Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training
{kind=link}
Abstract
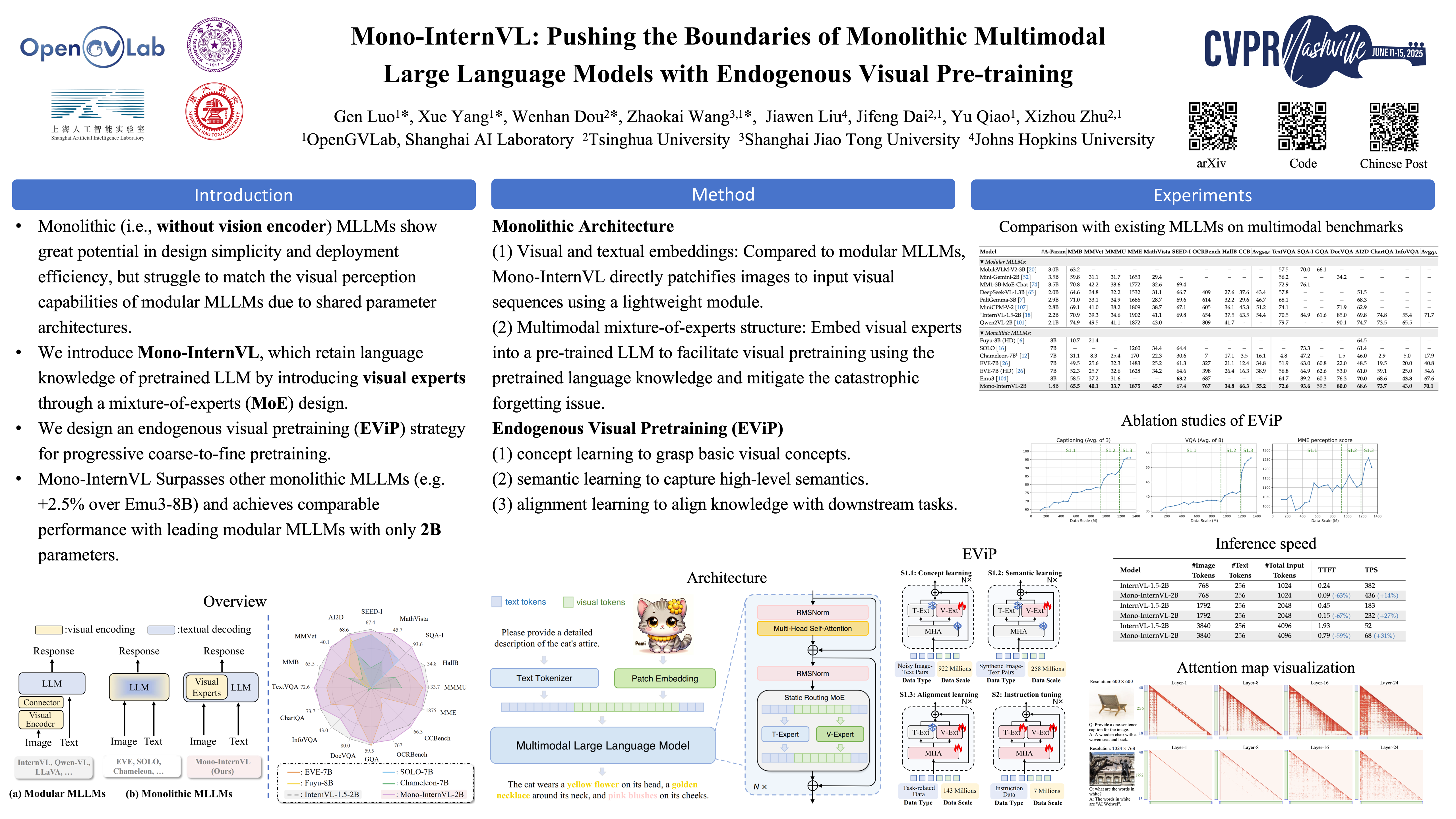
In this paper, we focus on monolithic Multimodal Large Language Models (MLLMs) that integrate visual encoding and language decoding into a single LLM. In particular, we identify that existing pre-training strategies for monolithic MLLMs often suffer from unstable optimization or catastrophic forgetting. To address this issue, our core idea is to embed a new visual parameter space into a pre-trained LLM, thereby stably learning visual knowledge from noisy data while freezing the LLM. Based on this principle, we present Mono-InternVL, a novel monolithic MLLM that seamlessly integrates a set of visual experts via a multimodal mixture-of-experts structure. Moreover, we propose an innovative pre-training strategy to maximize the visual capability of Mono-InternVL, namely Endogenous Visual Pre-training (EViP). In particular, EViP is designed as a progressive learning process for visual experts, which aims to fully exploit the visual knowledge from noisy data to high-quality data. To validate our approach, we conduct extensive experiments on 16 benchmarks. Experimental results confirm the superior performance of Mono-InternVL than existing monolithic MLLMs on 13 of 16 multimodal benchmarks, e.g., +80 points over Emu3 on OCRBench. Compared to the modular baseline, i.e., InternVL-1.5, Mono-InternVL still retains comparable multimodal performance while reducing up to 67% first token latency. Code and model will be released.