VGGT: Visual Geometry Grounded Transformer
{kind=link}
Abstract
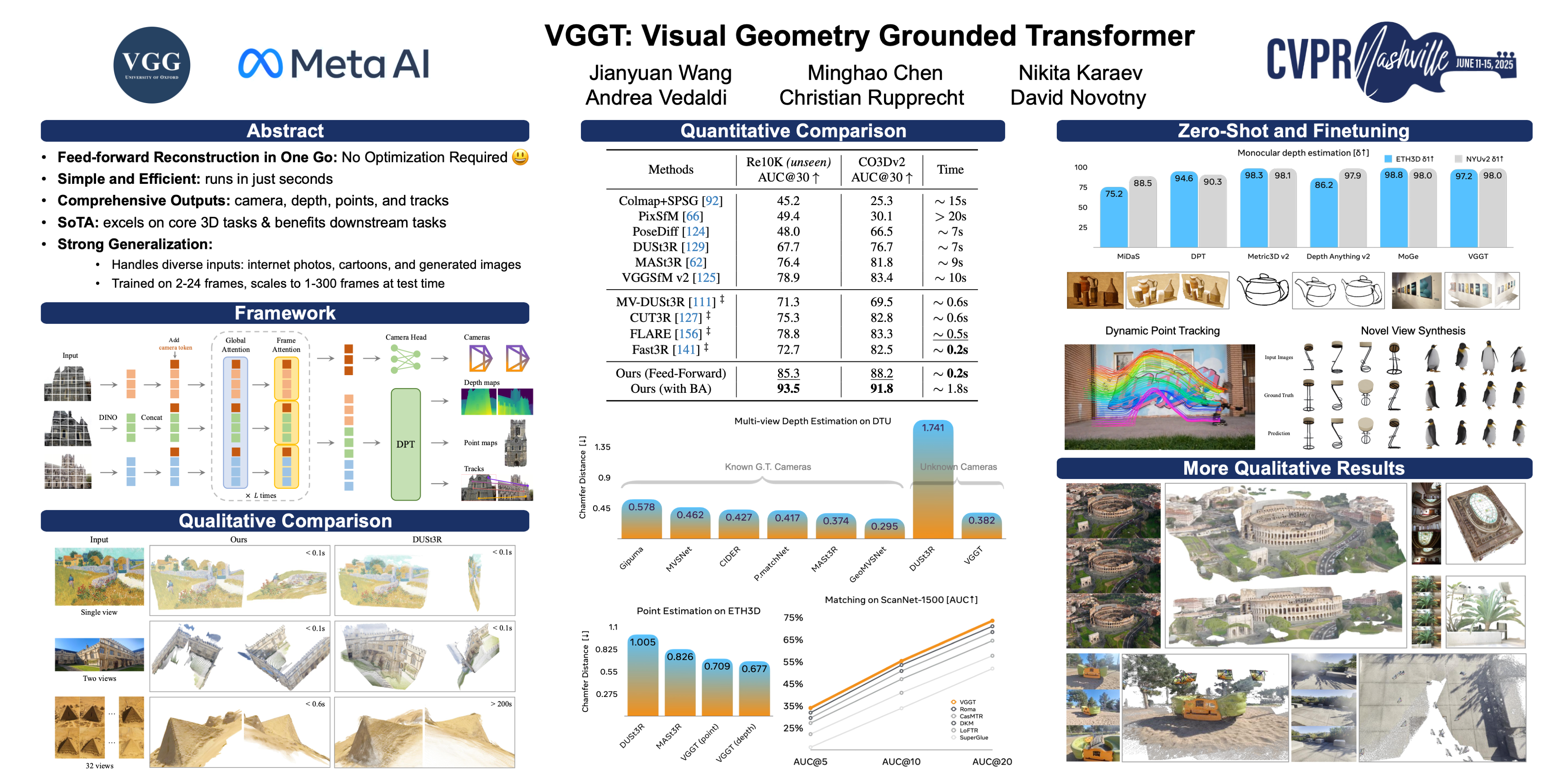
We present VGGN, a feed-forward neural network that infers directly all key 3D attributes of a scene, such as camera poses, point maps, depth maps, and 3D point tracks, from few or hundreds of its views. Unlike recent alternatives, VGGN does not need to use visual geometry optimization techniques to refine the results in post-processing, obtaining all quantities of interest directly. This approach is simple and more efficient, reconstructing hundreds of images in seconds. We train VGGN on a large number of publicly available datasets with 3D annotations and demonstrate its ability to achieve state-of-the-art results in multiple 3D tasks, including camera pose estimation, multi-view depth estimation, dense point cloud reconstruction, and 3D point tracking. This is a step forward in 3D computer vision, where models have been typically constrained to and specialized for single tasks. We extensively evaluate our method on unseen datasets to demonstrate its superior performance. We will release the code and trained model.