3D-AVS: LiDAR-based 3D Auto-Vocabulary Segmentation
{kind=link}
Abstract
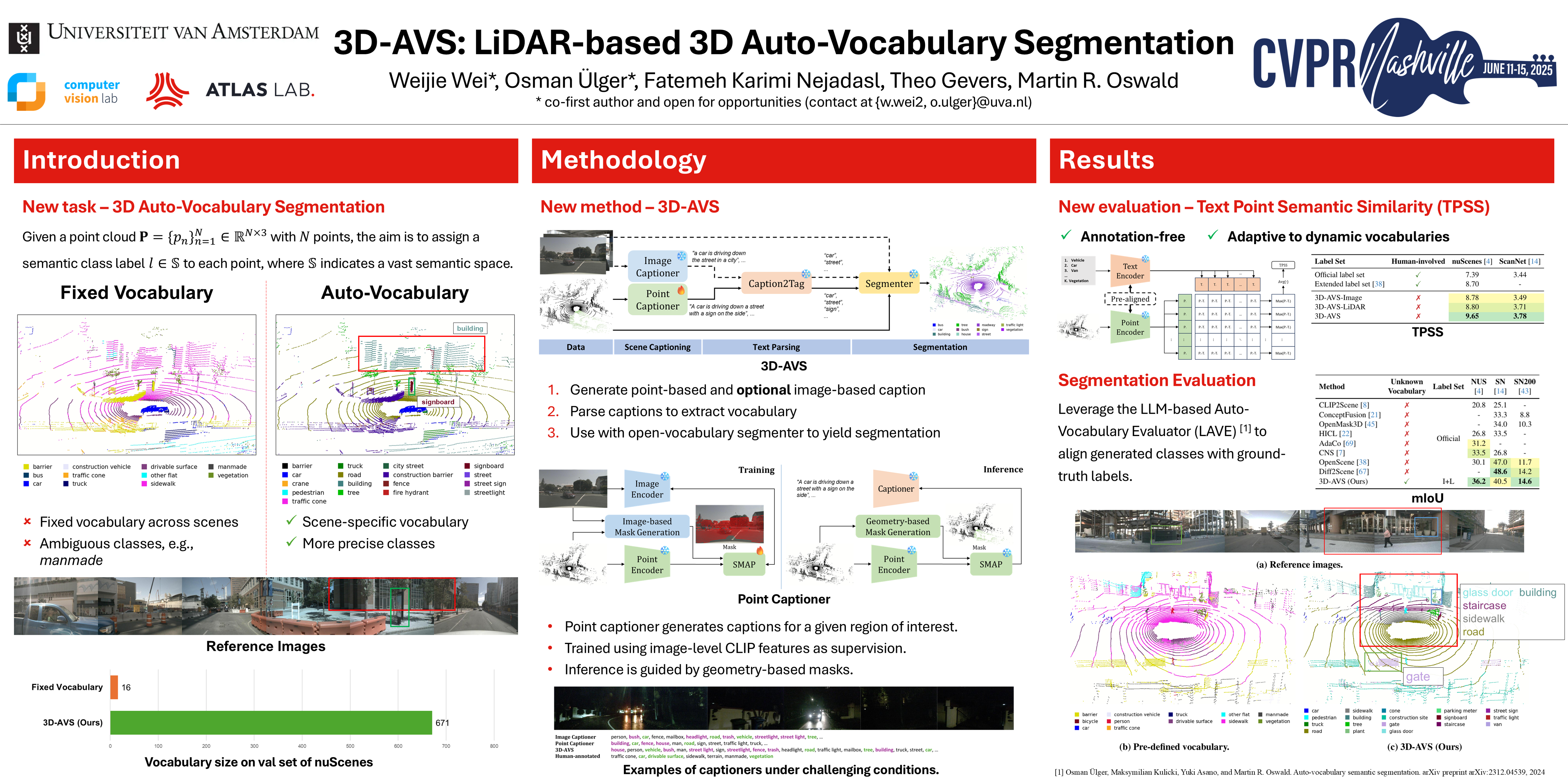
Open-vocabulary segmentation methods offer promising capabilities in detecting unseen object categories, but the vocabulary must be known and needs to be provided by a human, either via a text prompt or pre-labeled datasets, thus limiting their scalability. We propose 3D-AVS, a method for Auto-Vocabulary Segmentation of 3D point clouds for which the vocabulary is unknown and auto-generated for each input at runtime, thus eliminating the human in the loop and typically providing a substantially larger vocabulary for richer annotations. 3D-AVS first recognizes semantic entities from image or point cloud data and then segments all points with the automatically generated vocabulary. Our method incorporates both image-based and point-based recognition, enhancing robustness under challenging lighting conditions where geometric information from LiDAR is especially valuable. Our point-based recognition features a Sparse Masked Attention Pooling (SMAP) module to enrich the diversity of recognized objects. To address the challenges of evaluating unknown vocabularies and avoid annotation biases from label synonyms, hierarchies, or semantic overlaps, we introduce the annotation-free Text-Point Semantic Similarity (TPSS) metric for assessing segmentation quality. Our evaluations on nuScenes and ScanNet demonstrate our method's ability to generate semantic classes with accurate point-wise segmentations.