Embracing Collaboration Over Competition: Condensing Multiple Prompts for Visual In-Context Learning
{kind=link}
Abstract
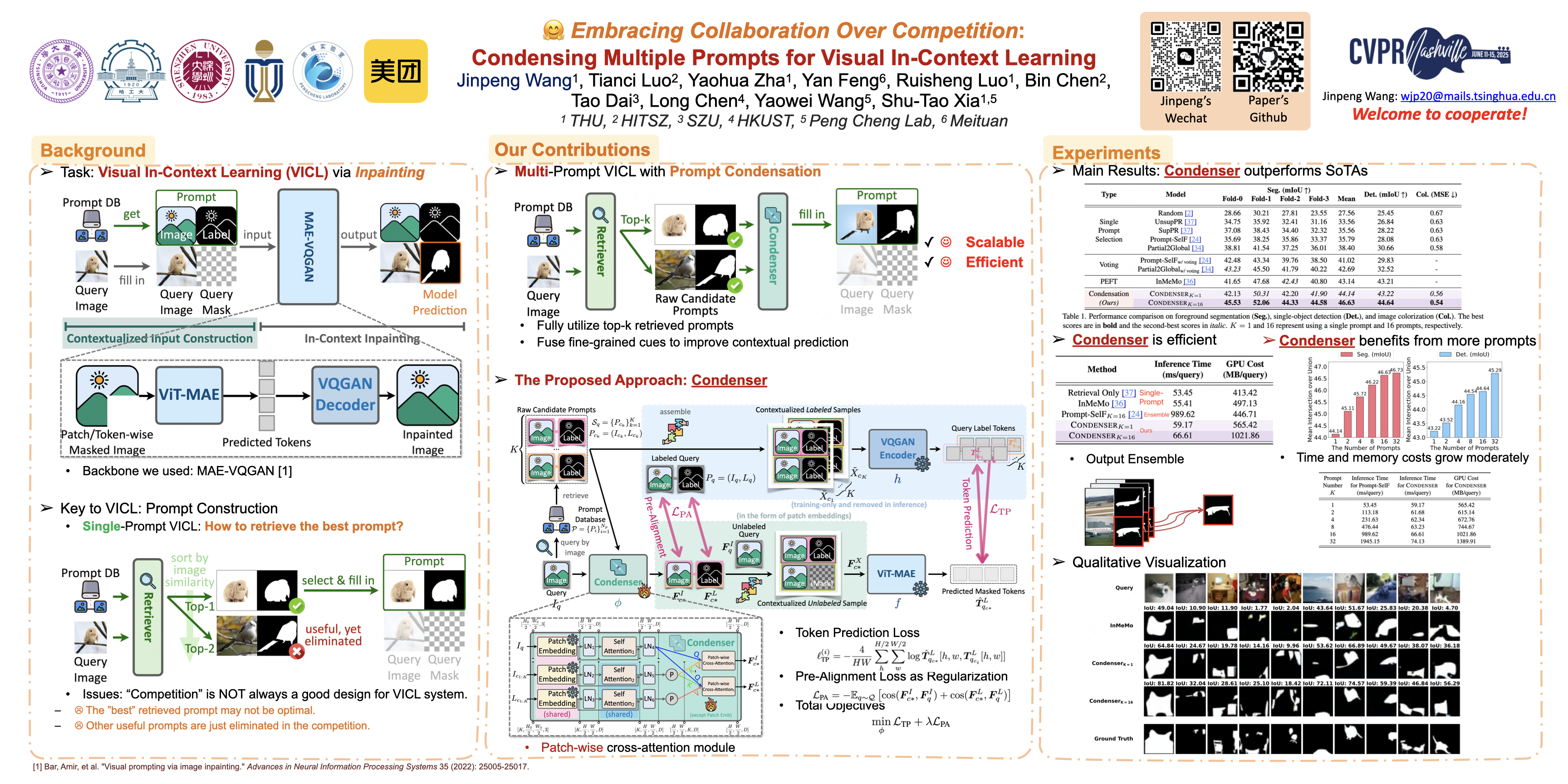
Visual In-Context Learning (VICL) enables adaptively solving vision tasks by leveraging pixel demonstrations, mimicking human-like task completion through analogy. Prompt selection is critical in VICL, but current methods assume the existence of a single "ideal" prompt in a pool of candidates, which in practice may not hold true. Multiple suitable prompts may exist, but individually they often fall short, leading to difficulties in selection and the exclusion of useful context. To address this, we propose a new perspective: prompt condensation. ather than relying on a single prompt, candidate prompts collaborate to efficiently integrate informative contexts without sacrificing resolution. We devise Condenser, a lightweight external plugin that compresses relevant fine-grained context across multiple prompts. Optimized end-to-end with the backbone and an extra pre-alignment objective, Condenser ensures stability and accurate integration of contextual cues. Experiments demonstrate Condenser outperforms state-of-the-arts across benchmark tasks, showing superior context compression, scalability with more prompts, and enhanced computational efficiency compared to ensemble methods, positioning it as a highly competitive solution for VICL. Code will be open-sourced at https://anonymous.4open.science/r/VICL-Condenser.