Anchor-Aware Similarity Cohesion in Target Frames Enables Predicting Temporal Moment Boundaries in 2D
{kind=link}
Abstract
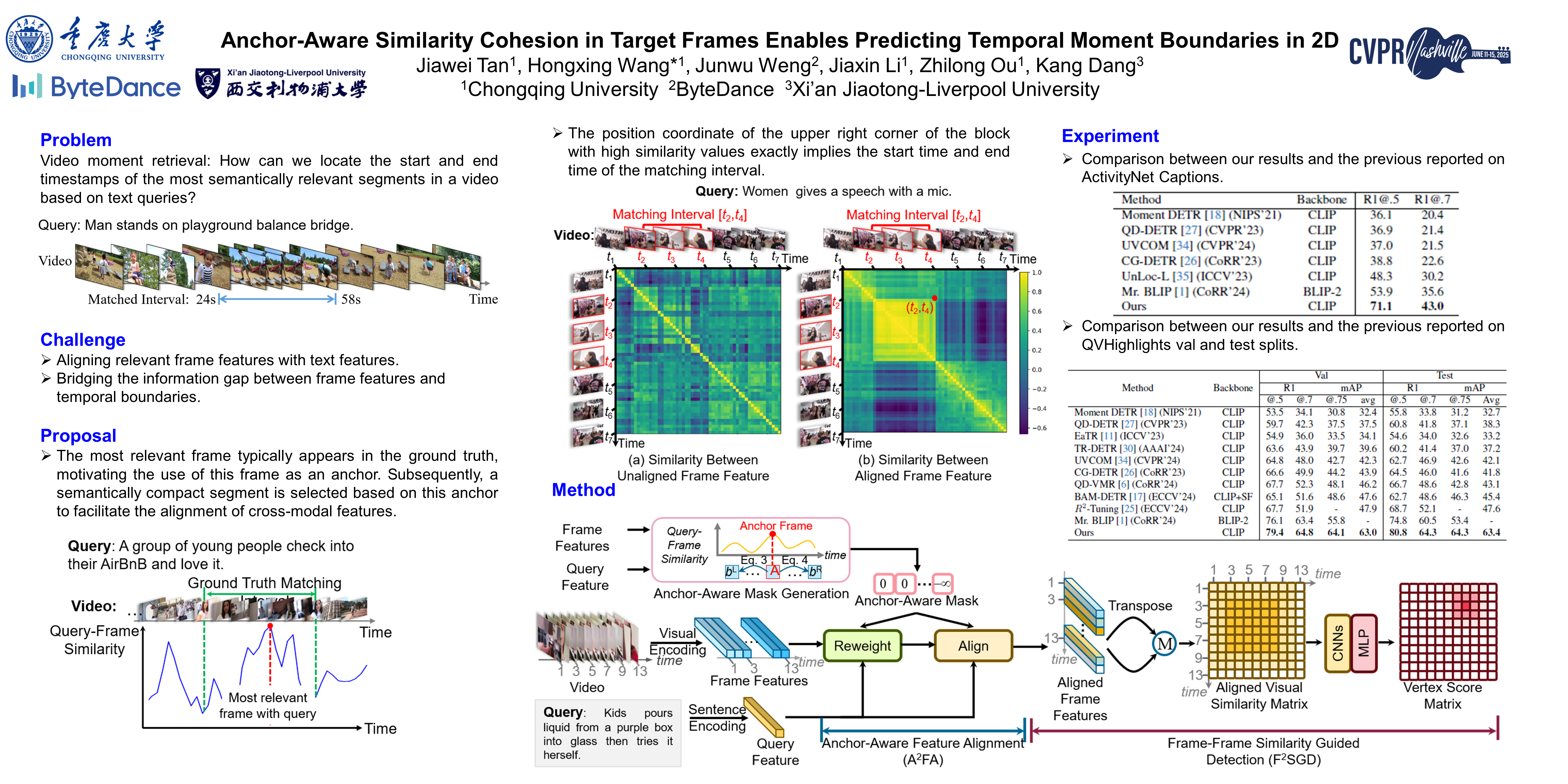
Video moment retrieval aims to locate specific moments from a video according to the query text. This task presents two main challenges: i) aligning the query and video frames at the feature level, and ii) projecting the query-aligned frame features to the start and end boundaries of the matching interval. Previous work commonly involves all frames in feature alignment, easy to cause aligning irrelevant frames with the query. Furthermore, they forcibly map visual features to interval boundaries but ignoring the information gap between them, yielding suboptimal performance. In this study, to reduce distraction from irrelevant frames, we designate an anchor frame as that with the maximum query-frame relevance measured by the established Vision-Language Model. Via similarity comparison between the anchor frame and the others, we produce a semantically compact segment around the anchor frame, which serves as a guide to align features of query and related frames. We observe that such a feature alignment will make similarity cohesive between target frames, which enables us to predict the interval boundaries by a single point detection in the 2D semantic similarity space of frames, thus well bridging the information gap between frame semantics and temporal boundaries. Experimental results across various datasets demonstrate that our approach significantly improves the alignment between queries and video frames while effectively predicting temporal moment boundaries. Especially, on QVHighlights Test and ActivityNet Captions datasets, our proposed approach achieves 3.8\% and 7.4\% respectively higher than current state-of-the-art R1@.7 performance. Codes will be released.