PDFactor: Learning Tri-Perspective View Policy Diffusion Field for Multi-Task Robotic Manipulation
{kind=link}
Abstract
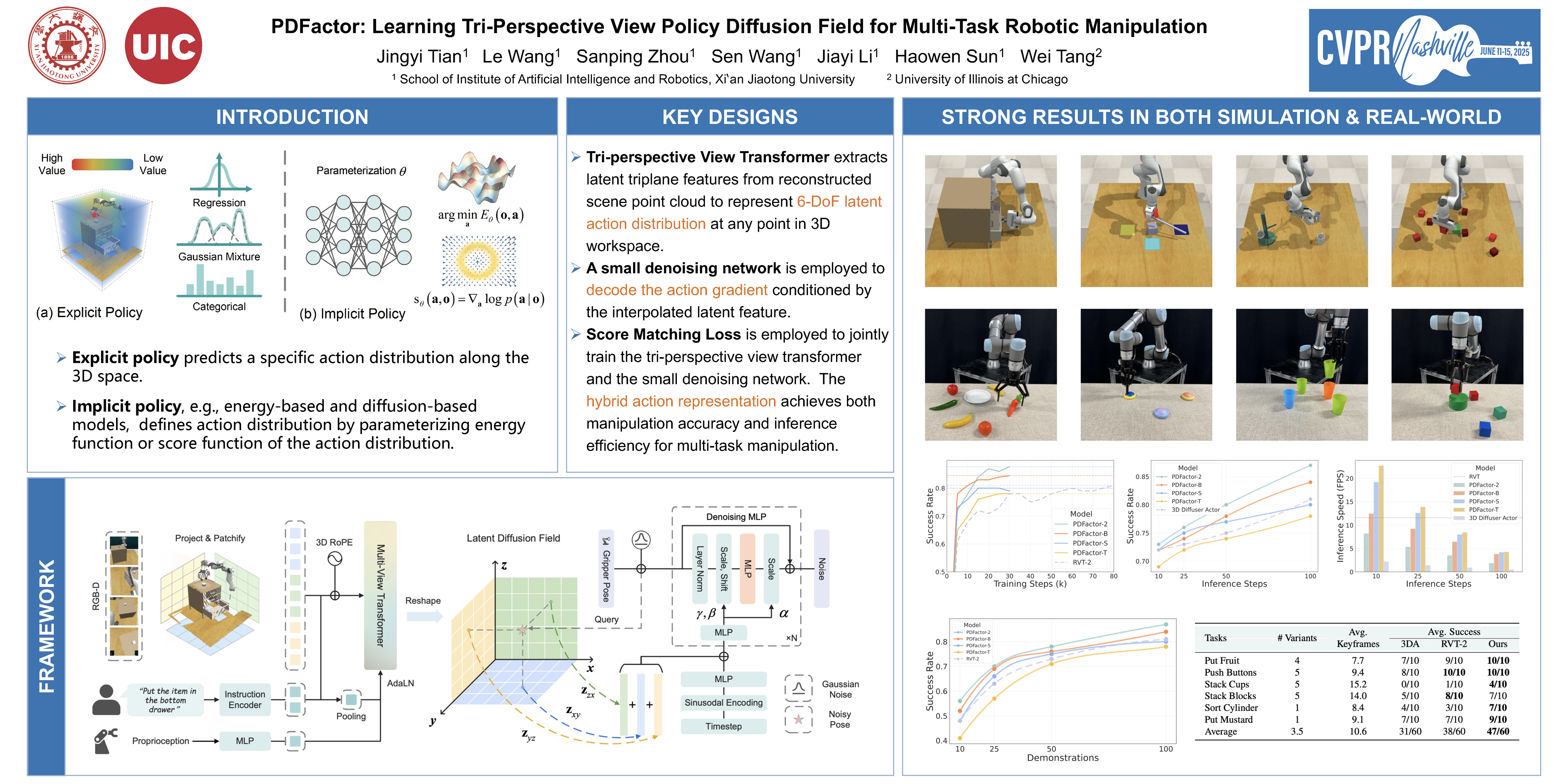
Robotic manipulation based on visual observations and natural language instructions is a long-standing challenge in robotics. Yet prevailing approaches model action distribution by adopting explicit or implicit representations, which often struggle to achieve a trade-off between accuracy and efficiency. In response, we propose PDFactor, a novel framework that models action distribution with a hybrid triplane representation. In particular, PDFactor decomposes 3D point cloud into three orthogonal feature planes and leverages a tri-perspective view transformer to produce dense cubic features as a latent diffusion field aligned with observation space representing 6-DoF action probability distribution at an arbitrary location. We employ a small denoising network conceptually as both a parameterized loss function measuring the quality of the learned latent features and an action gradient decoder to sample actions from the latent diffusion field during inference. This design enables our PDFactor to benefit from spatial awareness of explicit representation and arbitrary resolution of implicit representation, rendering it with manipulation accuracy, inference efficiency, and model scalability. Experiments demonstrate that PDFactor outperforms state-of-the-art approaches across a diverse range of manipulation tasks in RLBench simulation. Moreover, PDFactor can effectively learn multi-task policies from a limited number of human demonstrations, achieving promising accuracy in a variety of real-world manipulation tasks.