capture the information within each modality and their interactions.Moreover, when using pre-trained models for downstream tasks, such as editing, they typically require additional efforts, including manual interventions, optimization, or fine-tuning.In this paper, we introduce a skeleton-aware latent diffusion~(SALAD), a model that explicitly captures the intricate inter-relationships between joints, frames, and words.Furthermore, by leveraging cross-attention maps produced during the generation process, we enable the first zero-shot text-driven motion editing using a pre-trained SALAD model, requiring no additional user input beyond text prompts.Our approach significantly outperforms previous methods in terms of text-motion alignment without compromising generation quality, and demonstrates practical versatility by providing diverse editing capabilities beyond generation.